要获得与亚马逊 Timestream 类似的功能 LiveAnalytics,可以考虑适用于 InfluxDB 的亚马逊 Timestream。适用于 InfluxDB 的 Amazon Timestream 提供简化的数据摄取和个位数毫秒级的查询响应时间,以实现实时分析。点击此处了解更多信息。
本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
优化 Amazon Timestream 中的数据访问
您可以使用 Timestream 分区方案或数据组织技术优化 Amazon Timestream 中的数据访问模式。
Timestream 分区架构
Amazon Timestream 使用高度可扩展的分区架构,其中每个 Timestream 表可包含数百、数千甚至数百万个独立分区。高度可用的分区跟踪和索引服务可以管理分区,最大限度地减少故障的影响,并增强系统的弹性。
数据整理
Timestream 将摄取的每个数据点存储在单个分区中。将数据摄取到 Timestream 表时,Timestream 会根据数据中的时间戳、分区键及其他上下文属性自动创建分区。除按时间对数据进行分区(时间分区)以外,Timestream 还会根据选定的分区键和其他维度(空间分区)对数据进行分区。此方法旨在分发写入流量,并实现对查询数据的有效修剪。
查询见解功能为查询的修剪效率提供宝贵的见解,其中包括查询空间覆盖率和查询时间覆盖率。
QuerySpatialCoverage
该QuerySpatialCoverage指标提供了对已执行查询的空间覆盖范围的见解,以及空间修剪效率最低的表。这些信息可帮助识别分区策略中需要改进的领域,从而增强空间剪枝效果。QuerySpatialCoverage 指标的值介于 0 和 1 之间。指标的值越低,空间轴上的查询修剪效果就越理想。例如,值为 0.1 表示查询扫描 10% 的空间轴。值为 1 表示查询扫描 100% 的空间轴。
例使用查询见解分析查询的空间覆盖范围
假设您具有存储天气数据的 Timestream 数据库。假设美国不同州的气象站每小时记录一次温度。假设您选择 State 作为客户定义的分区键(CDPK),用于按州对数据进行分区。
假设您执行查询,以检索加利福尼亚州所有气象站在特定日期下午 2 点至下午 4 点之间的平均温度。以下示例显示用于此场景的查询。
SELECT AVG(temperature) FROM "weather_data"."hourly_weather" WHERE time >= '2024-10-01 14:00:00' AND time < '2024-10-01 16:00:00' AND state = 'CA';
使用查询见解功能,您可以分析查询的空间覆盖范围。假设 QuerySpatialCoverage 指标返回的值为 0.02。这表示查询仅扫描 2% 的空间轴,效率较高。在此情况下,该查询能够有效地缩减空间范围,仅检索加利福尼亚州的数据,而忽略其他州的数据。
相反,如果 QuerySpatialCoverage 指标返回的值为 0.8,则表示查询扫描 80% 的空间轴,效率较低。这可能表明需要改进分区策略以优化空间修剪。例如,您可以选择将城市或区域作为分区键,而不是州作为分区键。通过分析 QuerySpatialCoverage 指标,您可以发现优化分区策略和提升查询性能的机会。
下图显示空间修剪效果不佳的情况。
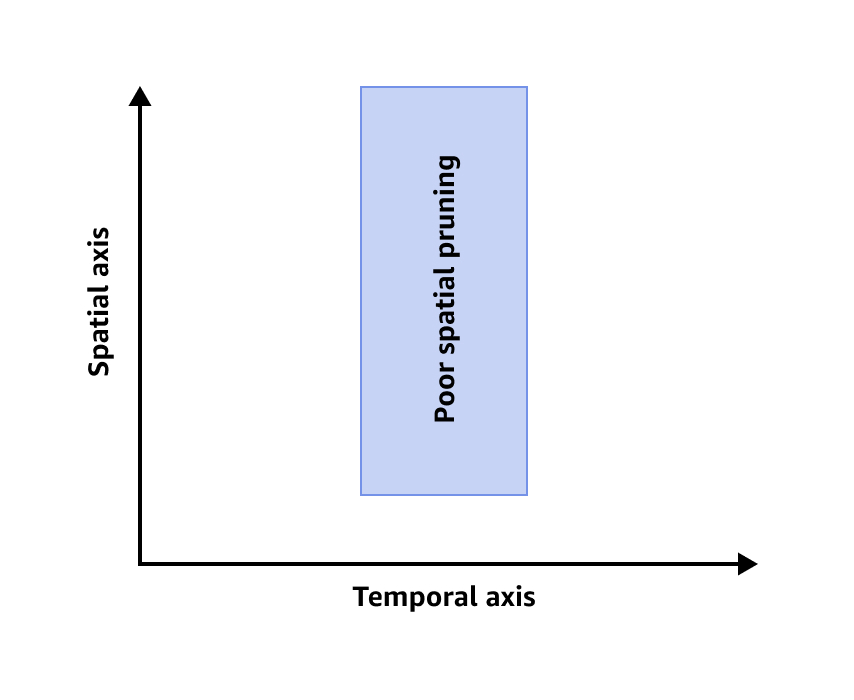
要提高空间修剪效率,可执行以下一项或两项操作:
-
在查询中添加
measure_name、默认分区密钥或使用 CDPK 谓词。 -
如果您已添加上文所述的属性,请移除这些属性或子句周围的函数,例如
LIKE。
QueryTemporalCoverage
QueryTemporalCoverage 指标提供对已执行查询所扫描时间范围的见解,包括扫描时间范围最大的表。QueryTemporalCoverage 指标的值表示以纳秒为单位的时间范围。该指标的值越低,时间范围上的查询修剪就越理想。例如,扫描表中最近几分钟数据的查询比扫描整个时间范围的查询性能更高。
例
假设您具备 Timestream 数据库,用于存储 IoT 传感器数据,该数据库每分钟采集一次位于制造工厂的设备测量值。假设您已按 device_ID 对数据进行分区。
假设您执行查询,以检索过去 30 分钟内特定设备的平均传感器读数。以下示例显示用于此场景的查询。
SELECT AVG(sensor_reading) FROM "sensor_data"."factory_1" WHERE device_id = 'DEV_123' AND time >= NOW() - INTERVAL 30 MINUTE and time < NOW();
使用查询见解功能,您可以分析查询所扫描的时间范围。假设 QueryTemporalCoverage 指标返回的值为 1800000000000 纳秒(30 分钟)。这意味着该查询仅扫描过去 30 分钟的数据,这是相对狭窄的时间范围。这是个好兆头,说明查询能够有效地修剪时间分区,仅检索请求的数据。
相反,如果 QueryTemporalCoverage 指标返回的值为 1 年(以纳秒为单位),这表示查询扫描表中一年的时间范围,效率较低。这可能表明该查询未针对时间修剪进行优化,可通过添加时间筛选器以改进查询。
下图显示时间修剪效果不佳的情况。
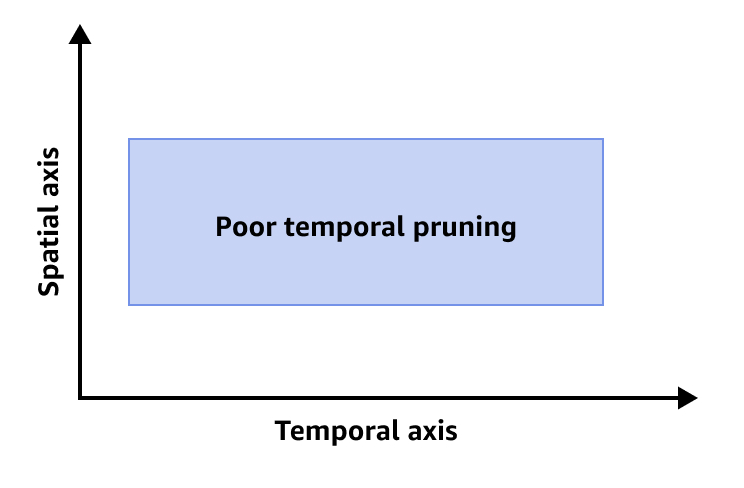
要改进时间修剪效果,建议您执行以下一项或全部操作:
-
在查询中添加缺失的时间谓词,并确保这些时间谓词能够对所需时间窗口进行修剪。
-
移除时间谓词周围的函数,例如
MAX()。 -
向所有子查询添加时间谓词。如果子查询涉及连接大型表或执行复杂操作,这一点就显得尤为重要。