要获得与亚马逊 Timestream 类似的功能 LiveAnalytics,可以考虑适用于 InfluxDB 的亚马逊 Timestream。适用于 InfluxDB 的 Amazon Timestream 提供简化的数据摄取和个位数毫秒级的查询响应时间,以实现实时分析。点击此处了解更多信息。
本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
通过在控制面板之间共享计划查询来优化成本
在此示例中,我们将看到这样的场景:多个控制面板显示相似信息的变体(查找高 CPU 主机和高 CPU 利用率的实例集占比),以及如何使用相同的计划查询来预先计算结果,然后使用这些结果填充多个面板。这种重复使用进一步优化成本,即无需针对每个面板使用不同的计划查询,只需使用所有者面板即可。
包含原始数据的控制面板
每个微服务的每个区域的 CPU 利用率
第一个面板计算区域、单元格、筒仓、可用区和微服务内,给定部署平均 CPU 利用率低于或高于上述 CPU 利用率阈值的实例。然后,会对高利用率主机占比最高的区域和微服务进行排序。这有助于识别特定部署中服务器的运行温度,随后深入分析以更好地理解问题所在。
该面板的查询展示了 Timestream for LiveAnalytics 的 SQL 支持的灵活性,可以利用公用表表达式、窗口函数、联接等执行复杂的分析任务。

查询:
WITH microservice_cell_avg AS ( SELECT region, cell, silo, availability_zone, microservice_name, AVG(cpu_user) AS microservice_avg_metric FROM "raw_data"."devops" WHERE time BETWEEN from_milliseconds(1636526593876) AND from_milliseconds(1636612993876) AND measure_name = 'metrics' GROUP BY region, cell, silo, availability_zone, microservice_name ), instance_avg AS ( SELECT region, cell, silo, availability_zone, microservice_name, instance_name, AVG(cpu_user) AS instance_avg_metric FROM "raw_data"."devops" WHERE time BETWEEN from_milliseconds(1636526593876) AND from_milliseconds(1636612993876) AND measure_name = 'metrics' GROUP BY region, cell, silo, availability_zone, microservice_name, instance_name ), instances_above_threshold AS ( SELECT i.*, CASE WHEN i.instance_avg_metric > (1 + 0.2) * m.microservice_avg_metric THEN 1 ELSE 0 END AS high_utilization, CASE WHEN i.instance_avg_metric < (1 - 0.2) * m.microservice_avg_metric THEN 1 ELSE 0 END AS low_utilization FROM instance_avg i INNER JOIN microservice_cell_avg m ON i.region = m.region AND i.cell = m.cell AND i.silo = m.silo AND i.availability_zone = m.availability_zone AND m.microservice_name = i.microservice_name ), per_deployment_high AS ( SELECT region, microservice_name, COUNT(*) AS num_hosts, SUM(high_utilization) AS high_utilization_hosts, SUM(low_utilization) AS low_utilization_hosts, ROUND(SUM(high_utilization) * 100.0 / COUNT(*), 0) AS percent_high_utilization_hosts, ROUND(SUM(low_utilization) * 100.0 / COUNT(*), 0) AS percent_low_utilization_hosts FROM instances_above_threshold GROUP BY region, microservice_name ), per_region_ranked AS ( SELECT *, DENSE_RANK() OVER (PARTITION BY region ORDER BY percent_high_utilization_hosts DESC, high_utilization_hosts DESC) AS rank FROM per_deployment_high ) SELECT * FROM per_region_ranked WHERE rank <= 2 ORDER BY percent_high_utilization_hosts desc, rank asc
深入研究微服务以查找热点
下一个控制面板可让您深入分析某个微服务,查明该微服务在特定区域、单元格和筒仓中,其实例集中有多少比例的微服务正处于较高 CPU 利用率状态。例如,在实例集范围控制面板中,您会发现微服务 demeter 位列前几名,因此在此控制面板中,您需要深入分析该微服务。
此控制面板使用变量来选择要深入研究的微服务,变量的值使用该维度的唯一值进行填充。选择微服务后,控制面板的其余部分将自动刷新。
如下所示,第一个面板绘制一段时间内部署(微服务的区域、单元格和筒仓)中主机的百分比,以及用于绘制控制面板的相应查询。该图表本身标识特定部署环境,其中存在较高比例的主机处于高 CPU 使用率状态。

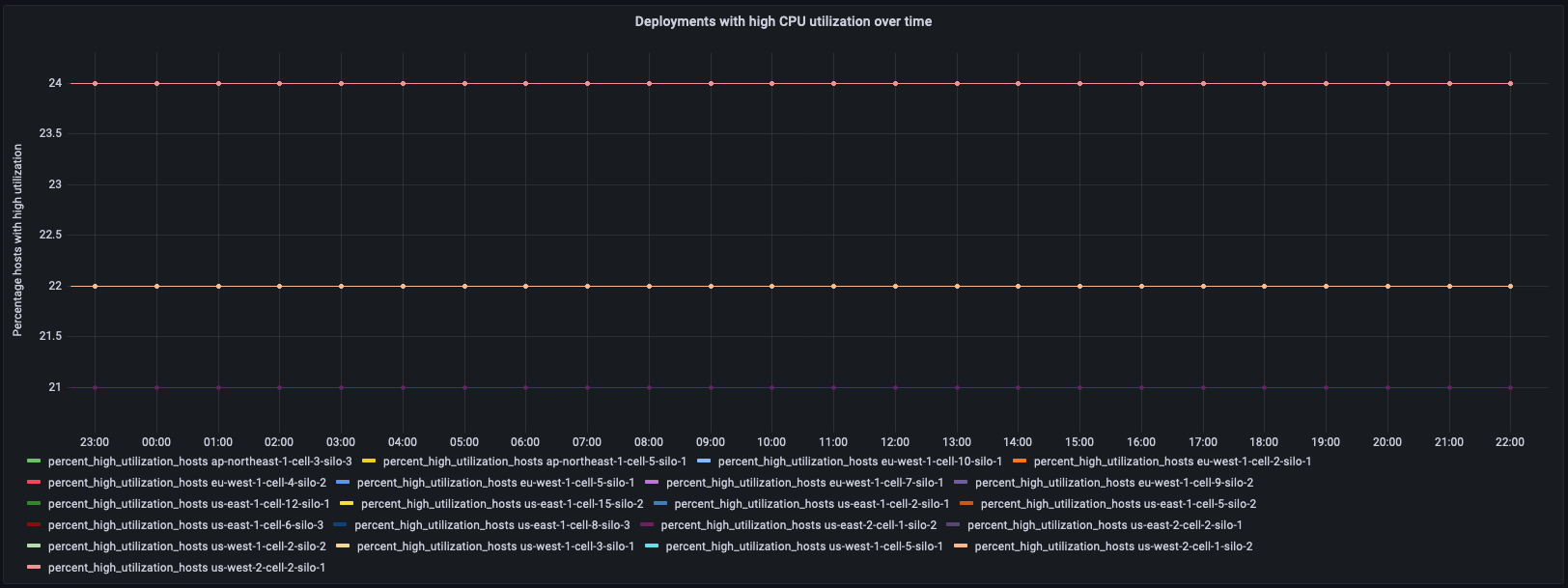
查询:
WITH microservice_cell_avg AS ( SELECT region, cell, silo, availability_zone, microservice_name, bin(time, 1h) as hour, AVG(cpu_user) AS microservice_avg_metric FROM "raw_data"."devops" WHERE time BETWEEN from_milliseconds(1636526898831) AND from_milliseconds(1636613298831) AND measure_name = 'metrics' AND microservice_name = 'demeter' GROUP BY region, cell, silo, availability_zone, microservice_name, bin(time, 1h) ), instance_avg AS ( SELECT region, cell, silo, availability_zone, microservice_name, instance_name, bin(time, 1h) as hour, AVG(cpu_user) AS instance_avg_metric FROM "raw_data"."devops" WHERE time BETWEEN from_milliseconds(1636526898831) AND from_milliseconds(1636613298831) AND measure_name = 'metrics' AND microservice_name = 'demeter' GROUP BY region, cell, silo, availability_zone, microservice_name, instance_name, bin(time, 1h) ), instances_above_threshold AS ( SELECT i.*, CASE WHEN i.instance_avg_metric > (1 + 0.2) * m.microservice_avg_metric THEN 1 ELSE 0 END AS high_utilization FROM instance_avg i INNER JOIN microservice_cell_avg m ON i.region = m.region AND i.cell = m.cell AND i.silo = m.silo AND i.availability_zone = m.availability_zone AND m.microservice_name = i.microservice_name AND m.hour = i.hour ), high_utilization_percent AS ( SELECT region, cell, silo, microservice_name, hour, COUNT(*) AS num_hosts, SUM(high_utilization) AS high_utilization_hosts, ROUND(SUM(high_utilization) * 100.0 / COUNT(*), 0) AS percent_high_utilization_hosts FROM instances_above_threshold GROUP BY region, cell, silo, microservice_name, hour ), high_utilization_ranked AS ( SELECT region, cell, silo, microservice_name, DENSE_RANK() OVER (PARTITION BY region ORDER BY AVG(percent_high_utilization_hosts) desc, AVG(high_utilization_hosts) desc) AS rank FROM high_utilization_percent GROUP BY region, cell, silo, microservice_name ) SELECT hup.silo, CREATE_TIME_SERIES(hour, hup.percent_high_utilization_hosts) AS percent_high_utilization_hosts FROM high_utilization_percent hup INNER JOIN high_utilization_ranked hur ON hup.region = hur.region AND hup.cell = hur.cell AND hup.silo = hur.silo AND hup.microservice_name = hur.microservice_name WHERE rank <= 2 GROUP BY hup.region, hup.cell, hup.silo ORDER BY hup.silo
转换为单个计划查询,以实现重复使用
需要注意的是,在两个控制面板的不同面板中,都进行了类似的计算。您可以为每个面板定义单独的计划查询。在此处,您将了解如何通过定义计划查询来进一步优化成本,该查询的结果可用于呈现所有三个面板。
以下查询捕获用于所有不同面板的聚合。在此计划查询的定义中,您需要注意一些重要事项。
-
计划查询支持的 SQL 操作空间兼具灵活性与强大功能,您可在此使用通用表表达式、连接操作、case语句等功能。
-
您可以通过单个计划查询,以比特定控制面板所需更精细的粒度计算统计数据,并涵盖控制面板可能用于不同变量的所有值。例如,您将发现聚合是跨区域、单元格、筒仓和微服务计算得出。因此,您可以将这些组合起来创建区域级聚合(即区域)和微服务级聚合。同样,同一查询会计算所有区域、单元格、筒仓和微服务的聚合。该查询允许您对这些列应用筛选条件,以获取值子集的聚合。例如,您可以计算任意区域(如 us-east-1)或任意微服务(如demeter)的聚合,或深入研究区域、单元格、筒仓和微服务内的特定部署。此方法可进一步优化维护预先计算聚合的成本。
WITH microservice_cell_avg AS ( SELECT region, cell, silo, availability_zone, microservice_name, bin(time, 1h) as hour, AVG(cpu_user) AS microservice_avg_metric FROM raw_data.devops WHERE time BETWEEN bin(@scheduled_runtime, 1h) - 1h AND bin(@scheduled_runtime, 1h) + 1h AND measure_name = 'metrics' GROUP BY region, cell, silo, availability_zone, microservice_name, bin(time, 1h) ), instance_avg AS ( SELECT region, cell, silo, availability_zone, microservice_name, instance_name, bin(time, 1h) as hour, AVG(cpu_user) AS instance_avg_metric FROM raw_data.devops WHERE time BETWEEN bin(@scheduled_runtime, 1h) - 1h AND bin(@scheduled_runtime, 1h) + 1h AND measure_name = 'metrics' GROUP BY region, cell, silo, availability_zone, microservice_name, instance_name, bin(time, 1h) ), instances_above_threshold AS ( SELECT i.*, CASE WHEN i.instance_avg_metric > (1 + 0.2) * m.microservice_avg_metric THEN 1 ELSE 0 END AS high_utilization, CASE WHEN i.instance_avg_metric < (1 - 0.2) * m.microservice_avg_metric THEN 1 ELSE 0 END AS low_utilization FROM instance_avg i INNER JOIN microservice_cell_avg m ON i.region = m.region AND i.cell = m.cell AND i.silo = m.silo AND i.availability_zone = m.availability_zone AND m.microservice_name = i.microservice_name AND m.hour = i.hour ) SELECT region, cell, silo, microservice_name, hour, COUNT(*) AS num_hosts, SUM(high_utilization) AS high_utilization_hosts, SUM(low_utilization) AS low_utilization_hosts FROM instances_above_threshold GROUP BY region, cell, silo, microservice_name, hour
以下是针对先前查询的计划查询定义。该计划表达式配置为每 30 分钟刷新一次,最多可回溯一小时的数据。同样采用 bin(@scheduled_runtime, 1h) 构造以获取完整小时内的事件。根据应用程序的刷新要求,您可以配置其刷新频率的高低。通过使用 WHERE time BETWEEN bin(@scheduled_runtime, 1h) - 1h AND bin(@scheduled_runtime, 1h) + 1h 条件,即使每 15 分钟刷新一次,也能确保获取当前小时和前一小时的完整数据。
稍后,您将了解这三个面板如何利用写入 deployment_cpu_stats_per_hr 表中的聚合数据,以可视化与面板相关的指标。
{ "Name": "MultiPT30mHighCpuDeploymentsPerHr", "QueryString": "WITH microservice_cell_avg AS ( SELECT region, cell, silo, availability_zone, microservice_name, bin(time, 1h) as hour, AVG(cpu_user) AS microservice_avg_metric FROM raw_data.devops WHERE time BETWEEN bin(@scheduled_runtime, 1h) - 1h AND bin(@scheduled_runtime, 1h) + 1h AND measure_name = 'metrics' GROUP BY region, cell, silo, availability_zone, microservice_name, bin(time, 1h) ), instance_avg AS ( SELECT region, cell, silo, availability_zone, microservice_name, instance_name, bin(time, 1h) as hour, AVG(cpu_user) AS instance_avg_metric FROM raw_data.devops WHERE time BETWEEN bin(@scheduled_runtime, 1h) - 1h AND bin(@scheduled_runtime, 1h) + 1h AND measure_name = 'metrics' GROUP BY region, cell, silo, availability_zone, microservice_name, instance_name, bin(time, 1h) ), instances_above_threshold AS ( SELECT i.*, CASE WHEN i.instance_avg_metric > (1 + 0.2) * m.microservice_avg_metric THEN 1 ELSE 0 END AS high_utilization, CASE WHEN i.instance_avg_metric < (1 - 0.2) * m.microservice_avg_metric THEN 1 ELSE 0 END AS low_utilization FROM instance_avg i INNER JOIN microservice_cell_avg m ON i.region = m.region AND i.cell = m.cell AND i.silo = m.silo AND i.availability_zone = m.availability_zone AND m.microservice_name = i.microservice_name AND m.hour = i.hour ) SELECT region, cell, silo, microservice_name, hour, COUNT(*) AS num_hosts, SUM(high_utilization) AS high_utilization_hosts, SUM(low_utilization) AS low_utilization_hosts FROM instances_above_threshold GROUP BY region, cell, silo, microservice_name, hour", "ScheduleConfiguration": { "ScheduleExpression": "cron(0/30 * * * ? *)" }, "NotificationConfiguration": { "SnsConfiguration": { "TopicArn": "******" } }, "TargetConfiguration": { "TimestreamConfiguration": { "DatabaseName": "derived", "TableName": "deployment_cpu_stats_per_hr", "TimeColumn": "hour", "DimensionMappings": [ { "Name": "region", "DimensionValueType": "VARCHAR" }, { "Name": "cell", "DimensionValueType": "VARCHAR" }, { "Name": "silo", "DimensionValueType": "VARCHAR" }, { "Name": "microservice_name", "DimensionValueType": "VARCHAR" } ], "MultiMeasureMappings": { "TargetMultiMeasureName": "cpu_user", "MultiMeasureAttributeMappings": [ { "SourceColumn": "num_hosts", "MeasureValueType": "BIGINT" }, { "SourceColumn": "high_utilization_hosts", "MeasureValueType": "BIGINT" }, { "SourceColumn": "low_utilization_hosts", "MeasureValueType": "BIGINT" } ] } } }, "ErrorReportConfiguration": { "S3Configuration" : { "BucketName" : "******", "ObjectKeyPrefix": "errors", "EncryptionOption": "SSE_S3" } }, "ScheduledQueryExecutionRoleArn": "******" }
基于预先计算结果的控制面板
CPU 利用率高的主机
对于高利用率主机,您将了解不同面板如何使用 deployment_cpu_stats_per_hr 中的数据,以计算面板所需的不同聚合。例如,该面板提供区域级信息,因此会报告按区域和微服务分组的聚合,而不会筛选任何区域或微服务。
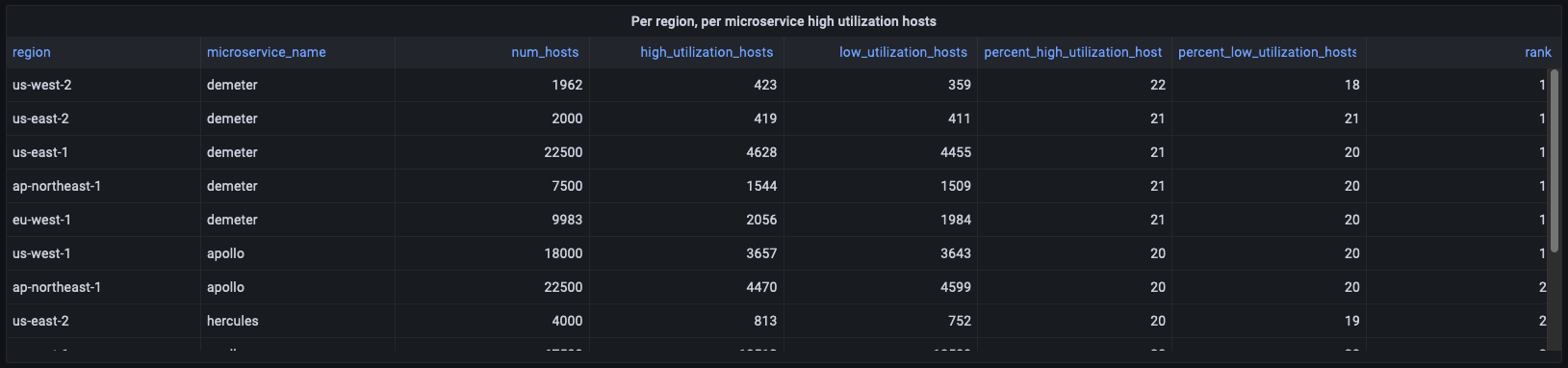
WITH per_deployment_hosts AS ( SELECT region, cell, silo, microservice_name, AVG(num_hosts) AS num_hosts, AVG(high_utilization_hosts) AS high_utilization_hosts, AVG(low_utilization_hosts) AS low_utilization_hosts FROM "derived"."deployment_cpu_stats_per_hr" WHERE time BETWEEN from_milliseconds(1636567785437) AND from_milliseconds(1636654185437) AND measure_name = 'cpu_user' GROUP BY region, cell, silo, microservice_name ), per_deployment_high AS ( SELECT region, microservice_name, SUM(num_hosts) AS num_hosts, ROUND(SUM(high_utilization_hosts), 0) AS high_utilization_hosts, ROUND(SUM(low_utilization_hosts),0) AS low_utilization_hosts, ROUND(SUM(high_utilization_hosts) * 100.0 / SUM(num_hosts)) AS percent_high_utilization_hosts, ROUND(SUM(low_utilization_hosts) * 100.0 / SUM(num_hosts)) AS percent_low_utilization_hosts FROM per_deployment_hosts GROUP BY region, microservice_name ), per_region_ranked AS ( SELECT *, DENSE_RANK() OVER (PARTITION BY region ORDER BY percent_high_utilization_hosts DESC, high_utilization_hosts DESC) AS rank FROM per_deployment_high ) SELECT * FROM per_region_ranked WHERE rank <= 2 ORDER BY percent_high_utilization_hosts desc, rank asc
深入研究微服务,查找高 CPU 利用率的部署
下一示例同样使用 deployment_cpu_stats_per_hr 派生表,但对特定微服务(在本例中为 demeter,因为该微服务在聚合控制面板中报告为高利用率主机)应用筛选条件。此面板跟踪高 CPU 利用率主机随时间推移的百分比变化。
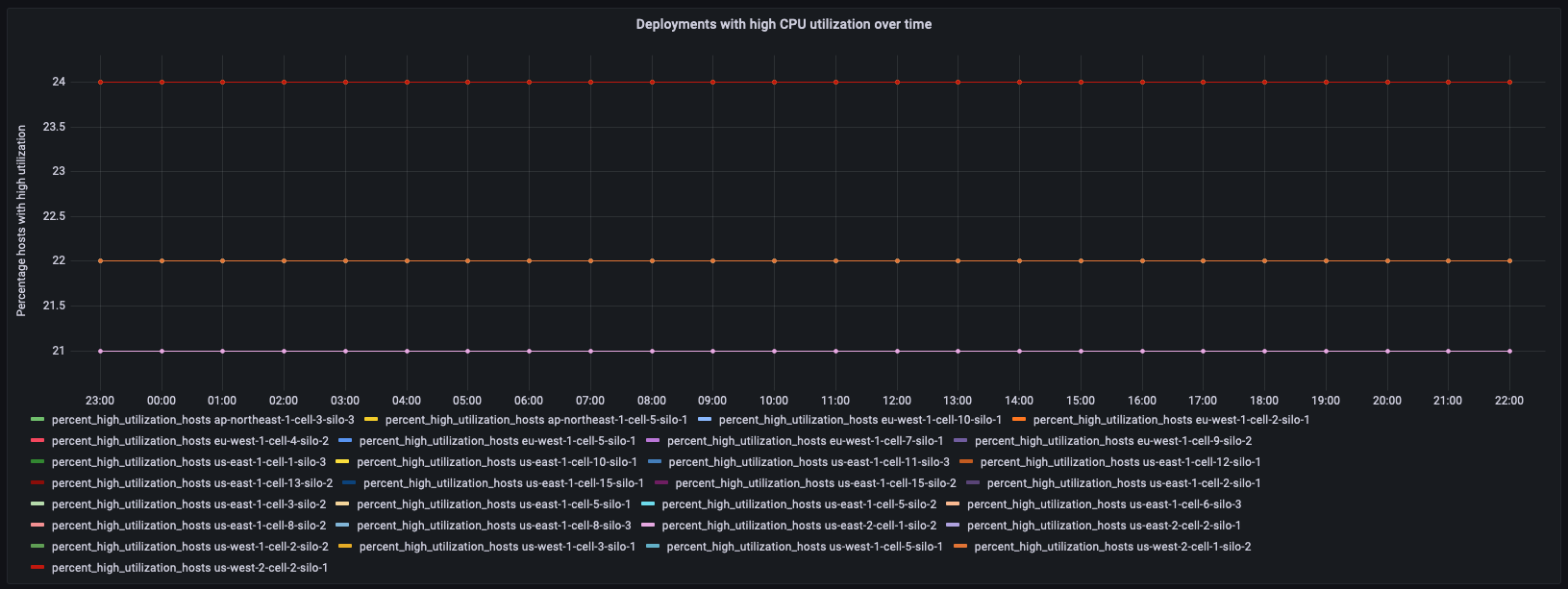
WITH high_utilization_percent AS ( SELECT region, cell, silo, microservice_name, bin(time, 1h) AS hour, MAX(num_hosts) AS num_hosts, MAX(high_utilization_hosts) AS high_utilization_hosts, ROUND(MAX(high_utilization_hosts) * 100.0 / MAX(num_hosts)) AS percent_high_utilization_hosts FROM "derived"."deployment_cpu_stats_per_hr" WHERE time BETWEEN from_milliseconds(1636525800000) AND from_milliseconds(1636612200000) AND measure_name = 'cpu_user' AND microservice_name = 'demeter' GROUP BY region, cell, silo, microservice_name, bin(time, 1h) ), high_utilization_ranked AS ( SELECT region, cell, silo, microservice_name, DENSE_RANK() OVER (PARTITION BY region ORDER BY AVG(percent_high_utilization_hosts) desc, AVG(high_utilization_hosts) desc) AS rank FROM high_utilization_percent GROUP BY region, cell, silo, microservice_name ) SELECT hup.silo, CREATE_TIME_SERIES(hour, hup.percent_high_utilization_hosts) AS percent_high_utilization_hosts FROM high_utilization_percent hup INNER JOIN high_utilization_ranked hur ON hup.region = hur.region AND hup.cell = hur.cell AND hup.silo = hur.silo AND hup.microservice_name = hur.microservice_name WHERE rank <= 2 GROUP BY hup.region, hup.cell, hup.silo ORDER BY hup.silo