要获得与亚马逊 Timestream 类似的功能 LiveAnalytics,可以考虑适用于 InfluxDB 的亚马逊 Timestream。适用于 InfluxDB 的 Amazon Timestream 提供简化的数据摄取和个位数毫秒级的查询响应时间,以实现实时分析。点击此处了解更多信息。
本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
简单的实例集级别聚合
第一个示例使用计算实例集级别聚合的简单示例,介绍处理计划查询时的一些基本概念。使用此示例,您将了解以下内容。
-
如何将用于获取聚合统计数据的控制面板查询映射到计划查询。
-
Timestream 如何 LiveAnalytics 管理计划查询的不同实例的执行。
-
如何让不同的计划查询实例在时间范围内重叠,以及如何确保目标表中数据的正确性,以确保使用计划查询结果的控制面板所显示的结果,与基于原始数据计算的相同聚合结果相匹配。
-
如何为计划查询设置时间范围和刷新频率。
-
如何自助跟踪计划查询的结果,以便对其进行调优,使查询实例的执行延迟控制在控制面板刷新可接受的延迟范围内。
从源表中聚合
在此示例中,您正在跟踪给定区域内服务器每分钟发出的指标数量。下图展示 us-east-1 区域时间序列的示例。
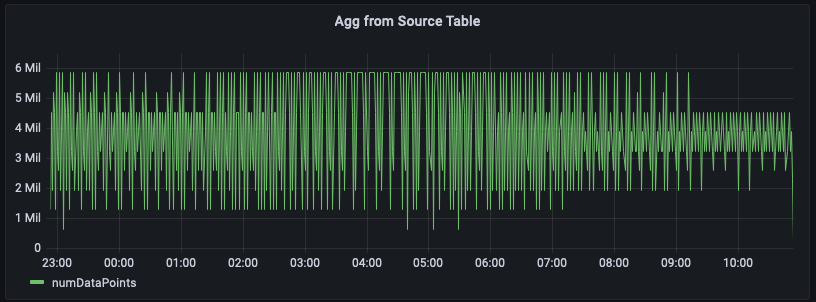
以下是根据原始数据计算此聚合的示例查询。该查询筛选区域 us-east-1 的行,然后通过计算 20 个指标(如果 measure_name 为 metrics)或 5 个事件(如果 measure_name 是 events)的每分钟总和而得出结果。在此示例中,图表显示每分钟发出的指标数量在 150 万至 600 万之间。当绘制数小时(本图中为过去 12 小时)的该时间序列时,此原始数据查询需分析数亿行数据。
WITH grouped_data AS ( SELECT region, bin(time, 1m) as minute, SUM(CASE WHEN measure_name = 'metrics' THEN 20 ELSE 5 END) as numDataPoints FROM "raw_data"."devops" WHERE time BETWEEN from_milliseconds(1636699996445) AND from_milliseconds(1636743196445) AND region = 'us-east-1' GROUP BY region, measure_name, bin(time, 1m) ) SELECT minute, SUM(numDataPoints) AS numDataPoints FROM grouped_data GROUP BY minute ORDER BY 1 desc, 2 desc
预先计算聚合的计划查询
如果想通过扫描更少的数据以优化控制面板,进而加快加载速度并降低成本,则可以使用计划查询预先计算这些聚合。Timestream 中的计划查询 LiveAnalytics 允许您在另一个 Timestream 表中实现这些预计算,随后您可以将其用于仪 LiveAnalytics 表板。
创建计划查询的第一步是确定要预先计算的查询。请注意,上述控制面板针对区域 us-east-1 进行绘制。然而,其他用户可能希望为不同区域(例如 us-west-2 或 eu-west-1)获取相同的聚合数据。为避免为每个此类查询创建定时查询,您可以预先计算每个区域的聚合,并在表的另一个 Timestream 中实现每个区域的聚合。 LiveAnalytics
以下查询提供相应的预计算示例。如您所见,这与原始数据查询中使用的常见表表达式 grouped_data 相似,但存在两点差异:1) 未使用区域谓词,因此可通过单次查询为所有区域预先计算;2) 使用带特殊参数 @scheduled_runtime 的参数化时间谓词,该参数将在下文详细说明。
SELECT region, bin(time, 1m) as minute, SUM(CASE WHEN measure_name = 'metrics' THEN 20 ELSE 5 END) as numDataPoints FROM raw_data.devops WHERE time BETWEEN @scheduled_runtime - 10m AND @scheduled_runtime + 1m GROUP BY bin(time, 1m), region
上述查询可通过以下规范转换为计划查询。为计划查询分配一个名称,这是用户友好的助记词。然后,它包括 QueryString、a ScheduleConfiguration,这是一个 cron 表达式。它指定 TargetConfiguration 了将查询结果映射到 Timestream 中的目标表的。 LiveAnalytics最后,它指定了许多其他配置,例如 NotificationConfiguration,在查询的各个执行中发送通知, ErrorReportConfiguration 在查询遇到任何错误时编写报告 ScheduledQueryExecutionRoleArn,以及用于对计划查询执行操作的角色。
{ "Name": "MultiPT5mPerMinutePerRegionMeasureCount", "QueryString": "SELECT region, bin(time, 1m) as minute, SUM(CASE WHEN measure_name = 'metrics' THEN 20 ELSE 5 END) as numDataPoints FROM raw_data.devops WHERE time BETWEEN @scheduled_runtime - 10m AND @scheduled_runtime + 1m GROUP BY bin(time, 1m), region", "ScheduleConfiguration": { "ScheduleExpression": "cron(0/5 * * * ? *)" }, "NotificationConfiguration": { "SnsConfiguration": { "TopicArn": "******" } }, "TargetConfiguration": { "TimestreamConfiguration": { "DatabaseName": "derived", "TableName": "per_minute_aggs_pt5m", "TimeColumn": "minute", "DimensionMappings": [ { "Name": "region", "DimensionValueType": "VARCHAR" } ], "MultiMeasureMappings": { "TargetMultiMeasureName": "numDataPoints", "MultiMeasureAttributeMappings": [ { "SourceColumn": "numDataPoints", "MeasureValueType": "BIGINT" } ] } } }, "ErrorReportConfiguration": { "S3Configuration" : { "BucketName" : "******", "ObjectKeyPrefix": "errors", "EncryptionOption": "SSE_S3" } }, "ScheduledQueryExecutionRoleArn": "******" }
在示例中, ScheduleExpression cron (0/5 * * *? *) 表示查询每 5 分钟在每天每小时的 5、10、15、... 分钟执行一次。这些时间戳表示该查询的特定实例被触发的时间点,正是查询中使用的 @scheduled_runtime 参数所对应的值。例如,考虑在 2021-12-01 00:00:00 执行此计划查询的实例。对于此实例,@scheduled_runtime 参数在调用查询时初始化的时间戳为 2021-12-01 00:00:00。因此,此特定实例将在时间戳 2021-12-01 00:00:00 执行,并计算时间范围 2021-11-30 23:50:00 至 2021-12-01 00:01:00 的每分钟聚合数据。同样,此查询的下一个实例将在时间戳 2021-12-01 00:05:00 触发,此时查询将计算 2021-11-30 23:55:00 至 2021-12-01 00:06:00 时间段内的每分钟聚合数据。因此,@scheduled_runtime 参数提供计划查询,用于根据查询的调用时间,预先计算配置时间范围内的聚合结果。
请注意,两个连续的查询实例在时间范围内存在重叠。这是您可以根据自身需求进行控制的事项。在此情况下,这种重叠使得这些查询能够基于任何延迟到达的数据(本例中最长可达 5 分钟)更新聚合结果。为了确保物化查询的正确性,Timestream for LiveAnalytics 确保只有在 2021-12-01 00:00:00 的查询完成之后,才会执行 2021-12-01 00:05:00 的查询,并且如果生成了较新的值,则后一个查询的结果可以使用更新任何先前已实现的聚合。例如,如果某些时间戳为 2021-11-30 23:59:00 的数据是在执行 2021-12-01 00:00:00 的查询之后,但在 2021-12-01 00:05:00 的查询之前到达,则在 2021-12-01 00:05:00 执行时将重新计算 2021-11-30 23:59:00 的聚合,导致新计算值更新之前的聚合。您可以依靠这些计划查询的语义,在预计算的更新速度与延迟到达数据的优雅处理之间取得平衡。下文将进一步探讨如何权衡刷新频率与数据时效性,以及如何处理延迟更长的数据聚合更新问题,特别是当计划计算的数据源发生更新时,这些更新可能需要重新计算聚合结果。
每个计划计算都有一个通知配置,其中 Timestream for LiveAnalytics 会发送每次执行计划配置的通知。您可以配置 SNS 主题,用于接收每次调用的通知。除特定实例的成功或失败状态以外,还包含一些统计信息,例如执行此计算所花费的时间、计算扫描的字节数以及计算写入其目标表的字节数。您可以利用这些统计数据进一步优化查询、调整计划配置,或跟踪计划查询的支出情况。值得注意的一点是实例的执行时间。在此示例中,计划计算配置为每 5 分钟执行一次。执行时间将决定预计算结果的可用延迟,这也将决定您在控制面板中使用预计算数据时出现的滞后现象。此外,如果这种延迟持续高于刷新间隔(例如,当计算任务配置为每 5 分钟刷新一次时,其执行时间超过 5 分钟),则必须优化计算任务以加快运行速度,从而避免控制面板出现进一步滞后。
从派生表中聚合
现在,您已经设置了计划查询,并且已预先计算聚合并具体化到计划计算的目标配置中指定的 LiveAnalytics 表的另一个时间流,您可以使用该表中的数据编写 SQL 查询来为仪表板提供支持。以下查询等效于使用预聚合具体化表,为 us-east-1 区域生成每分钟数据点计数聚合。
SELECT bin(time, 1m) as minute, SUM(numDataPoints) as numDatapoints FROM "derived"."per_minute_aggs_pt5m" WHERE time BETWEEN from_milliseconds(1636699996445) AND from_milliseconds(1636743196445) AND region = 'us-east-1' GROUP BY bin(time, 1m) ORDER BY 1 desc
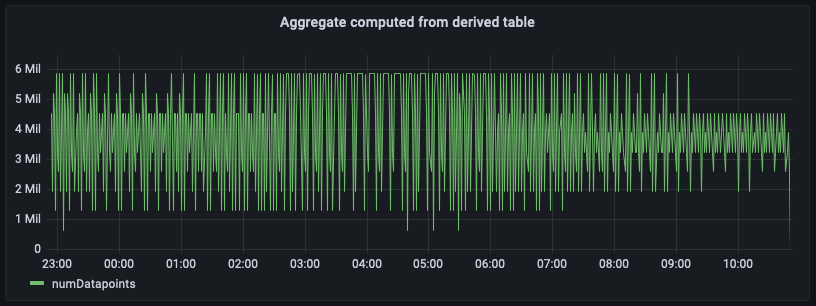
上图绘制根据聚合表计算得出的聚合。将此面板与基于原始数据计算的面板进行对比,您会发现两者完全吻合,尽管这些聚合数据存在几分钟的延迟,该延迟由您为计划计算设置的刷新间隔加上实际执行时间共同决定。
相较于基于原始数据源计算的聚合结果,此预计算数据查询所扫描的数据量要少几个数量级。根据聚合的粒度,这种减少可轻松实现将成本和查询延迟降低 100 倍。执行此计划计算会产生成本。然而,根据这些控制面板的刷新频率以及同时加载这些控制面板的用户数量,通过使用这些预计算,最终能显著降低整体成本。此外,控制面板的加载速度还提升 10-100 倍。
结合源表和派生表的聚合
使用派生表创建的控制面板可能出现滞后。如果您的应用程序场景要求仪表板包含最新数据,则可以利用 Timestream for LiveAnalytics 的 SQL 支持的强大功能和灵活性,将源表中的最新数据与派生表中的历史聚合结合起来,形成合并视图。此合并视图使用 SQL 的并集语义,结合源表与派生表中不重叠的时间范围。在以下示例中,我们使用 "derived"."per_minute_aggs_pt5m" 的派生表。由于该派生表的计划计算每 5 分钟刷新一次(根据计划表达式规范),因此以下查询会使用源表最近 15 分钟的数据,以及派生表中超过 15 分钟的任何数据,然后合并结果以创建合并视图。该视图兼具两者优势:既能通过读取派生表中预先计算的聚合数据实现经济性与低延迟,又能借助源表中聚合数据的实时性,为您的实时分析使用案例提供支持。
请注意,与仅查询派生表相比,这种联合查询方法将导致查询延迟略有增加,同时数据扫描量也会略有提升,因为该方法需要实时聚合原始数据以填充最新的时间间隔。然而,相较于从源表实时聚合数据,这种合并视图仍然更快且更经济,尤其对于需要呈现数日或数周数据的控制面板而言。您可以根据应用程序的刷新需求和延迟容忍度调整此示例的时间范围。
WITH aggregated_source_data AS ( SELECT bin(time, 1m) as minute, SUM(CASE WHEN measure_name = 'metrics' THEN 20 ELSE 5 END) as numDatapoints FROM "raw_data"."devops" WHERE time BETWEEN bin(from_milliseconds(1636743196439), 1m) - 15m AND from_milliseconds(1636743196439) AND region = 'us-east-1' GROUP BY bin(time, 1m) ), aggregated_derived_data AS ( SELECT bin(time, 1m) as minute, SUM(numDataPoints) as numDatapoints FROM "derived"."per_minute_aggs_pt5m" WHERE time BETWEEN from_milliseconds(1636699996439) AND bin(from_milliseconds(1636743196439), 1m) - 15m AND region = 'us-east-1' GROUP BY bin(time, 1m) ) SELECT minute, numDatapoints FROM ( ( SELECT * FROM aggregated_derived_data ) UNION ( SELECT * FROM aggregated_source_data ) ) ORDER BY 1 desc
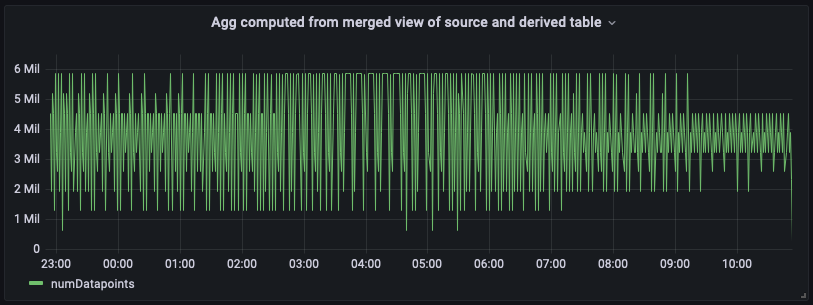
以下是带有此统一合并视图的控制面板。如您所见,仪表板看起来与根据派生表计算出的视图几乎相同,唯一的不同是它在最右边的尖端会有最多的 up-to-date聚合。
根据频繁刷新的计划计算进行聚合
根据控制面板的加载频率以及您期望的控制面板延迟程度,还有另一种方法可让控制面板显示更近的结果:通过计划计算更频繁地刷新聚合数据。例如,以下是相同计划计算的配置,不同之处在于每分钟刷新一次(注意计划表达式 cron(0/1 * * * ? *))。使用此设置,派生表 per_minute_aggs_pt1m 将包含比每 5 分钟刷新一次场景更为及时的聚合数据。
{ "Name": "MultiPT1mPerMinutePerRegionMeasureCount", "QueryString": "SELECT region, bin(time, 1m) as minute, SUM(CASE WHEN measure_name = 'metrics' THEN 20 ELSE 5 END) as numDataPoints FROM raw_data.devops WHERE time BETWEEN @scheduled_runtime - 10m AND @scheduled_runtime + 1m GROUP BY bin(time, 1m), region", "ScheduleConfiguration": { "ScheduleExpression": "cron(0/1 * * * ? *)" }, "NotificationConfiguration": { "SnsConfiguration": { "TopicArn": "******" } }, "TargetConfiguration": { "TimestreamConfiguration": { "DatabaseName": "derived", "TableName": "per_minute_aggs_pt1m", "TimeColumn": "minute", "DimensionMappings": [ { "Name": "region", "DimensionValueType": "VARCHAR" } ], "MultiMeasureMappings": { "TargetMultiMeasureName": "numDataPoints", "MultiMeasureAttributeMappings": [ { "SourceColumn": "numDataPoints", "MeasureValueType": "BIGINT" } ] } } }, "ErrorReportConfiguration": { "S3Configuration" : { "BucketName" : "******", "ObjectKeyPrefix": "errors", "EncryptionOption": "SSE_S3" } }, "ScheduledQueryExecutionRoleArn": "******" }
SELECT bin(time, 1m) as minute, SUM(numDataPoints) as numDatapoints FROM "derived"."per_minute_aggs_pt1m" WHERE time BETWEEN from_milliseconds(1636699996446) AND from_milliseconds(1636743196446) AND region = 'us-east-1' GROUP BY bin(time, 1m), region ORDER BY 1 desc
由于派生表包含更近期的聚合数据,现在可直接查询派生表 per_minute_aggs_pt1m 以获取更新鲜的聚合结果,这可从前文查询及下方控制面板快照中得到验证。
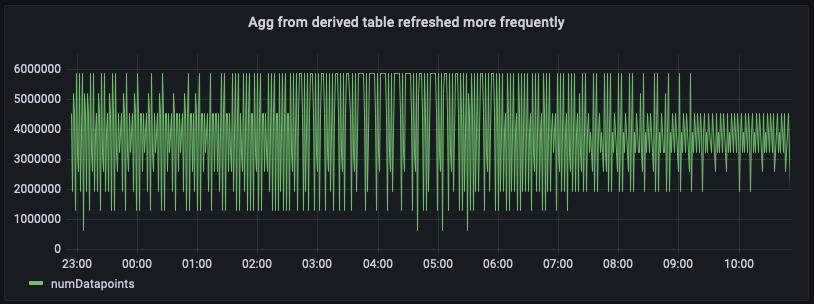
请注意,将计划计算的刷新频率提高(例如从 5 分钟改为 1 分钟),将增加该计划计算的维护成本。每次计算执行后的通知消息会提供统计信息,说明扫描了多少数据以及向派生表写入了多少数据。同样,如果您使用合并视图合并派生表,则在合并视图上查询成本,相比仅查询派生表,控制面板加载延迟会更高。因此,您选择的方法将取决于控制面板的刷新频率以及计划查询的维护成本。如果数十名用户每分钟左右刷新一次控制面板,则提高派生表的刷新频率很可能会降低整体成本。