要获得与亚马逊 Timestream 类似的功能 LiveAnalytics,可以考虑适用于 InfluxDB 的亚马逊 Timestream。适用于 InfluxDB 的 Amazon Timestream 提供简化的数据摄取和个位数毫秒级的查询响应时间,以实现实时分析。点击此处了解更多信息。
本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
创建 CloudWatch 警报以监控亚马逊 Timestream 的 InfluxDB
您可以创建一个 CloudWatch 警报,当警报状态发生变化时,该警报会发送 Amazon SNS 消息。警报会监控您指定的时间段内的某个指标。此外,警报会根据指标值在多个时间段内对比给定阈值的情况执行一项或多项操作。操作是向 Amazon SNS 主题或 Amazon EC2 Auto Scaling 策略发送的通知。
警报仅针对持续的状态变化调用操作。 CloudWatch 警报不会仅仅因为它们处于特定状态就调用操作。该状态必须改变并在指定数量的时间段内一直保持。
你可以为 InfluxDB 的 Timestream 的任何可用指标设置 CloudWatch 警报,包括、CPUUtilizationMemoryUtilization、DiskUtilization和。ReplicaLag
我们建议您开始为InfluxDB数据库的时间流创建DiskUtilization相关的警报,因为 out-of-storage空间问题可能会给InfluxDB带来相当大的问题。我们建议将警报设置为在 DiskUtilization 超过约 75-80% 时发送。
要使用设置警报 Amazon CLI
调用 put-metric-alarm。有关更多信息,请参阅《Amazon CLI 命令参考》中的 put-metric-alarm
使用 CloudWatch API 设置警报
调用 PutMetricAlarm。有关更多信息,请参阅 Amazon CloudWatch API 参考PutMetricAlarm中的。有关设置 Amazon SNS 主题和创建警报的更多信息,请参阅使用亚马逊 CloudWatch 警报。
教程:针对适用于 InfluxD CloudWatch B 的亚马逊 Timestream 的多可用区集群副本延迟创建亚马逊警报
您可以创建一个 Amazon CloudWatch 警报,当多可用区数据库集群的副本延迟超过阈值时,该警报会发送 Amazon SNS 消息。告警会在您指定的时间范围内监控 ReplicaLag 指标。操作是向 Amazon SNS 主题或 Amazon EC2 Auto Scaling 策略发送的通知。
为多可用区数据库集群副本延迟设置 CloudWatch 警报
-
登录 Amazon Web Services 管理控制台 并打开 CloudWatch 控制台,网址为https://console.aws.amazon.com/cloudwatch/
。 -
在导航窗格中,选择警报,然后选择所有警报。
-
选择 Create Alarm (创建警报)。
-
在 Specify metric and conditions (指定指标和条件) 页面上,选择 Select metric (选择指标)。
-
在搜索框中,输入数据库集群的名称,选择 TimeStream/InfluxDB、B y DbCluster,然后选择您的集群。
-
下图显示选择指标页面,其中已选择名为
inframonitoringcluster的只读副本集群。选择您要为其(本例中为ReplicaLag)创建警报的指标。点击选择指标。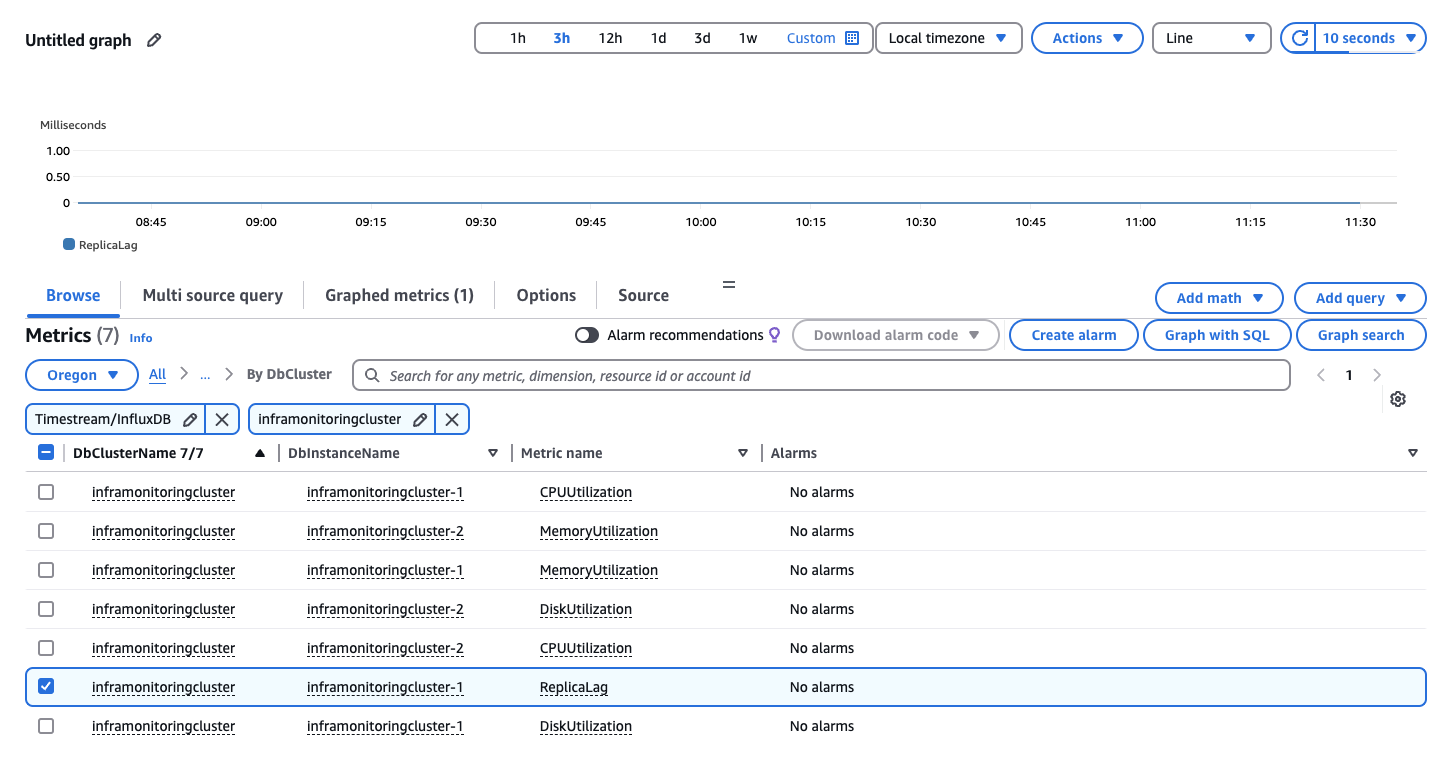
-
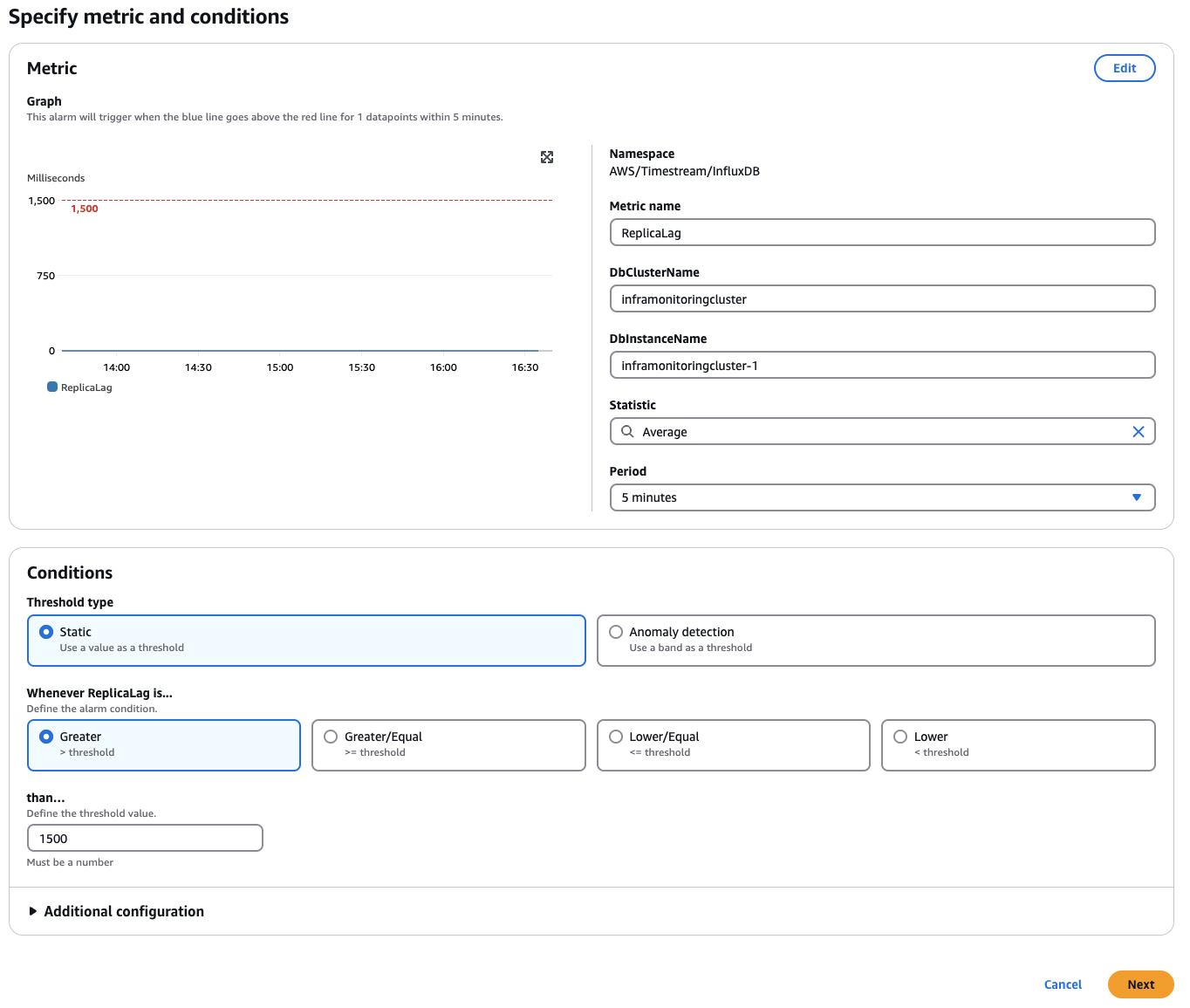
在指定指标和条件页面上,自定义以下字段:
-
在时段部分,选择计算的时间段。
-
设置与警报相关的条件。对于阈值类型,可以在静态和异常检测之间进行选择。
在此情况下,我们将使用静态,因为我们了解工作负载的行为。每个工作负载对“正常运行”状态的要求可能存在差异。
-
选择阈值。对于静态阈值,这些值以毫秒为单位。
-
选择下一步。
-
-
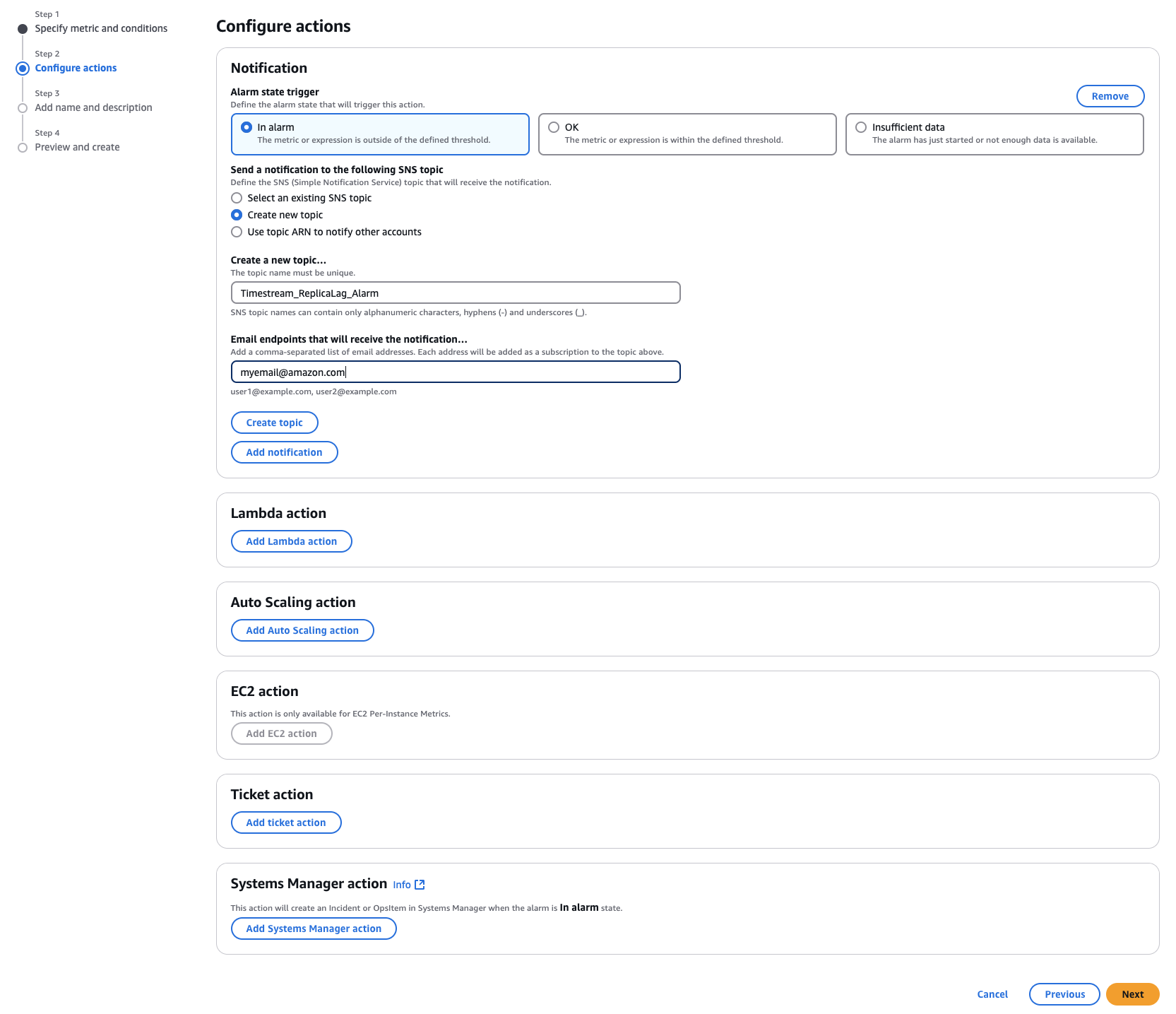
在通知部分的配置操作页面中,自定义以下设置:
-
对于警报状态触发器,选择在警报中。
-
在向以下 SNS 主题发送通知中,选择新建主题。
-
输入接收通知的唯一主题名称和有效电子邮件地址。
-
选择创建主题。向下滚动并选择下一步。
-
-
在添加名称和说明页面中,输入 警报名称和警报说明。选择下一步。
-
在预览和创建页面上,查看警报设置,然后选择创建警报。
重要
为确保适用于 InfluxDB 的 Timestream 集群处于正常运行状态,我们还建议您进行监控,并为持续超过 85% 正常使用率的 CPUUtilization 和 MemoryUtilization,以及超过 75% 使用率的 DiskUtilization 设置警报。