本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
# Flink Autoscaler
## 概述
Amazon EMR 发行版 6.15.0 及更高版本支持 *Flink Autoscaler*。作业自动扩缩器功能从正在运行的 Flink 流式传输作业中收集指标,并自动扩展单个作业顶点。这可以降低反向压力并满足您设定的利用率目标。
有关更多信息,请参阅 *Apache Flink Kubernetes Operator* 文档中的 [Autoscaler](https://nightlies.apache.org/flink/flink-kubernetes-operator-docs-main/docs/custom-resource/autoscaler/) 部分。
## 注意事项
+ Amazon EMR 6.15.0 及更高版本支持 Flink Autoscaler。
+ Flink Autoscaler 仅支持流式传输作业。
+ 仅支持自适应计划程序。不支持默认计划程序。
+ 我们建议您启用集群扩展以允许动态资源预调配。首选 Amazon EMR 托管式自动扩缩功能,因为指标评估每 5-10 秒进行一次。在此间隔内,您的集群可以更轻松地适应所需集群资源的变化。
## 启用 Autoscaler
创建 Amazon EMR on EC2 集群时,使用以下步骤启用 Flink Autoscaler。
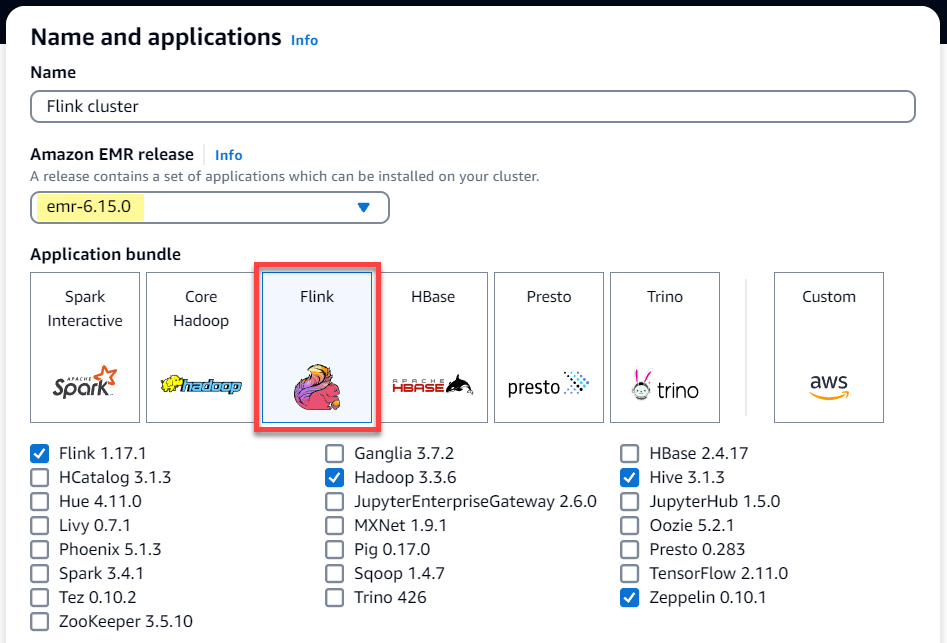
1. 在 Amazon EMR 控制台中,创建新的 EMR 集群:
1. 选择 Amazon EMR 发行版 `emr-6.15.0` 或更高版本。选择 **Flink** 应用程序捆绑包,然后选择您可能想要包含在集群中的任何其他应用程序。
1. 在**集群扩展和预调配选项**下,选择**使用 EMR 托管扩展**。

1. 在**软件设置**部分,输入以下配置以启用 Flink Autoscaler。对于测试场景,请将决策间隔、指标窗口间隔和稳定间隔设置为较低的值,以便作业立即做出扩展决策,从而更便于验证。
```
[
{
"Classification": "flink-conf",
"Properties": {
"job.autoscaler.enabled": "true",
"jobmanager.scheduler": "adaptive",
"job.autoscaler.stabilization.interval": "60s",
"job.autoscaler.metrics.window": "60s",
"job.autoscaler.decision.interval": "10s",
"job.autoscaler.debug.logs.interval": "60s"
}
}
]
```
1. 选择或配置您喜欢的任何其他设置,然后创建支持 Flink Autoscaler 的集群。
## Autoscaler 配置
本部分涵盖了您可以根据自己的特定需求更改的大多数配置。
**注意**
对于基于时间的配置(如 `time`、`interval` 和 `window`设置),如果未指定单位,则默认单位为毫秒。因此,不带后缀的值 `30` 等于 30 毫秒。对于其他时间单位,对于*秒*,包含适当的后缀 `s`,对于*分钟*,包含 `m`,或者对于*小时*,包含 `h`。
**Topics**
+ [循环配置](#flink-autoscaler-config-loop)
+ [指标和历史记录配置](#flink-autoscaler-config-metrics)
+ [顶点配置](#flink-autoscaler-config-vertex)
+ [积压作业配置](#flink-autoscaler-config-backlog)
+ [扩展操作配置](#flink-autoscaler-config-scale)
### Autoscaler 循环配置
Autoscaler 每隔几个可配置的时间间隔获取一次作业顶点级别指标,将其转换为扩展操作项,估计新的作业顶点并行度,并将其推荐给作业计划程序。只有在作业重启时间和集群稳定间隔之后才会收集指标。
| 配置密钥 | 默认 值 | 说明 | 示例值 |
| --- | --- | --- | --- |
| job.autoscaler.enabled | false | 在 Flink 集群上启用自动扩缩。 | true, false |
| job.autoscaler.decision.interval | 60s | Autoscaler 决策时间间隔。 | 30(默认单位为毫秒)、5m、1h |
| job.autoscaler.restart.time | 3m | 在操作员能够根据历史记录可靠地确定重启时间之前,将使用预期重启时间。 | 30(默认单位为毫秒)、5m、1h |
| job.autoscaler.stabilization.interval | 300s | 不会执行新扩展的稳定期。 | 30(默认单位为毫秒)、5m、1h |
| job.autoscaler.debug.logs.interval | 300s | Autoscaler 调试日志间隔。 | 30(默认单位为毫秒)、5m、1h |
### 指标聚合和历史记录配置
Autoscaler 获取指标,在基于时间的滑动窗口内聚合这些指标,然后对这些指标进行评估以做出扩展决策。利用每个作业顶点的扩展决策历史记录来估计新的并行度。它们既有基于年龄的到期时间,也有历史记录大小(至少 1)。
| 配置密钥 | 默认 值 | 说明 | 示例值 |
| --- | --- | --- | --- |
| job.autoscaler.metrics.window | 600s | Scaling metrics aggregation window size. | 30(默认单位为毫秒)、5m、1h |
| job.autoscaler.history.max.count | 3 | 每个顶点要保留的过去的扩展决策的最大数量。 | 1 到 Integer.MAX\_VALUE |
| job.autoscaler.history.max.age | 24h | 每个顶点要保留的过去的扩展决策的最小数量。 | 30(默认单位为毫秒)、5m、1h |
### 作业顶点级别配置
每个作业顶点的并行度根据目标利用率进行修改,并受最小-最大并行度限制的局限。不建议将目标利用率设置为接近 100%(即,值 1),利用率界限可以作为缓冲区来处理中间负载波动。
| 配置密钥 | 默认 值 | 说明 | 示例值 |
| --- | --- | --- | --- |
| job.autoscaler.target.utilization | 0.7 | 目标顶点利用率。 | 0 - 1 |
| job.autoscaler.target.utilization.boundary | 0.4 | 目标顶点利用率界限。如果当前处理速率在 [target\_rate / (target\_utilization - boundary) 内并且为 (target\_rate / (target\_utilization \+ boundary)],则不会执行扩展 | 0 - 1 |
| job.autoscaler.vertex.min-parallelism | 1 | Autoscaler 可以使用的最小并行度。 | 0 - 200 |
| job.autoscaler.vertex.max-parallelism | 200 | Autoscaler 可以使用的最大并行度。请注意,如果该限值高于 Flink 配置中配置的最大并行度或直接在每个 Operator 上设定的最大并行度,则该限值会被忽略。 | 0 - 200 |
### 积压作业处理配置
作业顶点需要额外的资源来处理在扩展操作期间积累的待处理事件或积压作业。这也称为 `catch-up` 持续时间。如果处理积压作业的时间超过配置的 `lag -threshold` 值,则作业顶点目标利用率将提高到最大级别。这有助于防止在积压作业处理过程中进行不必要的扩展操作。
| 配置密钥 | 默认 值 | 说明 | 示例值 |
| --- | --- | --- | --- |
| job.autoscaler.backlog-processing.lag-threshold | 5m | 延迟阈值可防止不必要的扩展,同时移除导致延迟的待处理消息。 | 30(默认单位为毫秒)、5m、1h |
| job.autoscaler.catch-up.duration | 15m | 扩展操作后完全处理所有积压作业的目标持续时间。设置为 0 可禁用基于积压作业的扩展。 | 30(默认单位为毫秒)、5m、1h |
### 扩展操作配置
在宽限期内,Autoscaler 不会在纵向扩展操作后立即执行缩减操作。这样可以防止由于临时负载波动而导致不必要的秤 up-down-up-down操作循环。
我们可以使用缩减操作比率来逐步降低并行度并释放资源,以应对临时的负载峰值。它还有助于防止在大规模缩减操作后进行不必要的轻微纵向扩展操作。
我们可以根据过去的作业顶点扩展决策历史记录来检测无效的纵向扩展操作,以防止进一步的并行度变化。
| 配置密钥 | 默认 值 | 说明 | 示例值 |
| --- | --- | --- | --- |
| job.autoscaler.scale-up.grace-period | 1h | 纵向扩展顶点后不允许缩减顶点的持续时间。 | 30(默认单位为毫秒)、5m、1h |
| job.autoscaler.scale-down.max-factor | 0.6 | 最大缩减系数。值为 1 表示对缩减没有限制;0.6 意味着只能使用原始并行度的 60% 来缩减作业。 | 0 - 1 |
| job.autoscaler.scale-up.max-factor | 100000. | 最大纵向扩展比。值为 2.0 意味着只能使用当前并行度的 200% 来纵向扩展作业。 | 0 - Integer.MAX\_VALUE |
| job.autoscaler.scaling.effectiveness.detection.enabled | false | 是否启用对无效扩展操作的检测,并允许 Autoscaler 阻止进一步的纵向扩展。 | true, false |