从 2025 年 11 月 1 日起,Amazon Redshift 将不再支持创建新的 Python UDF。如果您想要使用 Python UDF,请在该日期之前创建 UDF。现有的 Python UDF 将继续正常运行。有关更多信息,请参阅博客文章
了解 Amazon Redshift 概念
Amazon Redshift Serverless 让您可以访问和分析数据,而无需对预置数据仓库执行任何配置操作。系统将自动预置资源,数据仓库的容量会智能扩展,即使面对要求最为苛刻且不可预测的工作负载也能提供高速性能。数据仓库空闲时不会产生费用,您只需为实际使用的资源付费。您可以在 Amazon Redshift 查询编辑器 v2 或您最喜欢的商业智能(BI,Business Intelligence)工具中,直接加载数据并开始查询。在易于使用且无需承担管理任务的环境中,享受最佳性价比,使用熟悉的 SQL 功能。
如果您是首次接触 Amazon Redshift 的用户,我们建议您先阅读以下部分:
-
Amazon Redshift Serverless 功能概览 – 本主题概要介绍了 Amazon Redshift Serverless 及其关键功能。
-
服务亮点和定价
– 在该产品详细信息页面上,您可以找到有关 Amazon Redshift Serverless 的亮点和定价的详细信息。 -
Amazon Redshift Serverless 数据仓库入门 – 在本主题中,您将详细了解如何创建 Amazon Redshift Serverless 数据仓库,以及如何使用查询编辑器 v2 开始查询数据。
如果您希望手动管理 Amazon Redshift 资源,则可以创建预置集群来满足自己的数据查询需求。有关更多信息,请参阅 Amazon Redshift 集群。
如果您的组织符合条件,而在您创建集群的 Amazon Web Services 区域中,Amazon Redshift Serverless 不可用,则您也许可以通过 Amazon Redshift 免费试用计划创建集群。请选择生产或免费试用来回答问题您打算将此集群用于什么? 选择免费试用时,您将创建具有 dc2.large 节点类型的配置。有关选择免费试用的更多信息,请参阅 Amazon 免费试用
以下是 Amazon Redshift Serverless 的一些关键概念:
-
命名空间 – 数据库对象和用户的集合。命名空间将您在 Amazon Redshift Serverless 中使用的所有资源组合在一起,例如架构、表、用户、数据共享和快照。
-
工作组 – 计算资源的集合。工作组存放 Amazon Redshift Serverless 运行计算任务所用的计算资源。这些资源的示例包括 Redshift 处理单元(RPU,Redshift Processing Unit)、安全组、使用限制。您可以使用 Amazon Redshift Serverless 控制台、Amazon Command Line Interface 或 Amazon Redshift Serverless API 来配置工作组的网络和安全设置。
有关配置命名空间和工作组资源的更多信息,请参阅使用命名空间和使用工作组。
以下是 Amazon Redshift 预置集群的一些关键概念:
-
集群 – 集群是 Amazon Redshift 数据仓库的核心基础设施组件。
集群包含一个或多个计算节点。这些计算节点运行编译后的代码。
如果集群预置有两个或更多计算节点,则一个额外的领导节点将协调这些计算节点。领导节点处理与应用程序的外部通信,例如商业智能工具和查询编辑器。您的客户端应用程序仅直接与领导节点交互。计算节点对于外部应用程序是透明的。
-
数据库 – 一个集群包含一个或多个数据库。
用户数据存储在计算节点上的一个或多个数据库中。您的 SQL 客户端与领导节点进行通信,进而通过计算节点协调查询运行。有关计算节点和领导节点的详细信息,请参阅数据仓库系统架构。在数据库中,用户数据被组织成一个或多个架构。
Amazon Redshift 是一个关系数据库管理系统(RDBMS),可与其它 RDBMS 应用程序兼容。虽然它提供了与典型 RDBMS 相同的功能,包括联机事务处理(OLTP)功能,例如,插入和删除数据。Amazon Redshift 还针对数据集的高性能批量分析和报告进行了优化。
接下来,您可以在 Amazon Redshift 中找到对典型数据处理流程的描述以及流程不同部分的描述。有关 Amazon Redshift 系统架构的更多信息,请参阅数据仓库系统架构。
以下示意图说明 Amazon Redshift 中典型的数据处理流程。
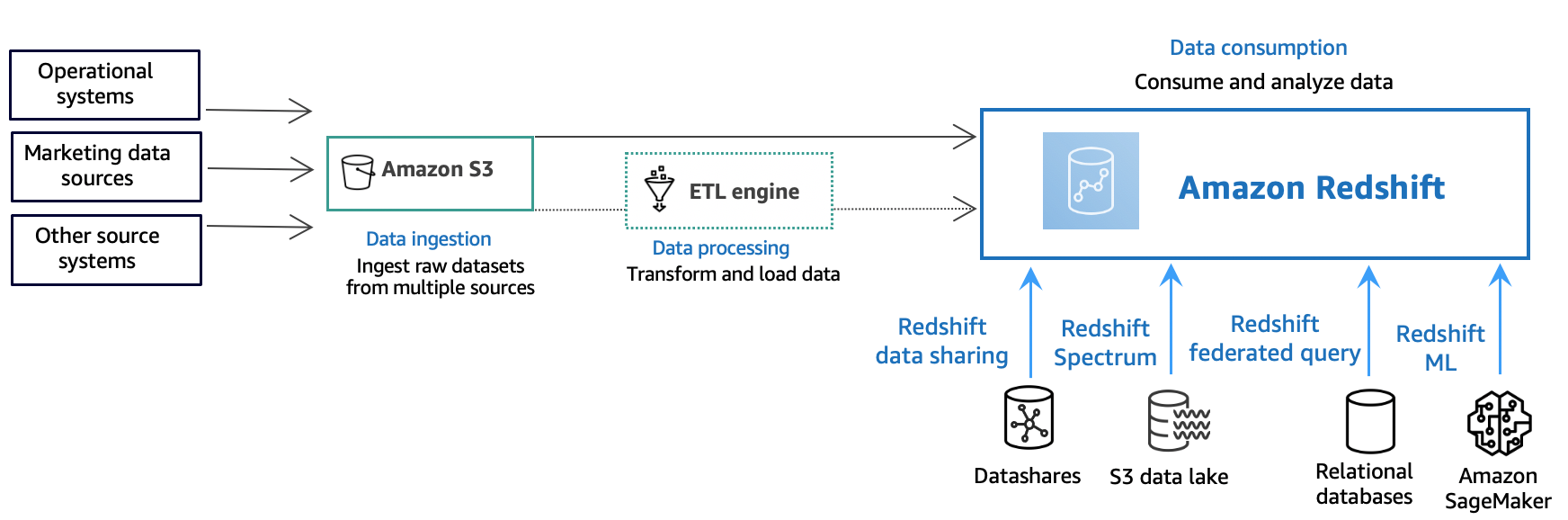
Amazon Redshift 数据仓库是一个企业级的关系数据库查询和管理系统。Amazon Redshift 支持与多种类型的应用程序(包括业务情报 (BI)、报告、数据和分析工具)建立客户端连接。在运行分析查询时,您将在多阶段操作中检索、比较和计算大量数据以产生最终结果。
在数据摄取层,不同类型的数据源会持续将结构化、半结构化或非结构化数据上载到数据存储层。该数据存储区用作暂存区,用于存储处于不同消费准备状态的数据。Amazon Simple Storage Service(Amazon S3)存储桶就是这种存储的示例。
在可选数据处理层,源数据使用提取、转换、加载(ETL)或提取、加载、转换(ELT)管道进行预处理、验证和转换。然后,使用 ETL 操作对这些原始数据集进行优化。ETL 引擎的一个示例是 Amazon Glue。
在数据使用层,数据将加载到 Amazon Redshift 集群中,您可以在其中运行分析工作负载。
有关分析工作负载的示例,请参阅查询外部数据来源。