示例:使用 Application Signals 解决运行状况问题
以下场景提供了一个示例,说明如何使用 Application Signals 来监控服务和识别服务质量问题。深入研究,找出潜在根本原因并采取措施解决问题。此示例重点介绍宠物诊所应用程序,该应用程序由多个调用 DynamoDB 等 Amazon Web Services 服务 的微服务组成。
Jane 是 DevOps 团队的一员,该团队负责监管宠物诊所应用程序的运行状况。Jane 的团队致力于确保该应用程序的高可用性和响应能力。他们使用服务级别目标(SLO)来衡量在这些业务承诺方面的应用程序性能。她收到有关多个运行不正常服务级别指标(SLI)的警报。她打开 CloudWatch 控制台并导航到“服务”页面,然后看到有多个服务运行不正常。
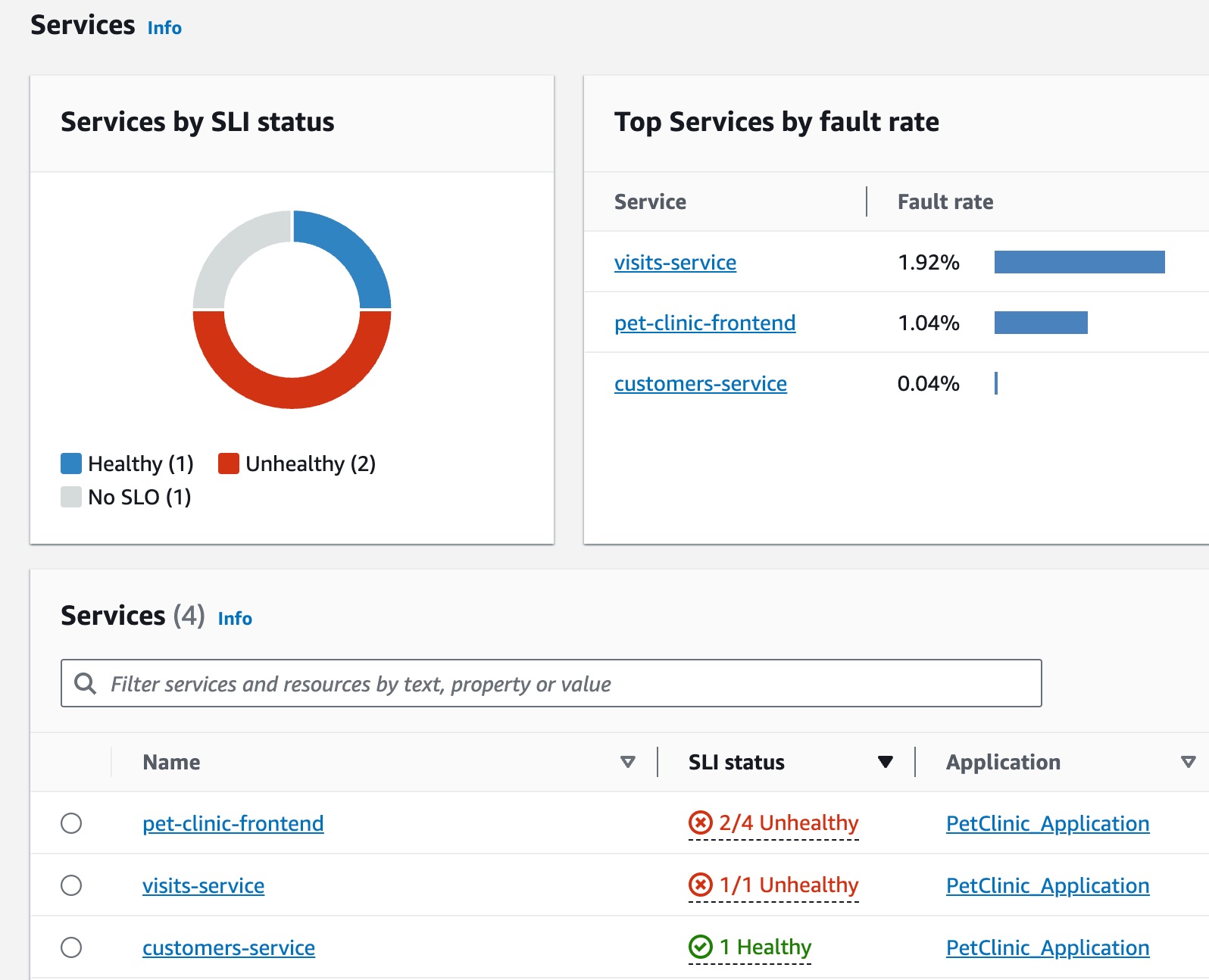
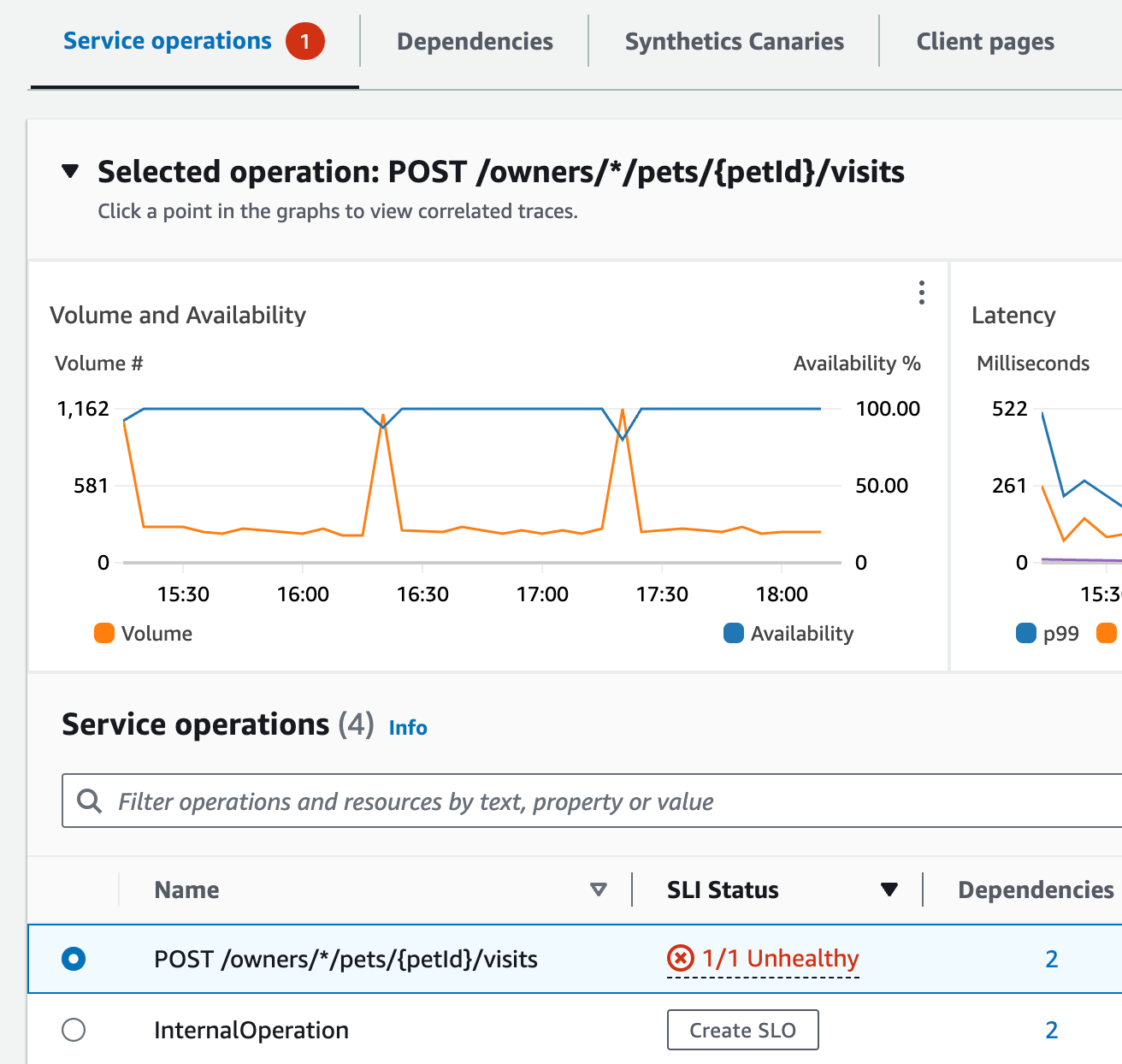
Jane 在该页面顶部看到 visits-service 是按故障率排序的顶部服务。她选择了图表中的链接,打开该服务的“服务详细信息”页面。她看到“服务操作”表格中存在不正常的运行状况。她选择了此操作,并在“操作量和可用性”图表中看到,出现的周期性调用量激增似乎与可用性下降有关。
为了更好地观察服务可用性的下降情况,Jane 选择了图表中的一个可用性数据点。这打开了一个抽屉,其中显示与所选数据点相关的 X-Ray 跟踪。她看到有多个跟踪处于故障状态。
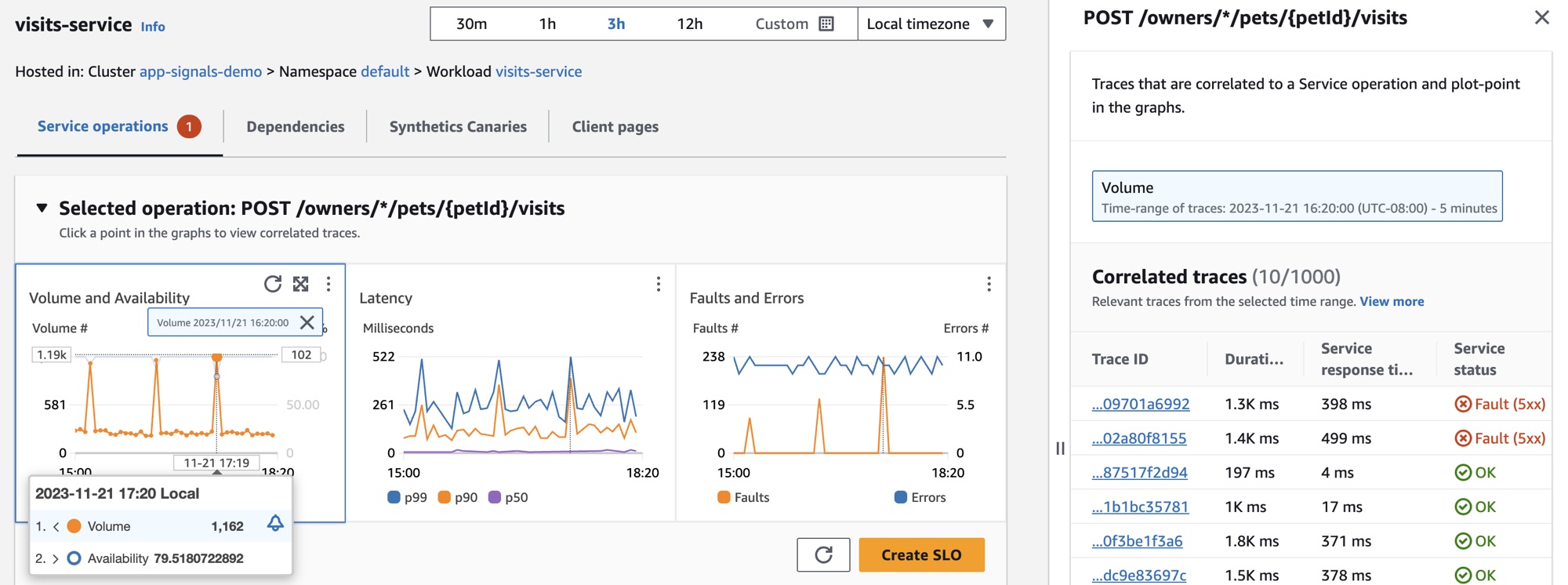
Jane 选择了其中一个具有故障状态的关联跟踪,随即打开所选跟踪的 X-Ray 跟踪详细信息页面。Jane 向下滚动到“分段时间线”部分并跟踪调用路径,直到看到对 DynamoDB 表的调用开始返回错误。她选择了 DynamoDB 分段,然后导航到右侧抽屉的“异常”选项卡。
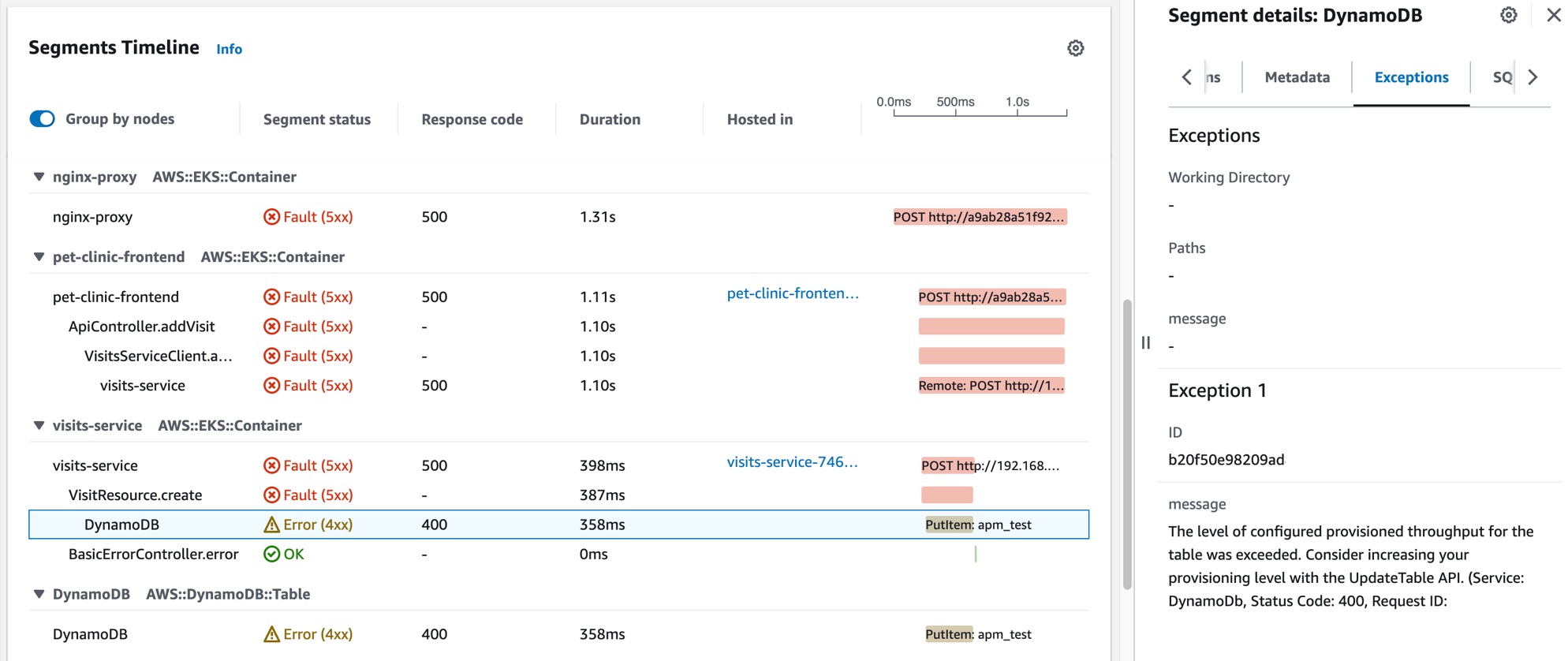
Jane 发现 DynamoDB 资源配置错误,导致在客户端请求激增期间出现错误。DynamoDB 表的预置吞吐量水平周期性超标,导致服务可用性问题以及 SLI 运行不正常。根据这些信息,她的团队得以配置更高水平的预置吞吐量,并确保应用程序的高可用性。