在 Amazon Aurora Global Database 中使用切换或失效转移
与 Aurora 数据库集群在单个 Amazon Web Services 区域中提供的标准高可用性相比,Aurora Global Database 特征提供了更高的业务连续性和灾难恢复(BCDR)保护。通过使用 Aurora Global Database,您可以计划从罕见、计划外的区域性灾难或完全的服务级别中断中更快地恢复。
您可以参阅以下指南和程序,使用 Aurora Global Database 特征来计划、测试和实施 BCDR 策略。
主题
计划业务连续性和灾难恢复
要计划业务连续性和灾难恢复策略,了解以下行业术语以及这些术语与 Aurora Global Database 特征的关系会很有帮助。
从灾难中恢复通常由以下两个业务目标驱动:
-
恢复时间目标(RTO)– 灾难或服务中断后系统恢复工作状态所需的时间。换言之,RTO 用于衡量停机时间。对于 Aurora Global Database,RTO 大约为数分钟。
-
恢复点目标(RPO)– 灾难或服务中断后可能丢失的数据量(按时间衡量)。这种数据丢失通常是由于异步复制滞后造成的。对于 Aurora 全球数据库,RPO 通常以秒为单位进行测量。通过基于 Aurora PostgreSQL 的全局数据库,您可以使用
rds.global_db_rpo参数设置和跟踪 RPO 上限,但这样做可能会影响主集群写入器节点上的事务处理。有关更多信息,请参阅 管理基于 Aurora PostgreSQL 的全局数据库的 RPO。
使用 Aurora Global Database 执行切换或失效转移时,需要将辅助数据库集群提升为主数据库集群。“区域性停机”一词通常用于描述各种故障情况。最坏的情况可能是影响数百平方英里的灾难性事件造成的广泛停电。但是,大多数停机的局部程度会高得多,仅影响一小部分云服务或客户系统。考虑停机的全部范围,以确保跨区域失效转移是正确的解决方案,并针对这种情况选择适当的失效转移方法。应使用失效转移还是切换方法取决于具体的停机情况:
-
失效转移 – 使用此方法从计划外停机中恢复。使用这种方法,您可以跨区域失效转移到 Aurora 全球数据库中的一个辅助数据库集群。这种方法的 RPO 通常是一个以秒为单位的非零值。数据丢失量取决于发生故障时跨 Amazon Web Services 区域的 Aurora 全球数据库复制滞后。要了解更多信息,请参阅从计划外停机中恢复 Amazon Aurora Global Database。
-
切换 – 此操作以前称为“托管式计划内失效转移”。将此方法用于受控场景,例如操作维护和其他计划内操作过程,其中所有 Aurora 集群以及与之交互的其他服务都处于正常状态。由于此特征会在进行任何其他更改之前将辅助数据库集群与主数据库集群同步,因此 RPO 为 0(不会造成数据丢失)。要了解更多信息,请参阅对 Amazon Aurora Global Database 执行切换。
注意
切换或失效转移到无外设辅助 Aurora 数据库集群之前,必须先向其添加一个数据库实例。有关无管控数据库集群的更多信息,请参阅在辅助区域中创建无管控 Aurora 数据库集群。
对 Amazon Aurora Global Database 执行切换
注意
切换以前称为托管式计划内失效转移。
通过使用切换,您可以定期更改主集群的区域。此方法适用于受控场景,例如操作维护和其他计划内操作过程。
切换有三种常见使用案例。
-
适用于对特定行业施加的“区域轮换”要求。例如,金融服务法规可能要求第 0 层系统在几个月内切换到不同的区域,以确保定期执行灾难恢复过程。
-
适用于多区域“全天候”应用程序。例如,一家企业可能希望根据不同时区的工作时间在不同区域提供延迟更低的写入。
-
作为一种零数据丢失方法,可在失效转移后失效自动恢复到原始主区域。
注意
切换旨在用于 Aurora Global Database,其中所有 Aurora 集群以及与之交互的其他服务都处于正常状态。要从计划外停机中进行恢复,请按照从计划外停机中恢复 Amazon Aurora Global Database中的相应过程操作。
仅当主数据库集群和辅助数据库集群具有相同的主要和次要引擎版本时,您才能对 Aurora Global Database 执行托管式跨区域切换。根据引擎和引擎版本,补丁级别可能需要相同,也可以不同。有关允许在具有不同补丁级别的主集群和辅助集群之间进行这些操作的引擎和引擎版本列表,请参阅托管式跨区域切换和失效转移的补丁级别兼容性。在开始切换之前,请检查全球集群中的引擎版本,以确保它们支持托管式跨区域切换,并在需要时对其进行升级。
在切换期间,Aurora 会使您选择的辅助区域中的集群成为主集群。切换机制维护全局数据库的现有复制拓扑:它在相同区域中仍有相同数量的 Aurora 集群。在 Aurora 开始切换过程之前,它会等待目标辅助区域集群与主区域集群完全同步。然后,主区域中的数据库集群变为只读状态。所选的辅助集群将其一个只读节点提升为完全写入器状态,从而允许该辅助集群代入主集群的角色。由于目标辅助集群在过程开始时都与主集群同步,因此新的主集群将继续执行 Aurora Global Database 的操作,而不会丢失任何数据。您的数据库在短时间内不可用,而主集群和所选的辅助集群将担任其新角色。
注意
要在执行切换后管理 Aurora PostgreSQL 的复制时隙,请参阅管理 Aurora PostgreSQL 的逻辑插槽。
为了优化应用程序可用性,我们建议您在使用此特征之前执行以下操作:
-
在非高峰时间段,或在向主数据库集群写入操作最少的其他时间执行此操作。
-
检查 Aurora 全局数据库中所有辅助 Aurora 数据库集群的滞后时间。对于所有基于 Aurora PostgreSQL 的全球数据库以及从引擎版本 3.04.0 及更高版本或 2.12.0 及更高版本开始的基于 Aurora MySQL 的全球数据库,请使用 Amazon CloudWatch 查看所有辅助数据库集群的
AuroraGlobalDBRPOLag指标。对于基于 Aurora MySQL 的全球数据库的较低次要版本,请改为查看AuroraGlobalDBReplicationLag指标。这些指标显示复制到辅助集群滞后于复制到主数据库集群的时间(以毫秒为单位)。该值与 Aurora 完成切换所需的时间成正比。因此,滞后值越大,切换所需的时间就越长。检查这些指标时,请从当前的主集群进行检查。有关 Aurora 的 CloudWatch 指标的更多信息,请参阅 Amazon Aurora 的集群级指标。
-
在切换期间提升的辅助数据库集群的配置设置可能与旧的主数据库集群不同。建议您在 Aurora Global Database 集群中的所有集群之间使以下类型的配置设置保持一致。这样做有助于更大限度地减少切换后的性能问题、工作负载不兼容问题和其他异常行为。
-
为新的主数据库集群配置 Aurora 数据库集群参数组(如有必要)– 当您提升辅助数据库集群以接管主数据库集群的角色时,辅助数据库集群中参数组的配置可能与主数据库集群的配置不同。如果是这样,请修改提升后的辅助数据库集群的参数组,使其与主集群的设置一致。要了解如何操作,请参阅修改 Aurora 全局数据库的参数。
-
配置监控工具和选项(例如 Amazon CloudWatch Events 和警报)– 根据全局数据库的需要,为提升后的数据库集群配置相同的日志记录能力、警报等等。与参数组一样,在切换过程中,这些特征的配置不会从主数据库集群继承。一些 CloudWatch 指标(例如复制滞后)仅适用于辅助区域。因此,切换会更改查看这些指标和对指标设置警报的方式,并且可能要求更改任何预定义的控制面板。有关 Aurora 数据库集群的更多信息,请参阅使用 Amazon CloudWatch 监控 Amazon Aurora 指标。
-
配置与其他 Amazon 服务的集成 - 如果您的 Aurora 全球数据库与 Amazon 服务(例如 Amazon Secrets Manager、Amazon Identity and Access Management、Amazon S3 和 Amazon Lambda)集成,则确保根据需要配置与这些服务的集成。有关将 Aurora Global Database 与 IAM、Amazon S3 和 Lambda 集成的更多信息,请参阅 将 Amazon Aurora Global Database 与其他Amazon服务结合使用。要了解有关 Secrets Manager 的更多信息,请参阅如何跨 Amazon Web Services 区域 自动复制 Amazon Secrets Manager 中的密钥
。
-
如果使用的是 Aurora Global Database 写入器端点,则无需更改应用程序中的连接设置。验证 DNS 更改已传播,并且您可以连接新的主集群并对其执行写入操作。然后,您可以恢复应用程序的完整运行。
假设您的应用程序连接使用旧主集群的集群端点,而不是全局写入器端点。在这种情况下,请务必更改应用程序连接设置,以使用新主集群的集群端点。如果您在创建 Aurora 全局数据库时接受了提供的名称,则可以在应用程序中从提升集群的终端节点字符串中删除 -ro 以更改终端节点。例如,辅助集群的终端节点 my-global.cluster-ro-aaaaaabbbbbb.us-west-1.rds.amazonaws.com 将在该集群提升为主集群时变为终端节点 my-global.cluster-aaaaaabbbbbb.us-west-1.rds.amazonaws.com。
如果您使用的是 RDS 代理,请确保将应用程序的写入操作重定向到与新主集群关联的代理的相应读/写端点。此代理端点可能是默认端点或自定义读/写端点。有关更多信息,请参阅 RDS 代理端点如何与全局数据库配合使用。
您可以使用 Amazon Web Services 管理控制台、Amazon CLI 或 RDS API 对 Aurora Global Database 进行切换。
对您的 Aurora 全球数据库执行切换
登录 Amazon Web Services 管理控制台 并通过以下网址打开 Amazon RDS 控制台:https://console.aws.amazon.com/rds/
。 -
选择数据库,然后找到要进行切换的 Aurora 全局数据库。
-
从操作菜单中选择切换或失效转移全球数据库。
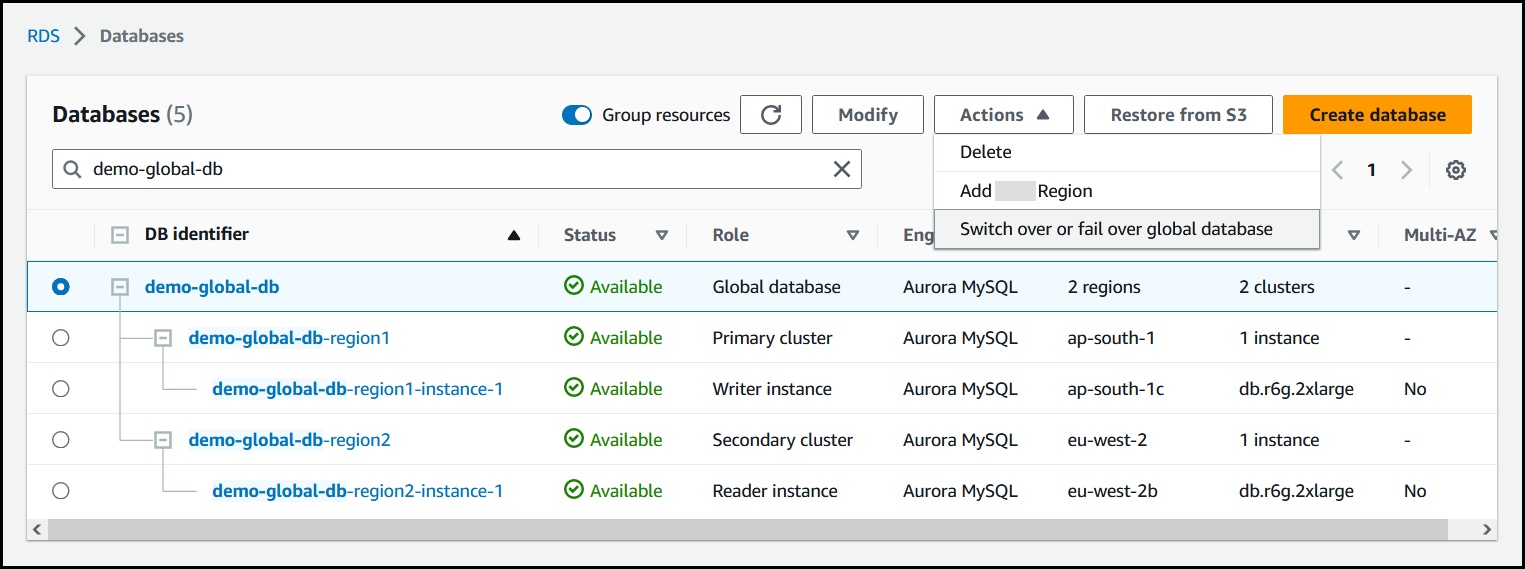
-
选择切换。
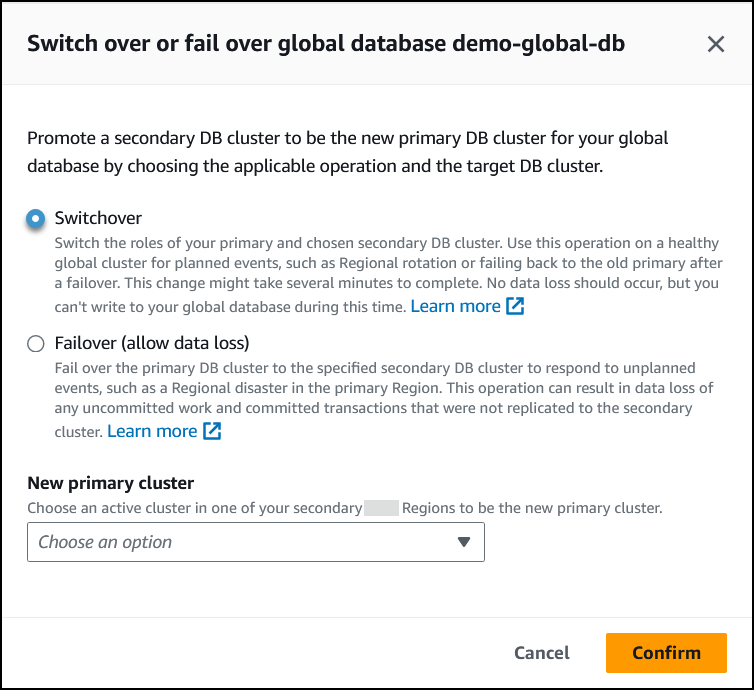
-
对于新的主集群,选择其中一个辅助 Amazon Web Services 区域中的活动集群作为新的主集群。
-
选择确认。
切换完成后,您可以在数据库列表中看到 Aurora 数据库集群及其当前角色,如下图所示。
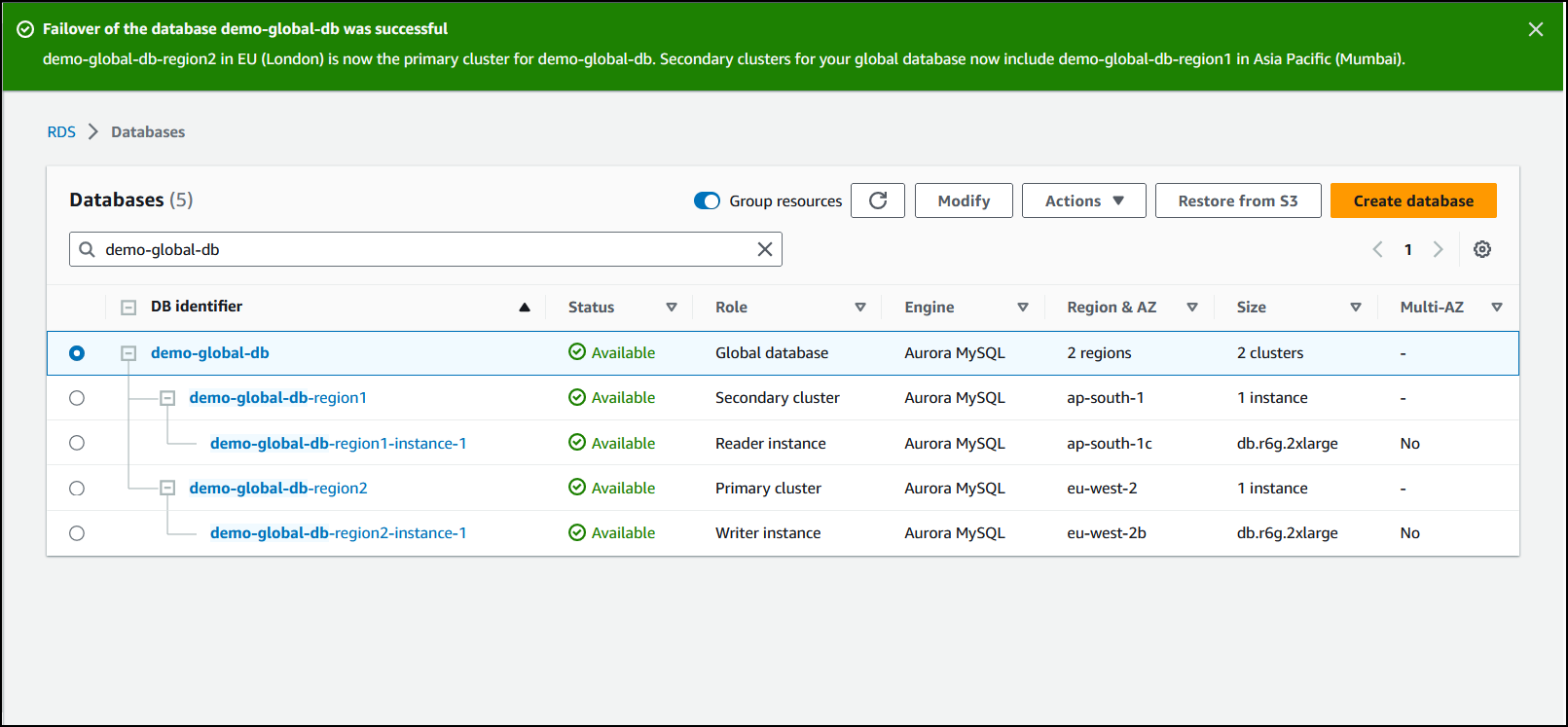
对您的 Aurora 全球数据库执行切换
使用 switchover-global-cluster CLI 命令对 Aurora Global Database 进行切换。使用命令,传递下列参数的值。
-
--region- 指定 Aurora Global Database 的主数据库集群运行的 Amazon Web Services 区域。 -
--global-cluster-identifier– 指定 Aurora 全局数据库的名称。 -
--target-db-cluster-identifier– 指定要提升为 Aurora 全局数据库的主数据库集群的 Aurora 数据库集群的 Amazon 资源名称 (ARN)。
对于 Linux、macOS 或 Unix:
aws rds --regionregion_of_primary\ switchover-global-cluster --global-cluster-identifierglobal_database_id\ --target-db-cluster-identifierarn_of_secondary_to_promote
对于 Windows:
aws rds --regionregion_of_primary^ switchover-global-cluster --global-cluster-identifierglobal_database_id^ --target-db-cluster-identifierarn_of_secondary_to_promote
要对 Aurora Global Database 进行切换,请运行 SwitchoverGlobalCluster API 操作。
从计划外停机中恢复 Amazon Aurora Global Database
在极少数情况下,您的 Aurora Global Database 可能会在其主 Amazon Web Services 区域中发生意外停机。如果发生这种情况,主 Aurora 数据库集群及其写入器节点将不可用,并且主数据库集群和辅助数据库集群之间的复制将停止。为了最大限度地减少停机时间(RTO)和数据丢失(RPO),您可以快速执行跨区域失效转移。
Aurora Global Database 有两种失效转移方法可供您在灾难恢复情况下使用:
-
托管式失效转移 - 建议使用此方法进行灾难恢复。使用此方法时,当旧的主区域再次变为可用时,Aurora 会自动将其作为辅助区域重新添加到全球数据库中。因此,您的全球集群的原始拓扑保持不变。要了解如何使用此方法,请参阅执行 Aurora 全球数据库的托管式失效转移。
-
手动失效转移 – 当无法选择托管式失效转移时,例如,当您的主区域和辅助区域运行不兼容的引擎版本时,可以使用这种替代方法。要了解如何使用此方法,请参阅执行 Aurora 全球数据库的手动失效转移。
重要
这两种失效转移方法都可能导致在失效转移事件发生之前,未复制到选定辅助系统的写入事务数据丢失。但是,将所选辅助数据库集群上的数据库实例提升为主写入器数据库实例的恢复过程可确保数据处于事务一致状态。失效转移也容易受到脑裂问题的影响。
执行 Aurora 全球数据库的托管式失效转移
这种方法用于在发生真实的区域性灾难或完全的服务级别中断时实现业务连续性。
在托管式失效转移期间,所选的辅助区域中的辅助集群将成为新的主集群。所选的辅助集群将其一个只读节点提升为完全写入器状态。此步骤允许集群代入主集群的角色。在此集群代入其新角色期间,您的数据库在短时间内不可用。一旦该旧主区域正常运行并再次可用,Aurora 就会自动将其作为辅助区域重新添加到全局集群中。因此,Aurora Global Database 的现有复制拓扑保持不变。
注意
要在执行失效转移后管理 Aurora PostgreSQL 的复制时隙,请参阅管理 Aurora PostgreSQL 的逻辑插槽。
注意
仅当主数据库集群和辅助数据库集群具有相同的主要和次要引擎版本时,您才能对 Aurora Global Database 执行托管式跨区域失效转移。根据引擎和引擎版本,补丁级别可能需要相同,也可以不同。有关允许在具有不同补丁级别的主集群和辅助集群之间进行这些操作的引擎和引擎版本列表,请参阅托管式跨区域切换和失效转移的补丁级别兼容性。在开始失效转移之前,请检查全球集群中的引擎版本,以确保它们支持托管式跨区域切换,并在需要时对其进行升级。如果您的引擎版本需要相同的补丁级别,但正在运行不同的补丁级别,您可以按照执行 Aurora 全球数据库的手动失效转移中的步骤手动执行失效转移。
托管式失效转移不会等待所选辅助区域和当前主区域之间的数据同步。由于 Aurora Global Database 以异步方式复制数据,因此在所选的辅助 Amazon 区域升级为接受完整读/写功能之前,可能并非所有事务都复制到该区域。
为确保数据处于一致状态,Aurora 会在旧的主区域恢复后为其创建一个新的存储卷。在 Amazon 区域中创建新的存储卷之前,Aurora 会尝试在出现故障时拍摄旧存储卷的快照。这样,您就可以还原快照并从中恢复任何丢失的数据。如果此操作成功,Aurora 会将这个名为 rds:unplanned-global-failover- 的快照放在 Amazon Web Services 管理控制台的“快照”部分中。您也可以使用 name-of-old-primary-DB-cluster-timestampdescribe-db-cluster-snapshots Amazon CLI 命令或 DescribeDBClusterSnapshots API 操作来查看该快照的详细信息。
当您启动托管式失效转移时,Aurora 还会尝试停止流经高可用 Aurora 存储层的写入流量。我们将这种机制称为“写入屏蔽”。如果该过程成功,Aurora 会触发一个 RDS 事件,告知您写入已停止。在极少数情况下,如果某个区域有多个可用区出现故障,则写入屏蔽过程可能无法及时成功。在这种情况下,Aurora 会触发一个 RDS 事件,通知您停止写入的过程已超时。如果可在网络上访问旧的主集群,Aurora 会在那里记录这些事件。否则,Aurora 会将事件记录在新的主集群上。要了解有关这些事件的更多信息,请参阅数据库集群事件。由于屏蔽写入是一种尽力而为的尝试,因此旧的主区域可能会暂时接受写入,从而导致脑裂问题。
建议您在对 Aurora Global Database 执行失效转移之前,先完成以下任务。这样做可以更大限度地降低脑裂问题的可能性,或从旧主集群的快照中恢复未复制数据的可能性。
-
要防止写入内容被发送到 Aurora Global Database 的主集群,请使应用程序离线。
-
确保连接到主数据库集群的所有应用程序都使用全局写入器端点。即使新区域由于切换或失效转移而成为主集群,此端点的值也保持不变。Aurora 实施额外的保护措施,以更大限度地降低通过全局端点提交的写入操作数据丢失的可能性。有关全局写入器端点的更多信息,请参阅 连接到 Amazon Aurora Global Database。
-
如果您使用的是全局写入器端点,并且您的应用程序层或网络层缓存 DNS 值,请将 DNS 缓存的生存时间(TTL)缩短至较低值,例如 5 秒。这样,您的应用程序就可以快速向全局写入器端点注册 DNS 更改。尽管 Aurora 试图阻止在旧主区域中写入,但不能保证该操作会成功。缩短 DNS 缓存持续时间可进一步降低出现脑裂问题的可能性。或者,您也可以查看 RDS 事件,该事件会在 Aurora 观察到全局写入器端点的 DNS 更改时通知您。这样,您就可以在重新启动应用程序写入流量之前验证您的应用程序也注册了 DNS 更改。
-
检查 Aurora Global Database 中所有辅助 Aurora 数据库集群的滞后时间。选择复制滞后最小的辅助区域可以最大限度地减少当前出现故障的主区域的数据丢失。
对于所有基于 Aurora PostgreSQL 的全局数据库版本,以及从引擎版本 3.04.0 及更高版本或 2.12.0 及更高版本开始的基于 Aurora MySQL 的全局数据库,请使用 Amazon CloudWatch 查看所有辅助数据库集群的
AuroraGlobalDBRPOLag指标。对于基于 Aurora MySQL 的全球数据库的较低次要版本,请改为查看AuroraGlobalDBReplicationLag指标。这些指标显示复制到辅助集群滞后于复制到主数据库集群的时间(以毫秒为单位)。有关 Aurora 的 CloudWatch 指标的更多信息,请参阅 Amazon Aurora 的集群级指标。
在托管式失效转移期间,所选的辅助数据库集群将提升为新角色,即主数据库集群。但是,它不会继承主数据库集群的各种配置选项。配置不匹配可能会导致性能问题、工作负载不兼容和其他异常行为。为避免出现此类问题,我们建议您解决以下方面 Aurora 全局数据库集群之间的差异问题:
-
为新的主数据库集群配置 Aurora 数据库集群参数组(如有必要)– 您可以为 Aurora Global Database 中的每个 Aurora 集群单独配置 Aurora 数据库集群参数组。因此,当您提升辅助数据库集群以接管主数据库集群的角色时,辅助数据库集群中参数组的配置可能与主数据库集群的配置不同。如果是这样,请修改提升后的辅助数据库集群的参数组,使其与主集群的设置一致。要了解如何操作,请参阅修改 Aurora 全局数据库的参数。
-
配置监控工具和选项(例如 Amazon CloudWatch Events 和警报)– 根据全局数据库的需要,为提升后的数据库集群配置相同的日志记录能力、警报等等。与参数组一样,在故障转移过程中,这些特征的配置不会从主数据库集群继承。一些 CloudWatch 指标(例如复制滞后)仅适用于辅助区域。因此,失效转移会更改查看这些指标和对指标设置警报的方式,并且可能要求更改任何预定义的控制面板。有关监控 Aurora 数据库集群的更多信息,请参阅使用 Amazon CloudWatch 监控 Amazon Aurora 指标。
-
配置与其他 Amazon 服务的集成 - 如果您的 Aurora Global Database 与 Amazon 服务(例如 Amazon Secrets Manager、Amazon Identity and Access Management、Amazon S3 和 Amazon Lambda)集成,则需要确保根据需要对这些服务进行配置,以从任何辅助区域进行访问。有关将 Aurora Global Database 与 IAM、Amazon S3 和 Lambda 集成的更多信息,请参阅 将 Amazon Aurora Global Database 与其他Amazon服务结合使用。要了解有关 Secrets Manager 的更多信息,请参阅如何跨 Amazon Web Services 区域 自动复制 Amazon Secrets Manager 中的密钥
。
通常,所选的辅助集群会在几分钟内代入主角色。一旦新的主区域的写入器数据库实例可用,您就可以将应用程序连接到该实例并恢复工作负载。Aurora 提升新的主集群后,它会自动重建所有其他辅助区域集群。
由于 Aurora 全球数据库使用异步复制,因此每个辅助区域的复制滞后可能会有所不同。Aurora 重建这些辅助区域,使其具有与新的主区域集群完全相同的时间点数据。完成重建任务的持续时间可能需要几分钟到几小时,具体取决于存储卷的大小和区域之间的距离。当辅助区域集群从新的主区域完成重建后,它们就可供进行读取访问了。
一旦新的主写入器已提升并可用,新的主区域的集群就可以处理 Aurora 全球数据库的读取和写入操作。
如果使用的是全局端点,则无需更改应用程序中的连接设置。验证 DNS 更改已传播,并且您可以连接新的主集群并对其执行写入操作。然后,您可以恢复应用程序的完整运行。
如果不使用全局端点,请务必更改应用程序的端点,以使用新提升的主数据库集群的集群端点。如果您在创建 Aurora 全局数据库时接受了提供的名称,则可以在应用程序中从提升集群的终端节点字符串中删除 -ro 以更改终端节点。
例如,辅助集群的终端节点 my-global.cluster-ro-aaaaaabbbbbb.us-west-1.rds.amazonaws.com 将在该集群提升为主集群时变为终端节点 my-global.cluster-aaaaaabbbbbb.us-west-1.rds.amazonaws.com。
如果您使用的是 RDS 代理,请确保将应用程序的写入操作重定向到与新的主集群关联的代理的相应读取/写入端点。此代理端点可能是默认端点或自定义读/写端点。有关更多信息,请参阅 RDS 代理端点如何与全局数据库配合使用。
为了还原全球数据库集群的原始拓扑,Aurora 会监控旧主区域的可用性。一旦该区域正常运行并再次可用,Aurora 就会自动将其作为辅助区域重新添加到全球集群中。在旧的主区域中创建新的存储卷之前,Aurora 会尝试在出现故障时拍摄旧存储卷的快照。它这样做是为了让您可以用它来恢复任何丢失的数据。如果此操作成功,Aurora 将创建一个名为 rds:unplanned-global-failover- 的快照。您可以在 Amazon Web Services 管理控制台的快照部分中找到该快照。还可以在 DescribeDBClusterSnapshots API 操作返回的信息中看到列出的此快照。name-of-old-primary-DB-cluster-timestamp
注意
旧存储卷的快照是系统快照,受旧的主集群上配置的备份保留期限制。要在保留期之外保留此快照,可以复制它以另存为手动快照。要了解有关复制快照的更多信息(包括定价),请参阅数据库集群快照复制。
还原原始拓扑后,您可以通过在对业务和工作负载最有意义的时候执行切换操作,将全球数据库失效自动恢复到原始主区域。为此,请按照对 Amazon Aurora Global Database 执行切换中的步骤进行操作。
您可以使用 Amazon Web Services 管理控制台、Amazon CLI 或 RDS API 对 Aurora Global Database 进行失效转移。
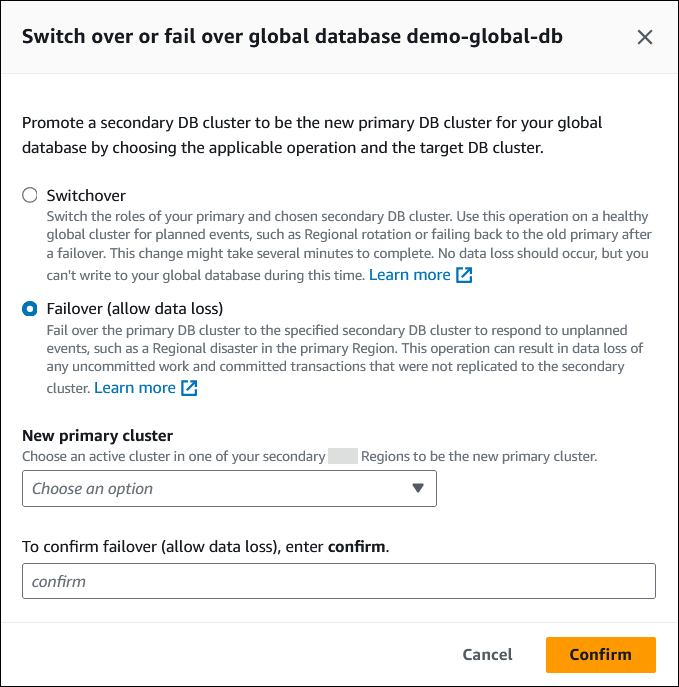
在 Aurora 全球数据库上执行托管式失效转移
登录 Amazon Web Services 管理控制台 并通过以下网址打开 Amazon RDS 控制台:https://console.aws.amazon.com/rds/
。 -
选择数据库,然后找到要进行失效转移的 Aurora 全局数据库。
-
从操作菜单中选择切换或失效转移全球数据库。
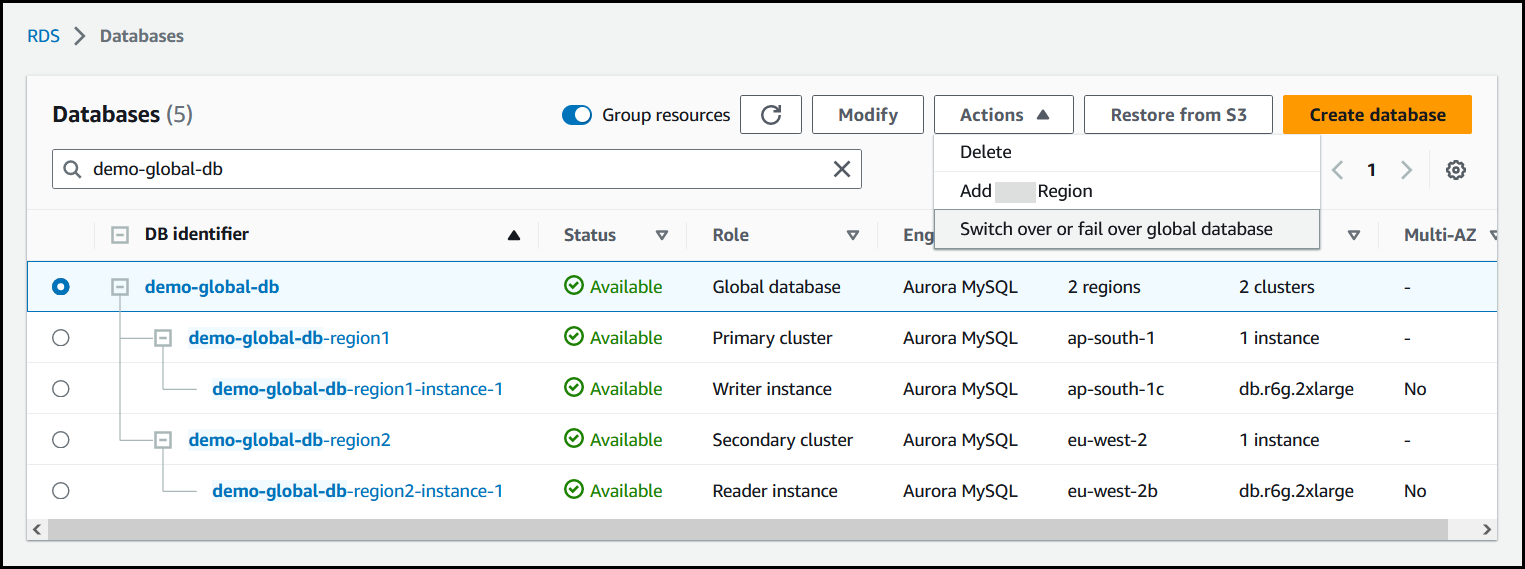
-
选择失效转移(允许数据丢失)。
-
对于新的主集群,选择其中一个辅助 Amazon Web Services 区域中的活动集群作为新的主集群。
-
输入
confirm,然后选择确认。
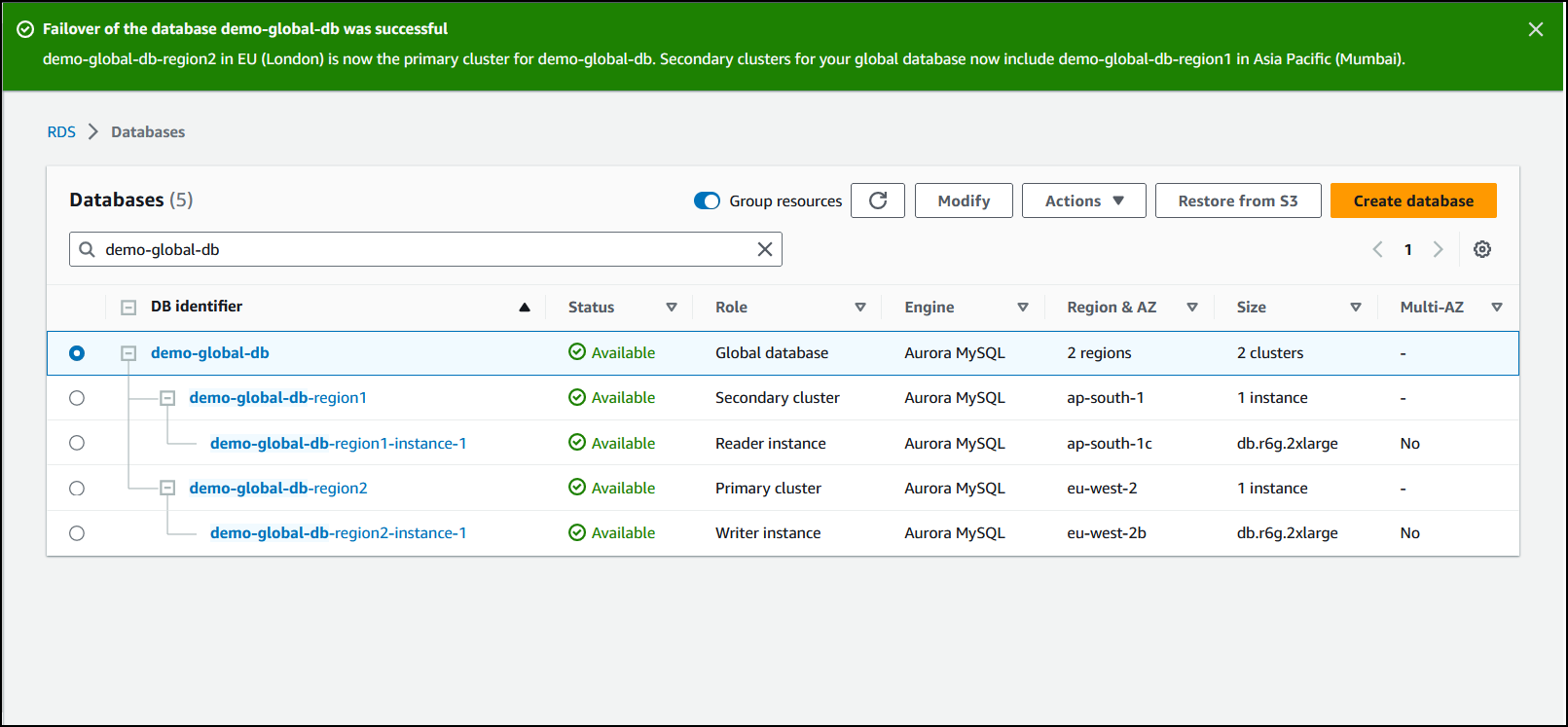
失效转移完成后,您可以在数据库列表中查看 Aurora 数据库集群及其当前状态,如下图所示。
在 Aurora 全球数据库上执行托管式失效转移
使用 failover-global-cluster CLI 命令对 Aurora Global Database 进行失效转移。使用命令,传递下列参数的值。
-
--region– 指定一个 Amazon Web Services 区域,这是您希望成为 Aurora 全球数据库的新主数据库集群的辅助数据库集群正在运行的位置。 -
--global-cluster-identifier– 指定 Aurora 全局数据库的名称。 -
--target-db-cluster-identifier– 指定要提升为 Aurora 全球数据库的新主数据库集群的 Aurora 数据库集群的 Amazon 资源名称(ARN)。 -
--allow-data-loss– 显式使其成为失效转移操作而不是切换操作。如果异步复制组件尚未完成将所有复制的数据发送到辅助区域,则失效转移操作可能会导致一些数据丢失。
对于 Linux、macOS 或 Unix:
aws rds --regionregion_of_selected_secondary\ failover-global-cluster --global-cluster-identifierglobal_database_id\ --target-db-cluster-identifierarn_of_secondary_to_promote\ --allow-data-loss
对于 Windows:
aws rds --regionregion_of_selected_secondary^ failover-global-cluster --global-cluster-identifierglobal_database_id^ --target-db-cluster-identifierarn_of_secondary_to_promote^ --allow-data-loss
要对 Aurora Global Database 进行失效转移,请运行 FailoverGlobalCluster API 操作。
执行 Aurora 全球数据库的手动失效转移
在某些情况下,您可能无法使用托管式失效转移过程。例如,如果您的主数据库集群和辅助数据库集群运行的引擎版本不兼容。在这种情况下,您可以按照此手动过程,失效转移到目标辅助区域。
提示
我们建议您在实施此过程之前先了解此过程。准备好计划,以便在区域级问题初见端倪时快速处理。通过定期使用 Amazon CloudWatch 来跟踪辅助集群的滞后时间,您就可以确定复制滞后最少的辅助区域。确保测试计划,以检查您的过程是否完整和准确,并确保员工在灾难恢复失效转移真正发生之前接受了相关培训以执行此失效转移过程。
在主区域发生计划外停机后,手动失效转移到辅助集群
-
停止向停机的 Amazon Web Services 区域 中的主 Aurora 数据库集群发出 DML 语句和其他写入操作。
-
从辅助 Amazon Web Services 区域 中标识作为新的主数据库集群的 Aurora 数据库集群。如果您的 Aurora 全球数据库中有两个或更多辅助 Amazon Web Services 区域,请选择复制滞后最少的辅助集群。
-
从 Aurora 全局数据库分离您所选的辅助数据库集群。
从 Aurora Global Database 删除备用数据库集群会立即停止从主数据库集群到该备用数据库集群的复制过程,并会将其提升为拥有完全读/写功能的独立预置的 Aurora 数据库集群。与该停机区域中的主集群关联的任何其他辅助 Aurora 数据库集群仍然可用,并且可以接受应用程序的调用。它们还会消耗资源。由于您要重新创建 Aurora 全局数据库,请先删除其他备用数据库集群,再在后续步骤中创建新的 Aurora 全局数据库。这样做可以避免 Aurora Global Database 中数据库集群之间的数据不一致(脑裂问题)。
有关分离的详细步骤,请参阅 从 Amazon Aurora Global Database 删除集群。
-
重新配置应用程序,使用新的终端节点将所有写入操作发送到现在的独立 Aurora 数据库集群。如果您在创建 Aurora 全局数据库时接受了提供的名称,则可以在应用程序中从集群的终端节点字符串中删除
-ro以更改终端节点。例如,辅助集群的终端节点
my-global.cluster-ro-aaaaaabbbbbb.us-west-1.rds.amazonaws.com将在该集群从 Aurora 全局数据库分离时变为终端节点my-global.cluster-aaaaaabbbbbb.us-west-1.rds.amazonaws.com。在下一步中,当您开始向 Aurora 数据库集群添加区域时,该数据库集群将成为新的 Aurora Global Database 的主集群。
如果您使用的是 RDS 代理,请确保将应用程序的写入操作重定向到与新的主集群关联的代理的相应读取/写入端点。此代理端点可能是默认端点或自定义读/写端点。有关更多信息,请参阅 RDS 代理端点如何与全局数据库配合使用。
-
向数据库集群添加 Amazon Web Services 区域。执行此操作后,从主数据库集群到辅助数据库集群的复制过程将会开始。有关添加区域的详细步骤,请参阅 将 Amazon Web Services 区域 添加到 Amazon Aurora Global Database。
-
根据需要添加更多 Amazon Web Services 区域,以重新创建为了支持应用程序所需的拓扑。
确保在进行这些更改之前、期间和之后,将应用程序写入发送到正确的 Aurora 数据库集群。这样做可以避免 Aurora Global Database 中数据库集群之间的数据不一致(脑裂问题)。
如果您为响应 Amazon Web Services 区域中的中断进行了重新配置,则可以在解决中断后再次将 Amazon Web Services 区域设置为主区域。为此,您需要将旧的 Amazon Web Services 区域添加到新的全球数据库中,然后使用切换过程以切换其角色。您的 Aurora 全球数据库必须使用支持切换的 Aurora PostgreSQL 或 Aurora MySQL 版本。有关更多信息,请参阅 对 Amazon Aurora Global Database 执行切换。
管理基于 Aurora PostgreSQL 的全局数据库的 RPO
通过基于 Aurora PostgreSQL 的全球数据库,您可以使用 rds.global_db_rpo 参数管理 Aurora 全球数据库的恢复点目标(RPO)。RPO 表示在停机时可能丢失的最大数据量。
为基于 Aurora PostgreSQL 的全局数据库设置 RPO 后,Aurora 会监控所有辅助集群的 RPO 滞后时间,以确保至少有一个辅助集群保留在目标 RPO 窗口内。RPO 滞后时间是另一个基于时间的指标。
当您的数据库在发生故障转移后在新 Amazon Web Services 区域 中恢复运行时,将使用 RPO。Aurora 会按如下方式评估 RPO 和 RPO 滞后时间,以便在主数据库集群上提交(或阻止)交易:
-
如果至少有一个辅助数据库集群的 RPO 滞后时间小于 RPO,则提交事务。
-
如果所有辅助数据库集群的 RPO 滞后时间大于 RPO,则阻止事务。它还会将事件记录到 PostgreSQL 日志文件中,并发出显示被阻止的会话的“等待”事件。
换言之,如果所有辅助集群都落后于目标 RPO,则 Aurora 会在主集群中暂停,直到至少一个辅助集群与目标 RPO 同步。一旦至少一个备用数据库集群的滞后时间小于 RPO,就会恢复并提交暂停的事务。结果是在满足 RPO 条件之后,才能提交事务。
rds.global_db_rpo 参数是动态的。如果您决定在滞后充分减少之前不希望所有写入事务都停滞不前,则可以快速将其重置。在这种情况下,Aurora 会在短暂延迟后识别并实施更改。
重要
在只有两个 Amazon 区域的全局数据库中,我们建议在辅助区域的参数组中保留 rds.global_db_rpo 参数的默认值。否则,由于主 Amazon 区域丢失而执行失效转移可能会导致 Aurora 暂停事务。相反,请等待 Aurora 在旧的故障 Amazon 区域中完成集群重建,然后更改此参数以实施最大 RPO。
如果按下述步骤设置此参数,则还可以监控其生成的指标。您可以通过使用 psql 或其他工具查询 Aurora 全局数据库的主数据库集群并获取基于 Aurora PostgreSQL 的全局数据库操作的详细信息来执行此操作。要了解如何操作,请参阅监控基于 Aurora PostgreSQL 的全局数据库。
设置恢复点目标
该 rds.global_db_rpo 参数控制 PostgreSQL 数据库的 RPO 设置。Aurora PostgreSQL 支持此参数。rds.global_db_rpo 的有效值的范围是从 20 秒到 2147483647 秒(68 年)。请选择符合您的业务需求和使用案例的真实值。例如,您可能希望最多为 RPO 留出 10 分钟的时间,在这种情况下,可以将值设置为 600。
您可以使用Amazon Web Services 管理控制台、Amazon CLI 或 RDS API 为基于 Aurora PostgreSQL 的全局数据库设置此值。
设置 RPO
登录 Amazon Web Services 管理控制台 并通过以下网址打开 Amazon RDS 控制台:https://console.aws.amazon.com/rds/
。 -
选择 Aurora 全局数据库的主集群,然后打开 Configuration(配置)选项卡以查找其数据库集群参数组。例如,运行 Aurora PostgreSQL 11.7 的主数据库集群的默认参数组为
default.aurora-postgresql11。参数组无法直接编辑。您可以改而执行以下操作:
-
使用适当的默认参数组作为起点创建自定义数据库集群参数组。例如,基于
default.aurora-postgresql11创建自定义数据库集群参数组。 -
在自定义数据库参数组中,设置 rds.global_db_rpo 参数的值以符合您的使用案例。有效值的范围是从 20 秒到最大整数值 2147483647(68 年)。
-
请将修改后的数据库集群参数组应用于 Aurora 数据库集群。
-
有关更多信息,请参阅“在 Amazon Aurora 中修改数据库集群参数组中的参数”。
要设置 rds.global_db_rpo 参数,请使用 modify-db-cluster-parameter-group CLI 命令。在此命令中,请指定主集群参数组的名称和 RPO 参数的值。
以下示例将名为 my_custom_global_parameter_group 的主数据库集群参数组的 RPO 设置为 600 秒(10 分钟)。
对于 Linux、macOS 或 Unix:
aws rds modify-db-cluster-parameter-group \ --db-cluster-parameter-group-namemy_custom_global_parameter_group\ --parameters "ParameterName=rds.global_db_rpo,ParameterValue=600,ApplyMethod=immediate"
对于 Windows:
aws rds modify-db-cluster-parameter-group ^ --db-cluster-parameter-group-namemy_custom_global_parameter_group^ --parameters "ParameterName=rds.global_db_rpo,ParameterValue=600,ApplyMethod=immediate"
要修改 rds.global_db_rpo 参数,请使用 Amazon RDS ModifyDBClusterParameterGroup API 操作。
查看恢复点目标
全局数据库的恢复点目标 (RPO) 存储每个数据库集群的 rds.global_db_rpo 参数中。您可以连接到要查看的辅助集群的终端节点,并使用 psql 查询该值的实例。
show rds.global_db_rpo;db-name=>
如果未设置此参数,查询将返回以下内容:
rds.global_db_rpo
-------------------
-1
(1 row)下一个响应来自 RPO 设置为 1 分钟的辅助数据库集群。
rds.global_db_rpo
-------------------
60
(1 row) 您还可以使用 CLI 获取集群的所有 rds.global_db_rpo 参数的值,以便了解 user 是否在任何 Aurora 数据库集群上处于活动状态。
对于 Linux、macOS 或 Unix:
aws rds describe-db-cluster-parameters \ --db-cluster-parameter-group-namelab-test-apg-global\ --source user
对于 Windows:
aws rds describe-db-cluster-parameters ^ --db-cluster-parameter-group-namelab-test-apg-global* --source user
该命令会对所有 user 参数(非 default-engine 或 system 数据库集群参数)返回与以下内容类似的输出。
{
"Parameters": [
{
"ParameterName": "rds.global_db_rpo",
"ParameterValue": "60",
"Description": "(s) Recovery point objective threshold, in seconds, that blocks user commits when it is violated.",
"Source": "user",
"ApplyType": "dynamic",
"DataType": "integer",
"AllowedValues": "20-2147483647",
"IsModifiable": true,
"ApplyMethod": "immediate",
"SupportedEngineModes": [
"provisioned"
]
}
]
}
要了解有关查看集群参数组的参数的更多信息,请参阅 在 Amazon Aurora 中查看数据库集群参数组的参数值。
禁用恢复点目标
要禁用 RPO,请重置 rds.global_db_rpo 参数。您可以使用 Amazon Web Services 管理控制台、Amazon CLI 或 RDS API 重置参数。
禁用 RPO
登录 Amazon Web Services 管理控制台 并通过以下网址打开 Amazon RDS 控制台:https://console.aws.amazon.com/rds/
。 -
在导航窗格中,选择参数组。
-
在列表中,选择您的主数据库集群参数组。
-
选择编辑参数。
-
选择 rds.global_db_rpo 参数旁边的框。
-
选择 Reset (重置)。
-
当屏幕显示 Reset parameters in DB parameter group (重置数据库参数组中的参数) 时,选择 Reset parameters (重置参数)。
有关如何使用控制台重置参数的更多信息,请参阅在 Amazon Aurora 中修改数据库集群参数组中的参数。
要重置 rds.global_db_rpo 参数,请使用 reset-db-cluster-parameter-group 命令。
对于 Linux、macOS 或 Unix:
aws rds reset-db-cluster-parameter-group \ --db-cluster-parameter-group-nameglobal_db_cluster_parameter_group\ --parameters "ParameterName=rds.global_db_rpo,ApplyMethod=immediate"
对于 Windows:
aws rds reset-db-cluster-parameter-group ^ --db-cluster-parameter-group-nameglobal_db_cluster_parameter_group^ --parameters "ParameterName=rds.global_db_rpo,ApplyMethod=immediate"
要重置 rds.global_db_rpo 参数,请使用 Amazon RDS API ResetDBClusterParameterGroup 操作。