将 SQL Server 数据库迁移到 Babelfish for Aurora PostgreSQL
可以使用 Babelfish for Aurora PostgreSQL 将 SQL Server 数据库迁移到 Amazon Aurora PostgreSQL 数据库集群。在迁移之前,请查看 将 Babelfish 与单个数据库或多个数据库结合使用。
迁移过程概述
以下摘要列出了成功迁移 SQL Server 应用程序和使之与 Babelfish 配合使用所需的步骤:有关可用于导出和导入流程的工具的信息以及更多详细信息,请参阅用于从 SQL Server 迁移到 Babelfish 的导入/导出工具。要加载数据,我们建议将 Amazon DMS 与 Aurora PostgreSQL 数据库集群结合用作目标端点。
-
在开启 Babelfish 的情况下创建新的 Aurora PostgreSQL 数据库集群。要了解如何操作,请参阅创建 Babelfish for Aurora PostgreSQL 数据库集群。
要导入从 SQL Server 数据库导出的各种 SQL 构件,请使用 SQL Server 工具(例如 sqlcmd
)连接到 Babelfish 集群。有关更多信息,请参阅 使用 SQL Server 客户端连接到数据库集群。 -
在要迁移的 SQL Server 数据库上,导出数据定义语言 (DDL)。DDL 是一种 SQL 代码,用于描述包含用户数据(如表、索引和视图)和用户编写的数据库代码(例如存储过程、用户定义的函数和触发器)的数据库对象。
有关更多信息,请参阅 使用 SQL Server Management Studio (SSMS) 迁移到 Babelfish。
-
运行评估工具来评估可能需要进行的任何更改的范围,以便 Babelfish 能够有效地支持在 SQL Server 上运行的应用程序。有关更多信息,请参阅 评估和处理 SQL Server 和 Babelfish 之间的差异。
-
查看 Amazon DMS 目标端点限制并根据需要更新 DDL 脚本。有关更多信息,请参阅 Using Babelfish for Aurora PostgreSQL as a target 中的“Limitations to using a PostgreSQL target endpoint with Babelfish tables”。
-
在新的 Babelfish 数据库集群上,在指定的 T-SQL 数据库中运行 DDL,以仅创建具有主键约束条件的模式、用户定义的数据类型和表。
-
使用 Amazon DMS 将数据从 SQL Server 迁移到 Babelfish 表。要使用 SQL Server 变更数据捕获或 SQL 复制进行持续复制,请使用 Aurora PostgreSQL 而不是 Babelfish 作为端点。为此,请参阅使用适用于 Aurora PostgreSQL 的 Babelfish 作为 Amazon Database Migration Service 的目标。
-
数据加载完成后,在 Babelfish 集群上创建支持应用程序的所有剩余 T-SQL 对象。
-
重新配置客户端应用程序以连接到 Babelfish 端点而不是 SQL Server 数据库。有关更多信息,请参阅 连接到 Babelfish 数据库集群。
-
根据需要修改应用程序并重新测试。有关更多信息,请参阅 适用于 Aurora PostgreSQL 的 Babelfish 与 SQL Server 之间的区别。
您仍然需要评估客户端 SQL 查询。从 SQL Server 实例生成的架构仅转换服务器端 SQL 代码。我们建议您采取以下步骤:
-
通过将 SQL Server Profiler 与 TSQL_Replay 预定义模板结合使用来捕获客户端查询。此模板捕获 T-SQL 语句信息,然后可以重播这些信息以进行迭代优化和测试。您可以从 SQL Server Management Studio 的 Tools(工具)菜单中启动此 Profiler。选择 SQL Server Profiler 以打开此 Profiler 并选择 TSQL_Replay 模板。
要用于 Babelfish 迁移,请开始跟踪,然后使用功能测试运行应用程序。此 Profiler 捕获 T-SQL 语句。当您完成测试时,停止跟踪。使用客户端查询将结果保存到 XML 文件中 [File(文件)> Save as(另存为)> Trace XML File for Replay(跟踪 XML 文件以便重播)]。
有关更多信息,请参阅 Microsoft 文档中的 SQL Server Profiler
。有关 TSQL_Replay 模板的更多信息,请参阅 SQL Server Profiler 模板 。 -
对于具有复杂客户端 SQL 查询的应用程序,我们建议您使用 Babelfish Compass 分析这些查询以了解 Babelfish 兼容性。如果分析表明客户端 SQL 语句包含不受支持的 SQL 功能,请查看客户端应用程序中的 SQL 方面,并根据需要进行修改。
-
您也可以将 SQL 查询捕获为扩展事件(.xel 格式)。为此,请使用 SSMS XEvent Profiler。生成 .xel 文件后,将 SQL 语句提取到 .xml 文件中,然后 Compass 可以对其进行处理。有关更多信息,请参阅 Microsoft 文档中的 使用 SSMS XEvent Profler
。
当您对迁移的应用程序所需的所有测试、分析以及任何修改感到满意时,您可以开始将 Babelfish 数据库用于生产环境中。为此,请停止原始数据库,并重新导向实时客户端应用程序以使用 Babelfish TDS 端口。
注意
Amazon DMS 现在支持从 Babelfish 复制数据。有关更多信息,请参阅 Amazon DMS now supports Babelfish for Aurora PostgreSQL as a source
评估和处理 SQL Server 和 Babelfish 之间的差异
为了获得最佳结果,我们建议您在将 SQL Server 数据库应用程序实际迁移到 Babelfish 之前,先评估生成的 DDL/DML 和客户端查询代码。根据 Babelfish 的版本和应用程序实现的 SQL Server 的特定功能,您可能需要重构应用程序或使用替代方案来获得 Babelfish 中尚未完全支持的功能。
-
要评估 SQL Server 应用程序代码,请在生成的 DDL 上使用 Babelfish Compass 来确定 Babelfish 支持多少个 T-SQL 代码。确定在 Babelfish 上运行之前可能需要修改的 T-SQL 代码。有关此工具的更多信息,请参阅 GitHub 上的 Babelfish Compass 工具
。 注意
Babelfish Compass 是一种开源工具。请通过 GitHub 而不是 Amazon Support 报告 Babelfish Compass 的任何问题。
您可以在 SQL Server Management Studio(SSMS)中使用 Generate Script Wizard(生成脚本向导)来生成由 Babelfish Compass 评估的 SQL 文件。我们建议采取以下步骤来简化评估。
-
在 Choose Objects(选择对象)页面上,选择 Script entire database and all database objects(为整个数据库和所有数据库对象编写脚本)。
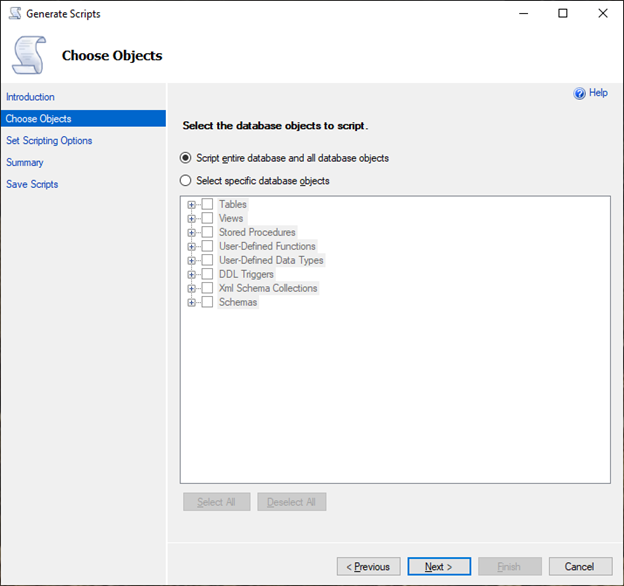
-
对于 Set Scripting Options(设置脚本选项),选择 Save as script file(另存为脚本文件)作为 Single script file(单个脚本文件)。
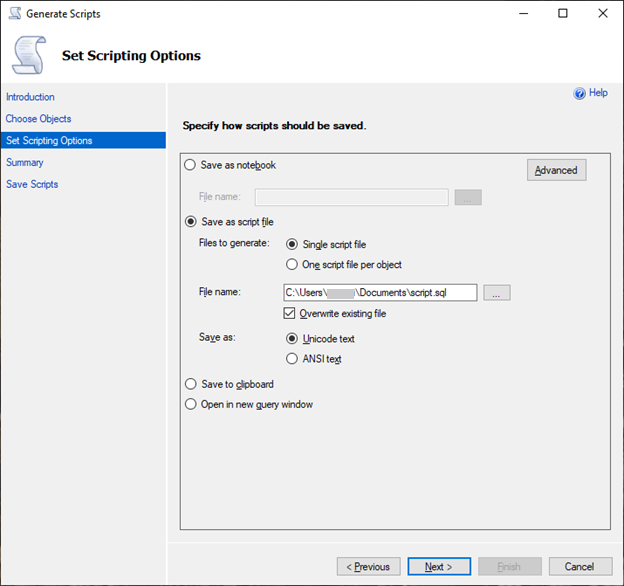
-
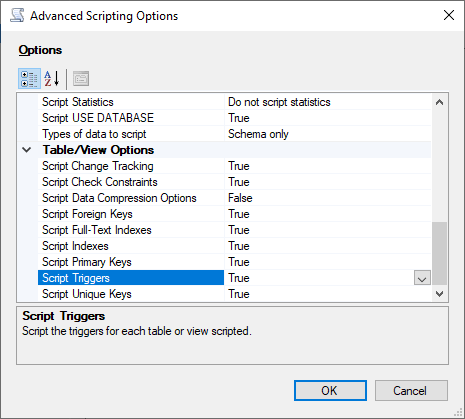
选择 Advanced(高级)可更改原定设置脚本选项,以识别在进行全面评估时通常设置为 false 的功能:
-
脚本将跟踪更改为 True
-
脚本将全文索引设置为 True
-
脚本将触发器设置为 True
-
脚本将登录设置为 True
-
脚本将拥有者设置为 True
-
脚本将对象级权限设置为 True
-
脚本将排序规则设置为 True
-
-
执行向导中的剩余步骤来生成文件。
用于从 SQL Server 迁移到 Babelfish 的导入/导出工具
我们建议使用 Amazon DMS 作为从 SQL Server 迁移到 Babelfish 的主要工具。但是,Babelfish 支持其他几种使用 SQL Server 工具迁移数据的方式,其中包括以下各项。
-
适用于所有版本的 Babelfish 的 SQL Server Integration Services(SSIS)。有关更多信息,请参阅使用 SSIS 和 Babelfish 从 SQL Server 迁移到 Aurora PostgreSQL
。 -
使用适用于 Babelfish 版本 2.1.0 及更高版本的 SSMS 导入/导出向导。此工具可通过 SSMS 获得,但也可作为独立工具使用。有关更多信息,请参阅 Microsoft 文档中的欢迎使用 SQL Server 导入和导出向导
。 -
Microsoft 批量数据复制程序(bcp)实用程序可让您以您指定的格式将数据从 Microsoft SQL Server 实例复制到数据文件中。有关更多信息,请参阅 Microsoft 文档中的 bcp 实用程序
。Babelfish 现在支持使用 BCP 客户端进行数据迁移,而 bcp 实用程序现在支持 -E标志(用于身份列)和 -b 标志(用于批量插入)。不支持某些 bcp 选项,包括-C、-T、-G、-K、-R、-V和-h。
使用 SQL Server Management Studio (SSMS) 迁移到 Babelfish
我们建议为每种特定的对象类型生成单独的文件。您可以先使用 SSMS 中的 Generate Scripts(生成脚本)向导来处理每组 DDL 语句,然后将对象按组进行修改,以修复评估期间发现的任何问题。
执行这些步骤,使用 Amazon DMS 或其他数据迁移方法迁移数据。请先运行这些创建脚本类型,以便更好、更快地在 Aurora PostgreSQL 中的 Babelfish 表上加载数据。
-
运行
CREATE SCHEMA语句。 -
运行
CREATE TYPE语句以创建用户定义的数据类型。 -
使用主键或唯一约束运行基本
CREATE TABLE语句。
使用建议的导入/导出工具执行数据加载。运行以下步骤的修改后脚本以添加剩余的数据库对象。您需要创建表语句来运行这些脚本,以获取约束、触发器和索引。脚本生成后,删除创建表语句。
-
针对检查约束、外键约束、原定设置约束运行
ALTER TABLE语句。 -
运行
CREATE TRIGGER语句。 -
运行
CREATE INDEX语句。 -
运行
CREATE VIEW语句。 -
运行
CREATE STORED PROCEDURE语句。
为每种对象类型生成脚本
使用以下步骤通过 SSMS 中的生成脚本向导来创建基本的创建表语句。按照同样的步骤为不同的对象类型生成脚本。
-
连接到您的现有 SQL Server 实例。
-
打开数据库名称的上下文(右键单击)菜单。
-
选择 Tasks(任务),然后选择 Generate Scripts...(生成脚本...)。
-
在 Choose Objects(选择对象)窗格中,选择 Select specific database objects(选择特定数据库对象)。选择 Tables(表),然后选择所有表。选择下一步以继续。
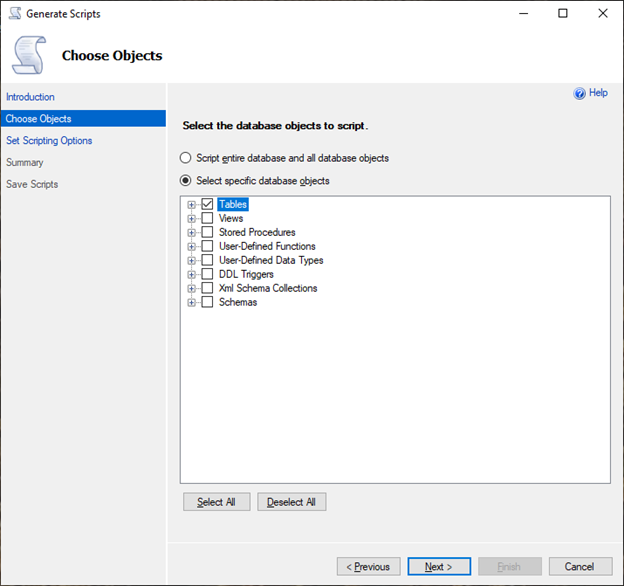
-
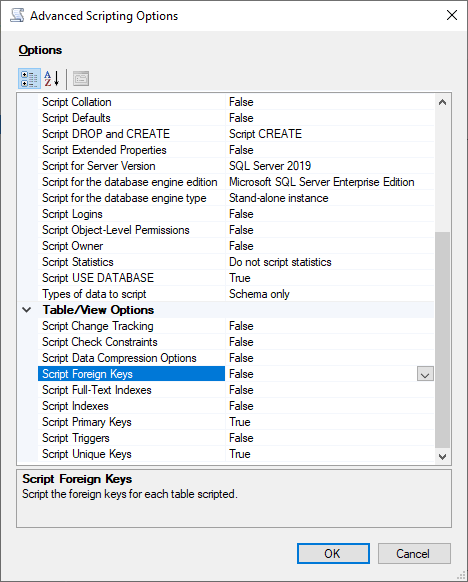
在 Set Scripting Options(设置脚本选项)页面上,选择 Advanced(高级)以打开 Options(选项)设置。要生成基本的创建表语句,请更改以下原定设置值:
-
脚本将原定设置设为 False。
-
脚本将扩展属性设置为 False。Babelfish 不支持扩展属性。
-
脚本将检查约束设置为 False。脚本将外键设置为 False。
-
-
选择确定。
-
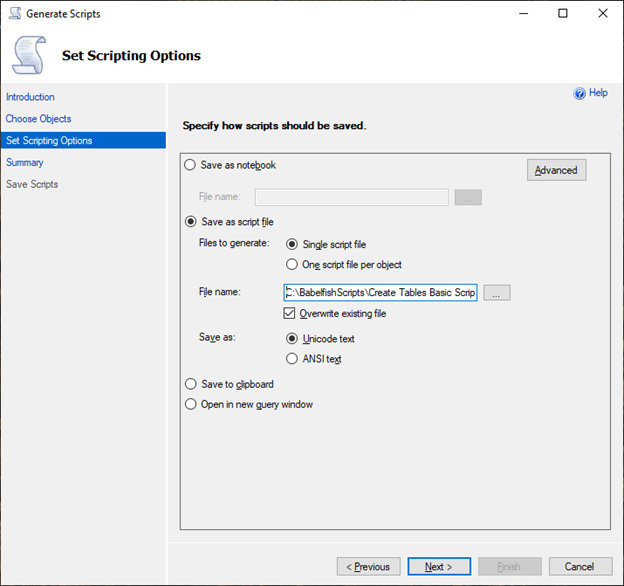
在 Set Scripting Options(设置脚本选项)页上,选择 Save as script file(另存为脚本文件),然后选择 Single script file(单个脚本文件)选项。输入 File name(文件名)。
-
选择 Next(下一步)以查看 Summary wizard(摘要向导)页。
-
选择 Next(下一步)以启动脚本生成。
您可以继续在向导中为其他对象类型生成脚本。不是在保存文件后选择 Finish(完成),而是选择 Previous(上一步)按钮三次以返回 Choose Objects(选择对象)页。然后重复向导中的步骤,为其他对象类型生成脚本。