本地二级索引
某些应用程序只需要使用基表的主键查询数据。但是,在某些情况下,替代排序键可能会有所帮助。要为您的应用程序选择排序键,您可以在 Amazon DynamoDB 表上创建一个或多个本地二级索引,然后对这些索引发出 Query 或 Scan 请求。
主题
场景:使用本地二级索引
例如,请考虑 Thread 表。此表对于 Amazon 论坛
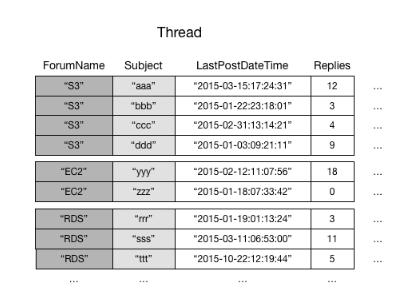
DynamoDB 连续存储具有相同分区键值的所有项目。在本例中,给定特定 ForumName,Query 操作可以立即找到该论坛的所有话题。在具有相同分区键值的项目组中,按排序键值对项目进行排序。如果排序键 (Subject),DynamoDB 可以缩小返回的结果范围-例如,返回“S3”论坛中 Subject 以字母“a”开始的所有话题。
某些请求可能需要更复杂的数据访问模式。例如:
-
哪些论坛主题获得的查看和回复最多?
-
特定论坛中的哪个主题具有最多的消息?
-
在特定时间段内,特定论坛上发布了多少主题?
要回答这些问题,Query 操作是不够的。相反,您将不得不Scan整个表。对于包含数百万个项目的表,这将占用大量预置读取吞吐量,并需要很长时间才能完成。
但是,您可以在非键属性上指定一个或多个本地二级索引,例如 Replies 或 LastPostDateTime。
本地二级索引为给定分区键值维护替代排序键。本地二级索引还包含其基表中部分或全部属性的副本。您可以指定在创建表时将哪些属性投影到本地二级索引中。本地二级索引数据按照基表相同分区键组织,但排序键不同。这样,您就可以跨不同维度高效地访问数据项。为获得更高的查询或扫描灵活性,您可以为每个表创建最多 5 个本地二级索引。
假设应用程序需要查找过去三个月内在某个论坛中发布的所有话题。如果没有本地二级索引,应用程序将不得不 Scan 整个 Thread 表并放弃任何未在指定时间范围内的帖子。使用本地二级索引,Query 操作可以使用 LastPostDateTime 作为排序键,快速查找数据。
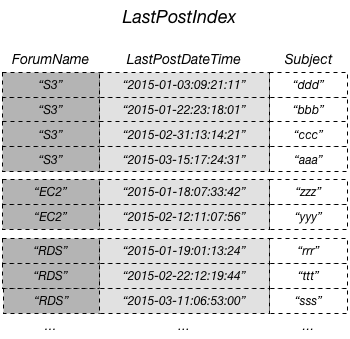
下图显示了名为 LastPostIndex 的本地二级索引。请注意,分区键与 Thread 表相同,但排序键是 LastPostDateTime。
每个本地二级索引必须符合以下条件:
-
分区键与其基表的分区键相同。
-
排序键仅由一个标量属性组成。
-
基表的排序键将投影到索引中,其中它充当非键属性。
在本示例中,分区键是 ForumName,本地二级索引的排序键为 LastPostDateTime。此外,基表中的排序键值(在本示例中,Subject)投影到索引中,但它不是索引键的一部分。如果应用程序需要基于 ForumName 和 LastPostDateTime 的列表,它可以对 LastPostIndex 发出 Query 请求。查询结果按照 LastPostDateTime 排序,并且可以按升序或降序排序返回。查询还可以应用关键条件,例如,仅返回在特定的时间范围内具有 LastPostDateTime 的项目。
每个本地二级索引自动包含其基表中的分区和排序键;您可以选择将非键属性投影到索引中。当您查询索引时,DynamoDB 便可高效地检索这些已投影的属性。查询本地二级索引时,查询还可以检索未投影到索引的属性。DynamoDB 会自动从基表中提取这些属性,但延迟更大,预置吞吐量成本也更高。
对于任何本地二级索引,每个不同分区键值最多可以存储 10 GB 的数据。此数字包括基表中的所有项目,以及索引中具有相同分区键值的所有项目。有关更多信息,请参阅 本地二级索引中的项目集合。
属性投影
对于 LastPostIndex,应用程序可以使用 ForumName 和 LastPostDateTime 作为查询条件。但是,要检索任何其他属性,DynamoDB 必须对 Thread 表执行额外读取操作。这些额外读取称为获取,可以增加查询所需的预置吞吐量总量。
假设您希望使用“S3”中所有话题的列表以及每个话题的回复数量填充一个网页,并按最近回复开始的最后一个回复日期/时间排序。要填充此列表,您需要以下属性:
-
Subject -
Replies -
LastPostDateTime
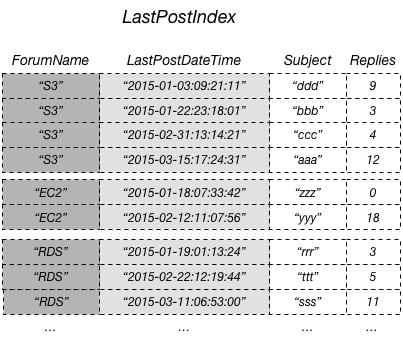
查询这些数据并避免获取操作的最有效方法是将 Replies 属性从表投影到本地二级索引,如此图所示。
投影是从表复制到二级索引的属性集。表的分区键和排序键始终投影到索引中;您可以投影其他属性以支持应用程序的查询要求。当您查询索引时,Amazon DynamoDB 可以访问投影中的任何属性,就像这些属性位于自己的表中一样。
创建二级索引时,需要指定将投影到索引中的属性。DynamoDB 为此提供了三种不同的选项:
-
KEYS_ONLY – 索引中的每个项目仅包含表的分区键、排序键值以及索引键值。
KEYS_ONLY选项会导致最小二级索引。 -
INCLUDE – 除
KEYS_ONLY中描述的属性外,二级索引还包括您指定的其他非键属性。 -
ALL – 二级索引包括源表中的所有属性。由于所有表数据都在索引中复制,因此
ALL投影会产生最大二级索引。
在上图中,非键属性 Replies 投影到 LastPostIndex。应用程序可以查询 LastPostIndex 而不是整个 Thread 表,用 Subject、Replies 和 LastPostDateTime 填充网页。如果请求任何其他非键属性,DynamoDB 将需要从 Thread 表获取这些属性。
从应用程序的角度来看,从基表中获取其他属性是自动且透明的,因此无需重写任何应用程序逻辑。但是,这种读取可以大大降低使用本地二级索引的性能优势。
选择要投影到本地二级索引中的属性时,必须在预置吞吐量成本和存储成本之间做出权衡:
-
如果只需要访问少量属性,同时尽可能降低延迟,就应考虑仅将键属性投影到本地二级索引。索引越小,存储索引所需的成本越少,并且写入成本也会越少。如果您偶尔需要获取属性,则预置吞吐量的成本可能会超过存储这些属性的较长期成本。
-
如果您的应用程序频繁访问某些非键属性,就应考虑将这些属性投影到本地二级索引。本地二级索引的额外存储成本会抵消频繁执行表扫描的成本。
-
如果需要频繁访问大多数非键属性,则可以将这些属性(甚至整个基表)投影到本地二级索引中。这为您提供了最大的灵活性和最低的预置吞吐量消耗,因为不需要提取。但是,如果投影所有属性,您的存储成本将增加,甚至翻倍。
-
如果您的应用程序并不会频繁查询表,但必须要对表中的数据执行大量写入或更新操作,就应考虑投影 KEYS_ONLY。这是最小的本地二级索引,但仍可用于查询活动。
创建本地二级索引
要在表上创建一个或多个本地二级索引,请使用 CreateTable 操作的 LocalSecondaryIndexes 参数。表上的本地二级索引是在创建表时创建的。删除表时,会同时删除该表的任何本地二级索引。
必须指定一个非键属性以充当本地二级索引的排序键。您选择的属性必须是标量 String、Number 或 Binary。不允许使用其他标量类型、文档类型和集合类型。有关数据类型的完整列表,请参阅 数据类型。
重要
对于具有本地二级索引的表,每个分区键值有 10 GB 的大小限制。具有本地二级索引的表可以存储任意数量的项目,只要任何一个分区键值的总大小不超过 10 GB。有关更多信息,请参阅 项目集合大小限制。
您可以将任何数据类型的属性投影到本地二级索引中。这包括标量、文档和集。有关数据类型的完整列表,请参阅 数据类型。
从本地二级索引读取数据
您可以使用 Query 和 Scan 操作从本地二级索引检索项目。GetItem 和 BatchGetItem 操作不能在本地二级索引上使用。
查询本地二级索引
在 DynamoDB 表中,每个项目的组合分区键值和排序键值必须唯一。但是,在本地二级索引中,排序键值不需要对于给定分区键值唯一。如果本地二级索引中有多个具有相同排序键值的项目,则 Query 操作返回具有相同分区键值的所有项目。在响应中,匹配的项目不会以任何特定顺序返回。
您可以使用最终一致性读取或强一致性读取来查询本地二级索引。要指定所需的一致性类型,请使用 Query 操作的 ConsistentRead 参数。从本地二级索引进行的强一致性读取始终返回上次更新的值。如果查询需要从基表中获取其他属性,则这些属性将与索引保持一致。
例
考虑以下数据从 Query 返回,请求来自特定论坛中的讨论主题的数据。
{ "TableName": "Thread", "IndexName": "LastPostIndex", "ConsistentRead": false, "ProjectionExpression": "Subject, LastPostDateTime, Replies, Tags", "KeyConditionExpression": "ForumName = :v_forum and LastPostDateTime between :v_start and :v_end", "ExpressionAttributeValues": { ":v_start": {"S": "2015-08-31T00:00:00.000Z"}, ":v_end": {"S": "2015-11-31T00:00:00.000Z"}, ":v_forum": {"S": "EC2"} } }
在此查询中:
-
DynamoDB 访问
LastPostIndex,使用ForumName分区键查找“EC2”的索引项目。具有此键的所有索引项目都彼此相邻存储,以实现快速检索。 -
在此论坛中,DynamoDB 使用索引来查找匹配指定
LastPostDateTime条件的键。 -
由于
Replies属性投影到索引中,DynamoDB 可以检索此属性,而不会占用任何额外的预置吞吐量。 -
Tags属性不会投影到索引中,因此 DynamoDB 必须访问Thread表并获取此属性。 -
返回结果,按
LastPostDateTime排序。索引条目按分区键值排序,然后按排序键值排序,Query按照存储顺序返回它们。(可以使用ScanIndexForward参数按降序返回结果。)
由于 Tags 属性不会投影到本地二级索引中,DynamoDB 必须占用额外的读取容量单位才能从基表中获取此属性。如果需要经常运行此查询,应将 Tags 投影到 LastPostIndex 以避免从基表提取。但是,如果仅偶尔需要访问 Tags,将 Tags 投影到索引的额外存储成本可能不值得。
扫描本地二级索引
您可以使用 Scan 从本地二级索引检索全部数据。您必须在请求中提供基表名称和索引名称。通过 Scan,DynamoDB 可读取索引中的全部数据并将其返回到应用程序。您还可以请求仅返回部分数据并放弃其余数据。为此,请使用 Scan API 的 FilterExpression 参数。有关更多信息,请参阅 扫描的筛选表达式。
项目写入和本地二级索引
DynamoDB 会自动保持所有本地二级索引与各自的基表同步。应用程序绝不会直接向索引中写入内容。但是,您有必要了解 DynamoDB 如何维护这些索引。
创建本地二级索引时,指定一个属性以作为索引的排序键。您还可以为该属性指定数据类型。这就意味着,无论您何时向基表中写入项目,如果项目定义索引键值,其类型必须匹配索引键架构的数据类型。在 LastPostIndex 的情况下,索引中的 LastPostDateTime 排序键定义为 String 数据类型。如果您尝试向 Thread 表添加项目并为 LastPostDateTime(如 Number)指定其他数据类型,DynamoDB 会因数据类型不匹配而返回 ValidationException。
基表中的项目与本地二级索引中的项目之间不需要一对一的关系。事实上,这种行为对于许多应用程序都是有利的。
相较于索引数量较少的表,拥有较多本地二级索引的表会产生较高的写入活动成本。有关更多信息,请参阅 全局二级索引的预调配吞吐量注意事项。
重要
对于具有本地二级索引的表,每个分区键值有 10 GB 的大小限制。具有本地二级索引的表可以存储任意数量的项目,只要任何一个分区键值的总大小不超过 10 GB。有关更多信息,请参阅 项目集合大小限制。
全局二级索引的预调配吞吐量注意事项
在 DynamoDB 中创建表时,为表的预期工作负载预置读取和写入容量单位。该工作负载包括对表的本地二级索引的读取和写入活动。
要查看预置吞吐量容量的当前值,请参阅 Amazon DynamoDB 定价
读取容量单位
查询本地二级索引时,占用的读取容量单位数取决于访问数据的方式。
与表查询一样,索引查询可以使用最终一致性读取或强一致性读取,具体取决于 ConsistentRead 值。一个强一致性读取占用一个读取容量单位;最终一致性读取只占用一半的读取容量。因此,选择最终一致性读取,可以减少读取容量单位费用。
对于仅请求索引键和投影属性的索引查询,DynamoDB 计算预配置读取活动的方式与对表查询使用的方式相同。唯一不同的是,本次计算基于索引条目的大小,而不是基表中项目的大小。读取容量单位的数量就是返回的所有项目的所有投影属性大小之和;然后结果向上取整至 4 KB 边界。有关 DynamoDB 如何计算预置吞吐量使用情况的更多信息,请参阅 DynamoDB 预置容量模式。
对于读取未投影到本地二级索引的属性的索引查询,DynamoDB 除了从索引读取投影属性之外,还需要从基表中获取这些属性。如果在 Query 操作的 Select 或 ProjectionExpression 参数中加入任何非投影属性,将发生获取。读取会导致查询响应中的额外延迟,并且还会产生更高的预配置吞吐量成本:除了上述从本地二级索引进行读取之外,您还需要为获取的每个基表项目支付读取容量单位费用。此费用用于从表读取每个完整项目,而不仅仅是请求的属性。
Query 操作返回的结果大小上限为 1 MB。这包括所有属性名称的大小和所返回的所有项目的值。但是,如果针对本地二级索引的查询导致 DynamoDB 从基表中获取项目属性,则结果中数据的最大大小可能会较低。在此情况下,结果大小为以下总和:
-
索引中匹配项目的大小,四舍五入到下一个 4 KB。
-
基表中每个匹配项目的大小,每个项目分别向上舍入到下一个 4 KB。
使用此公式,查询操作返回的结果大小上限仍为 1 MB。
例如,请考虑使用每个项目为 300 字节的表。该表有一个本地二级索引,但只有 200 个字节的每个项目投影到索引中。现在假设 Query 此索引,查询需要为每个项目提取表,并且查询返回 4 个项目。DynamoDB 总结了以下几点:
-
索引中匹配项目的大小:200 字节 × 4 个项目 = 800 字节;然后四舍五入为 4 KB。
-
基表中每个匹配项目的大小:(300 字节,四舍五入为 4 KB)×4 个项目 = 16 KB。
因此,结果中数据的总大小为 20 KB。
写入容量单位
添加、更新或删除表中的项目时,更新本地二级索引将占用表的预置写入容量单位。一次写入操作的预置吞吐量总成本是对表执行的写入操作以及更新本地二级索引所占用的写入容量单位之和。
向本地二级索引写入项目的成本取决于多个因素:
-
如果您向定义了索引属性的表中写入新项目,或更新现有的项目来定义之前未定义的索引属性,只需一个写入操作即可将项目放置到索引中。
-
如果对表执行的更新操作更改了索引键属性的值(从 A 更改为 B),就需要执行两次写入操作,一次用于删除索引中之前的项目,另一次用于将新项目放置到索引中。
-
如果索引中已有某一项目,而对表执行的写入操作删除了索引属性,就需要执行一次写入操作删除索引中旧的项目投影。
-
如果更新项目前后索引中没有此项目,此索引就不会额外产生写入成本。
所有这些因素都假定索引中每个项目的大小小于或等于 1 KB 这一项目大小(用于计算写入容量单位)。如果索引条目大于这一大小,就会占用额外的写入容量单位。您可以考虑查询需要返回的属性类型并仅将这些属性投影到索引中,从而最大程度地减少写入成本。
本地二级索引的存储注意事项
当应用程序向表中写入项目时,DynamoDB 会自动将适当的属性子集复制到应包含这些属性的所有本地二级索引。您的 Amazon 账户需要支付在基表中存储项目以及在表的任何本地二级索引中存储属性的费用。
索引项目所占用的空间大小就是以下内容之和:
-
基表的主键 (分区键和排序键) 的大小 (按字节计算)
-
索引键属性的大小(按字节计算)
-
投影的属性(如果有)的大小(按字节计算)
-
每个索引项目 100 字节的开销
要估算本地二级索引的存储要求,您可以估算索引中项目的平均大小,然后乘以索引中的项目数。
如果表包含的某个项目未定义特定属性,但是该属性定义为索引排序键,则 DynamoDB 不会将该项目的任何数据写入到索引中。
本地二级索引中的项目集合
注意
本节仅涉及具有本地二级索引的表。
在 DynamoDB 中,项目集合是指表中具有相同分区键值的项目及其所有本地二级索引的任何组。在本节中使用的示例中,Thread 表的分区键为 ForumName,LastPostIndex 的分区键也是 ForumName。所有具有相同 ForumName 的表和索引项目是同一个项目集合的一部分。例如,在 Thread 表和 LastPostIndex 本地二级索引,有一个论坛的项目集合 EC2 和论坛的不同项目集合 RDS。
下图显示了论坛 S3 的项目集合。
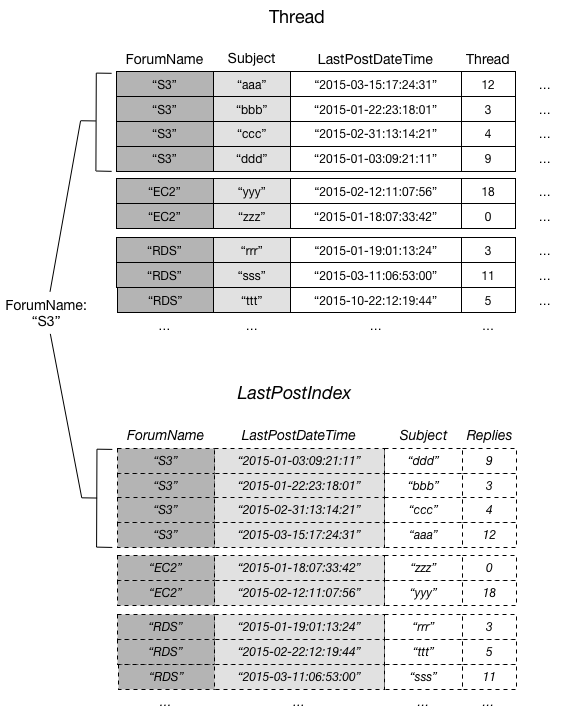
在此图中,项目集合包含 Thread 和 LastPostIndex 中,ForumName 分区键值为“S3”的所有项目。如果表上有其他本地二级索引,那么这些索引中 ForumName 等于“S3”的任何项目也将成为项目集合的一部分。
您可以在 DynamoDB 中使用以下任何操作来返回有关项目集合的信息:
-
BatchWriteItem -
DeleteItem -
PutItem -
UpdateItem -
TransactWriteItems
这些操作中的每个操作都支持 ReturnItemCollectionMetrics 参数。将此参数设置为 SIZE,可以查看有关索引中每个项目集合大小的信息。
例
下面是 Thread 表的 UpdateItem 操作输出示例,ReturnItemCollectionMetrics 设置为 SIZE。更新的项目的 ForumName 值为“EC2”,因此输出包含有关该项目集合的信息。
{ ItemCollectionMetrics: { ItemCollectionKey: { ForumName: "EC2" }, SizeEstimateRangeGB: [0.0, 1.0] } }
SizeEstimateRangeGB 对象显示此项目集合的大小介于 0 到 1 GB 之间。DynamoDB 会定期更新此大小估计值,因此下次修改项目时,数字可能会有所不同。
项目集合大小限制
对于具有一个或多个本地二级索引的表,任何项目集合的最大大小均为 10GB。这不适用于没有本地二级索引的表中的项目集合,也不适用于全局二级索引中的项目集合。只有具有一个或多个本地二级索引的表受影响。
如果项目集合超过 10 GB 限制,则 DynamoDB 可能返回 ItemCollectionSizeLimitExceededException,并且您可能无法向项目集合添加更多项目或增加项目集合中项目的大小。(仍然允许对项目集合的大小进行读取和写入操作。) 您仍然可以将项目添加到其他项目集合。
要减小项目集合的大小,您可以执行以下操作之一:
-
删除具有相关分区键值的所有不必要项目。从基表中删除这些项目时,DynamoDB 还会删除具有相同分区键值的所有索引条目。
-
通过删除属性或减小属性的大小来更新项目。如果将这些属性投影到任何本地二级索引中,DynamoDB 还会减小相应索引条目的大小。
-
使用相同的分区键和排序键创建新表,然后将项目从旧表移动到新表。如果表具有不经常访问的历史数据,这可能是一种很好的方法。您还可能考虑将此历史数据存档到 Amazon Simple Storage Service (Amazon S3)。
当项目集合的总大小低于 10 GB 时,您可以再次添加具有相同分区键值的项目。
作为最佳实践,我们建议设置应用程序监控项目集合的大小。一种方法使用 BatchWriteItem、DeleteItem、PutItem 或 UpdateItem 时将 SIZE 参数设置为 ReturnItemCollectionMetrics。您的应用程序应检查输出的 ReturnItemCollectionMetrics 对象,在项目集合超过用户定义的限制(例如 8 GB)时记录错误消息。设置一个小于 10 GB 的限制将提供一个预警系统,以便您知道项目集合即将接近限制,以便对其执行某些操作。
项目集合和分区
在带一个或多个本地二级索引的表中,每个项目集合存储在一个分区中。此类项目集合的总大小限制为该分区的容量:10GB。对于应用程序而言,如果其数据模型包含大小不受限制的项目集合,或者您可能合理地预期某些项目集合将来会增长到 10GB 以上,那么您应该考虑改用全局二级索引。
应设计应用程序,在不同分区键值之间均匀分布表数据。对于具有本地二级索引的表,应用程序不应在单个分区上的单个项目集合中创建读取和写入活动的“热点”。