使用 DynamoDB 全局表的写入模式
全局表在表级别始终处于主动-主动状态。但是,特别是对于 MREC 表,您可能希望通过控制您路由写入请求的方式来将它们作为主动-被动进行处理。例如,您可能决定将写入请求路由到单个区域,以避免 MREC 表可能发生的潜在写入冲突。
有三种主要的托管式写入模式,如以下三节所述。您应该考虑哪种写入模式适合您的使用案例。此选择会影响您路由请求、撤离区域和处理灾难恢复的方式。后面章节中的指引取决于应用程序的写入模式。
写入任何区域模式(非主模式)
如下图所示,写入任何区域模式处于完全主动-主动状态,不会对可能发生写入的位置施加限制。任何区域都可以随时接受写入。这是最简单的模式,但只能用于某些类型的应用程序。此模式适用于所有 MRSC 表。当所有写入器都是幂等的,因此可以安全地重复,使得跨区域的并发或重复的写入操作不会发生冲突时,此模式也适用于 MREC 表。例如,当用户更新其联系人数据时。此模式也适用于一种特殊的幂等情况,即仅限追加的数据集,其中所有写入操作都是确定性主键下的唯一插入。最后,在可以接受写入冲突风险时,此模式适用于 MREC。
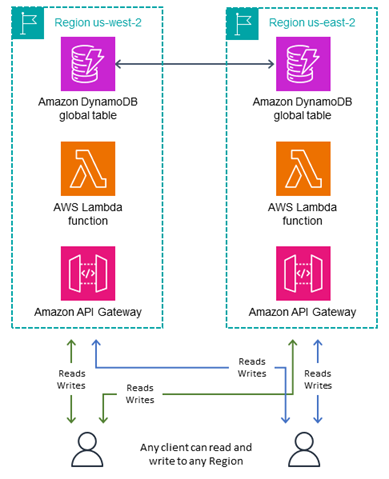
写入任何区域模式是实现起来最简单的架构。路由更容易,因为任何区域都可以随时成为写入目标。失效转移更容易,因为使用 MRSC 表可以始终同步项目,而且使用 MRSC 表,任何最近的写入都可以对任何辅助区域重播任意次。在可能的情况下,您应该针对这种写入模式进行设计。
例如,一些视频流媒体服务使用全局表来跟踪书签、评论、观看状态标志等。这些部署之所以使用 MREC 表,是因为它们需要分散在世界各地的副本,每个副本都提供低延迟的读取和写入操作。这些部署可以使用写入任何区域模式,只要确保每个写入操作都是幂等的即可。如果每次更新(例如设置新的最新时间码、分配新的评论或设置新的观看状态)都会直接分配用户的新状态,且项目的下一个正确值不依赖于当前值,就会出现这种情况。如果将用户的写入请求碰巧路由到不同的区域,则最后一次写入操作将持续存在,全局状态将根据最后一次分配而定。在此模式下,读取操作最终会变得一致,但会因最新的 ReplicationLatency 值而延迟。
在另一个例子中,一家金融服务公司使用全局表作为系统的一部分,以持续统计每位客户的借记卡购买情况,从而计算该客户的现金返还奖励。他们希望每位客户都能保留一个 RunningBalance 项目。此写入模式本身并不是幂等的,因为随着事务的流入,它们会使用 ADD 表达式来修改余额,而新的正确值取决于当前值。通过使用 MRSC 表,他们仍然可以写入任何区域,因为每次 ADD 调用总是针对项目的最新值进行操作。
第三个示例涉及一家提供在线广告投放服务的公司。该公司已经决定,为了简化写入任何区域模式的设计,可以接受较低的数据丢失风险。在投放广告时,公司只有几毫秒的时间检索足够的元数据来确定要展示的广告,然后记录广告展示,以免很快重复展示同一广告。他们使用全局表,为全世界的最终用户实现低延迟的读取操作和低延迟的写入操作。他们在单个项目内记录用户的所有广告展示,并以不断增长的列表形式呈现。他们使用一个项目而不是追加到项目集合中,以便可以在每次写入操作中删除较旧的广告展示,而无需支付删除操作的费用。此写入操作不是幂等的;如果同一个最终用户在大概同一时间看到来自多个区域的广告,则广告展示的一次写入操作可能会覆盖另一次写入操作。风险在于,用户可能会偶尔看到重复的广告。他们认为这是可接受的。
写入一个区域(单主模式)
如下图所示,写入一个区域模式是主动-被动模式,它将所有表写入操作都路由到单个主动区域。请注意,DynamoDB 没有单一主动区域的概念;DynamoDB 外部的应用程序路由对此进行管理。对于需要避免写入冲突的 MREC 表,写入一个区域模式可以很好地确保写入操作一次只流向一个区域。当您想使用条件表达式但由于某种原因无法使用 MRSC 时,或者当您需要执行事务时,此写入模式会有所帮助。除非您知道自己是在针对最新数据执行操作,否则这些表达式是不可能的,因此它们需要将所有写入请求发送到具有最新数据的单个区域。
使用 MRSC 表时,为了方便起见,通常可以选择写入一个区域。例如,这有助于最大限度地减少您在 DynamoDB 之外的基础设施构建。写入模式仍将写入任何区域,因为使用 MRSC,您可以随时安全地写入任何区域,而不必担心会导致 MREC 表选择写入一个区域的冲突解决方案。
最终一致性读取可以进入任何副本区域以降低延迟。强一致性读取必须进入单个主区域。
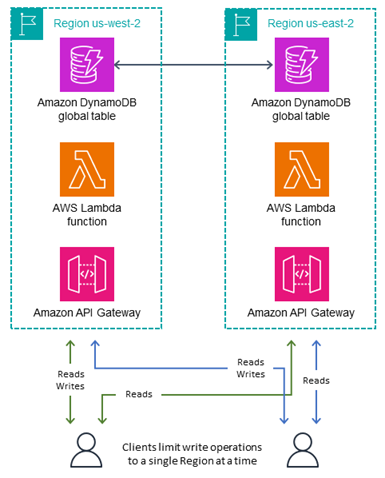
有时需要更改主动区域来应对区域故障。一些用户会定期更改当前主动区域,例如实施“跟随太阳”部署。这会将主动区域放置在活动最多的地理位置附近(通常是白天,因此得名),从而实现最低的读取和写入延迟操作。它还有一个附带好处,那就是每天调用区域不断变化的代码,确保在进行任何灾难恢复之前都经过良好的测试。
被动区域可能会在 DynamoDB 周围保留一组缩小规模的基础设施,而只有当被动区域成为主动区域时,此类基础设施才会建立起来。本指南不涵盖 pilot light 和暖备用设计。有关更多信息,请参阅《Disaster Recovery (DR) Architecture on Amazon, Part III: Pilot Light and Warm Standby
在使用全局表进行低延迟的全局分布式读取操作时,使用写入一个区域模式效果很好。例如,一家大型社交媒体公司需要在全球每个区域提供相同的参考数据。他们不经常更新数据,但在更新数据时,他们只写入一个区域,以避免任何潜在的写入冲突。任何区域都始终允许进行读取操作。
再举一个例子,考虑一下前面提到的那家实施了每日现金返还计算的金融服务公司。其使用写入任何区域模式来计算余额,但使用写入一个区域模式来跟踪付款。这项工作需要处理事务,而 MRSC 表不支持这些事务,因此使用单独的 MREC 表和写入一个区域模式时效果更好。
写入您的区域(混合主模式)
下图所示的写入您的区域写入模式适用于 MREC 表。它将不同的数据子集分配给不同的主区域,并且仅允许通过其主区域对项目进行写入操作。此模式为主动-被动模式,但会根据项目分配主动区域。每个区域都是其自己的非重叠数据集的主区域,必须保护写入操作以确保位置正确。
此模式与写入一个区域类似,不同之处在于它支持低延迟写入操作,因为与每个最终用户关联的数据可以放在离该用户更近的网络上。此模式还可以在各区域之间更均匀地分布周围的基础设施,并且在失效转移方案中构建基础设施所需的工作量更少,因为所有区域的基础设施都有一部分已经处于主动状态。
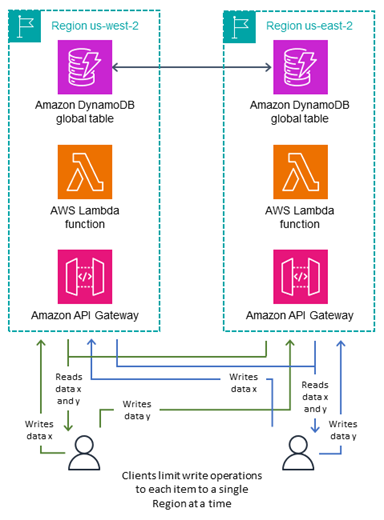
您可以通过多种方式确定项目的主区域:
内置函数:数据的某些方面(例如特殊属性或嵌入在其分区键内的值)可明确其主区域。博客文章 Use Region pinning to set a home Region for items in an Amazon DynamoDB global table
中介绍了此技术。 已协商:通过某种外部方式协商每个数据集的主区域,例如与维护分配的单独全局服务进行协商。分配可能有一个有限的期限,在此之后需要重新协商。
面向表:与其创建单个复制全局表,不如创建与复制区域数量相同的全局表。每个表的名称都指示其主区域。在标准操作中,所有数据都写入主区域,而其他区域则保留只读副本。在失效转移期间,另一个区域临时承担对该表的写入职责。
例如,假设您在一家游戏公司工作。您需要为全世界的所有游戏玩家提供低延迟的读取和写入操作。您将每位游戏玩家分配到离其最近的区域。该区域会承担他们所有的读取和写入操作,从而确保很强的写入后读取一致性。但是,如果该游戏玩家外出旅行或其主区域发生中断,则其数据的完整副本将在备用区域中可用,游戏玩家可以分配到不同的主区域。
再举一个例子,假设您在一家视频会议公司工作。每次电话会议的元数据都会分配到一个特定的区域。呼叫者可以使用离他们最近的区域以实现最低延迟。如果出现区域中断,使用全局表可以快速恢复,因为系统可以将呼叫处理转移到已经有数据复制副本的其他区域。
总结
-
“写入任何区域”模式适用于 MRSC 表以及对 MREC 表的幂等调用。
-
“写入一个区域”模式适用于对 MREC 表的非幂等调用。
-
“写入您的区域”模式适用于在让客户端写入离其较近的区域非常重要时,对 MREC 表的非幂等调用。