DynamoDB 容量暴增和自适应容量
为最大限度地减少因吞吐量异常而造成的节流,DynamoDB 使用容量爆增来应对用量峰值。DynamoDB 使用自适应容量 来协助适应不均匀的访问模式。
容量爆增
DynamoDB 通过容量暴增,为吞吐量调配提供一定的灵活性。如果您未完全使用可用的吞吐量,DynamoDB 将为稍后的吞吐量爆增保留一部分未使用的容量,来应对用量峰值。利用容量暴增,意外的读取或写入请求可在原本会受限制的环境中获得成功。
DynamoDB 目前保留最多五分钟(300 秒)未使用的读取和写入容量。在读取或写入操作偶尔爆增期间,可以快速消耗这些额外容量单位 - 甚至比已经为表定义的每秒预置吞吐能力还快。
DynamoDB 还可能在不事先通知的情况下,将暴增容量用于后台维护和其他任务。
请注意,这些暴增容量详细信息未来可能发生变化。
自适应容量
DynamoDB 会自动将您的数据分布到不同的分区(分区存储在 Amazon Web Services 云中的多个服务器上)。不可能始终均匀地分布读取活动和写入活动。如果数据访问不平衡,“热门”分区的读取和写入量将高于其他分区。由于分区上的读取和写入操作是独立管理的,因此,如果单个分区接收 3000 次以上的读取操作或 1000 次以上的写入操作,则会发生节流。自适应容量的工作原理是,自动增加分区的吞吐容量来接收更多流量。
为了更好地适应不均匀访问模式,DynamoDB 自适应容量允许应用程序继续对热门分区进行读写操作,而不节流,前提是流量未超出表的总预置容量或分区最大容量。自适应容量自动即时增加接收更多流量的分区的吞吐容量。
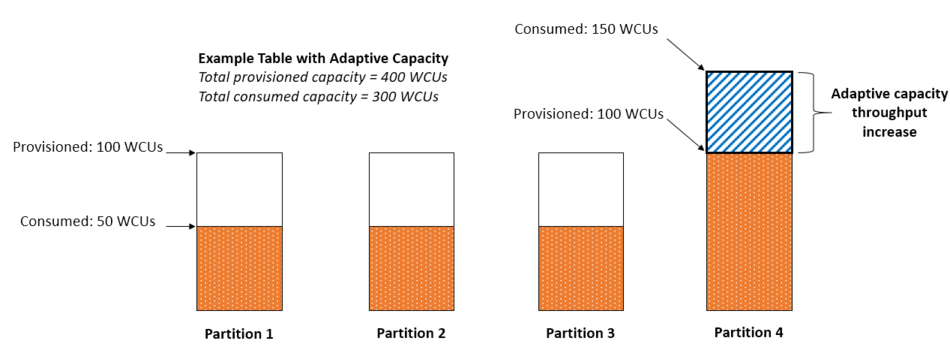
下图说明自适应性容量的工作方式。示例表配置了 400 个 WCU,均匀分布在 4 个分区,每个分区每秒可以承受最多 100 个 WCU。分区 1、2 和 3 各接收 50 WCU/秒的写入流量。分区 4 接收 150 WCU/秒。这个热门分区可以接收写入流量,同时仍具有未使用的暴增容量,但最终将节流超过 100 WCU/秒的流量。
DynamoDB 自适应容量通过增加分区 4 的容量来应对,这样可以保持 150 WCU/秒的更高工作负载,而不会节流。
自适应容量对每个 DynamoDB 表自动启用,无附加费用。无需明确启用或禁用。
隔离频繁访问的项目
如果应用程序到一个或多个项目的流量特别高,自适应容量将重新平衡分区,使频繁访问的项目不在同一分区中。这种隔离频繁访问的项目的做法,可以降低因工作负荷超出单个分区上的吞吐量配额而造成请求限制的可能性。您还可以通过排序键将项目集合分为多个区段,只要项目集合不是由排序键的单调增加或减少跟踪的流量即可。
如果应用程序带来的高流量始终针对单个项目,自适应容量可能重新平衡数据,以使分区仅包含单个频繁访问的项目。在此情况下,DynamoDB 可以为这个项目的主键提供达到分区最大 3000 RCU 和 1000 WCU 的吞吐量。当表上有本地二级索引时,自适应容量不会跨表的多个分区拆分项目集合。