DynamoDB 中的数据建模构建基块
本节介绍构建基块层,它为您提供可以在应用程序中使用的设计模式。
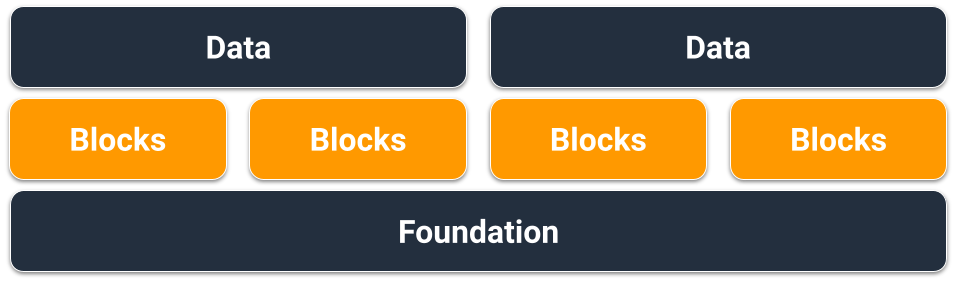
复合排序键构建基块
用户可能会认为 NoSQL 也是非关系型的。归根结底,没有理由不能在 DynamoDB 架构中放入关系,它们只是看起来与关系数据库及其外键不同。在 DynamoDB 中,我们可以用来建立数据的逻辑层次结构的最关键模式之一是复合排序键。在设计时,最常见样式使用 # 分隔层次结构的每一层(父层 > 子层 > 孙子层)。例如 PARENT#CHILD#GRANDCHILD#ETC。
虽然在 DynamoDB 中,分区键总是需要确切的值才能查询数据,但我们可以对排序键从左到右应用部分条件,类似于遍历二叉树。
在上面的示例中,我们有一家电子商务网店,提供了需要在用户的不同会话之间维护的购物车。每当用户登录时,他们需要能够查看完整的购物车,包括保存起以便将来购买的商品。但是,当他们进入结账环节时,只能加载活动购物车中的商品进行购买。由于这些 KeyConditions 都明确要求提供 CART 排序键,因此 DynamoDB 在读取时会直接忽略其他心愿单中的数据。虽然已保存的商品和活动商品都放在购物车中,但在应用程序的不同部分中,我们需要以不同的方式对待它们,因此,要想仅检索应用程序的各个部分所需的数据,最优方法是对排序键的前缀应用 KeyCondition。
此构建基块的主要特点
-
相关项目存储在本地同一相对位置,以实现高效的数据访问
-
使用
KeyCondition表达式,可以有选择地检索层次结构的子集,这意味着不会浪费 RCU -
应用程序的不同部分可以将其项目存储在特定前缀下,以防止项目被覆盖或写入冲突
多租户构建基块
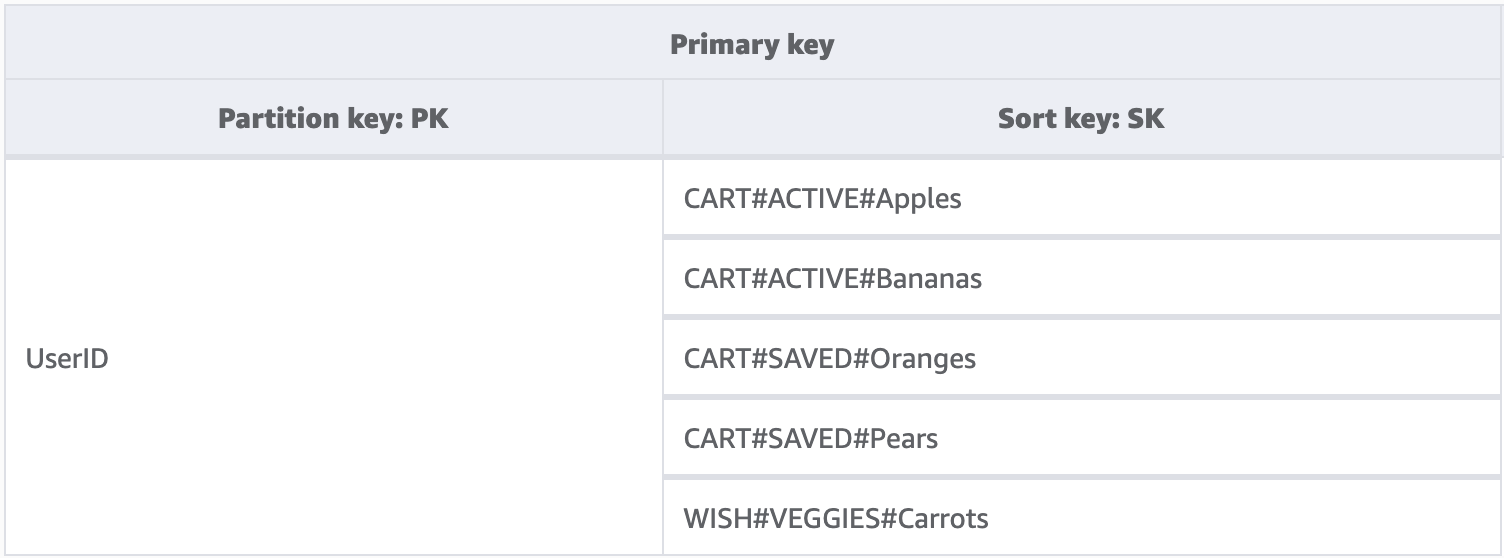
许多客户使用 DynamoDB 托管其多租户应用程序的数据。对于这些场景,我们希望设计一种架构,将单个租户的所有数据保留在表的该租户自己的逻辑分区中。这利用了项目集合的概念,该术语指的是 DynamoDB 表中具有相同分区键的所有项目。有关 DynamoDB 如何实现多租户的更多信息,请参阅 Multitenancy on DynamoDB。
在本示例中,我们运行的是一个照片托管网站,用户数可能会成千上万。每个用户最初只能将照片上传到自己的个人资料中,而且在默认情况下,我们不允许用户查看任何其他用户的照片。理想情况下,在每个用户调用您 API 的授权中,应该添加额外的隔离级别,以确保他们只能请求自己分区中的数据,但是在架构级别,唯一的分区键就足够了。
此构建基块的主要特点
-
任何一位用户或租户读取的数据量只能等于其自身分区中的项目总量
-
在账户关闭或由于合规性要求而要删除租户数据时,可以巧妙地完成删除,而且成本很低。只需运行分区键等于其租户 ID 的查询,然后对返回的每个主键执行
DeleteItem操作
注意
通过在设计时考虑多租户的情况,您便可在单个表中,使用不同的加密密钥提供程序来安全地隔离数据。适用于 Amazon DynamoDB 的 Amazon 数据库加密 SDK 让您可以在 DynamoDB 工作负载中提供客户端加密功能。您可以执行属性级别的加密,这样就可以先对特定属性值进行加密,然后再存储到 DynamoDB 表中,而且无需预先解密整个数据库即可搜索加密的属性。
稀疏索引构建基块
有时,访问模式需要查找与稀少项目或接收状态的项目(这需要上报响应)相匹配的项目。我们无需频繁地在整个数据集中查询这些项目,而是可以随数据一起稀疏加载全局二级索引 (GSI)。这意味着基表中的项目,只有在索引中定义了属性时才会复制到索引中。
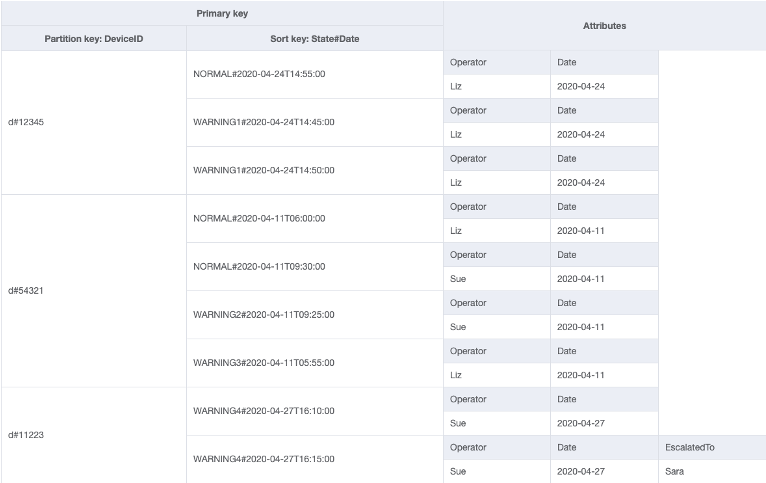

在此示例中,我们看到了一个 IOT 使用场景,在该场景中,现场的每台设备都会定期报告状态。我们预计在绝大多数报告中,设备会报告一切正常,但有时可能会出现故障,这时必须上报到维修技术人员。对于带有上报情况的报告,属性 EscalatedTo 会添加到项目中,其他情况下不会有此属性。本示例中的 GSI 按 EscalatedTo 分区,由于 GSI 从基表中引入了键,我们仍然可以查看报告了故障的 DeviceID 以及报告故障的时间。
虽然在 DynamoDB 中读取比写入的成本更低,但稀疏索引是一种非常强大的工具,适用于特定类型项目的实例很少,但进行读取以查找这些实例却很常见的使用场景。
此构建基块的主要特点
-
稀疏 GSI 的写入和存储成本仅应用到与键模式匹配的项目,因此稀疏 GSI 的成本可能大大低于将所有项目复制到其中的其他 GSI 的成本
-
复合排序键仍可用于进一步缩小与所需查询匹配的项目的范围,例如,时间戳可用作排序键,以便仅查看最近 X 分钟 (
SK > 5 minutes ago, ScanIndexForward: False) 内报告的错误
生存时间构建基块
大多数数据在一定的持续时间内,可以认为值得将其保存在主数据存储中。为了协助对 DynamoDB 中的数据进行老化处理,它具有一项名为生存时间(TTL)的功能。利用 TTL 功能,您可以为需要监控的属性,在表级别定义带有纪元时间戳(过去的时间)的特定属性。这让您可以免费从表中删除过期的记录。
注意
如果使用全局表的全局表版本 2019.11.21(当前版),并且还使用生存时间特征,则 DynamoDB 会将 TTL 删除复制到所有副本表。在出现 TTL 到期的区域中,初始 TTL 删除不会消耗写入容量。但是,在每个副本区域中,复制到副本表的 TTL 删除将消耗复制的写容量单位,并且将收取适用的费用。
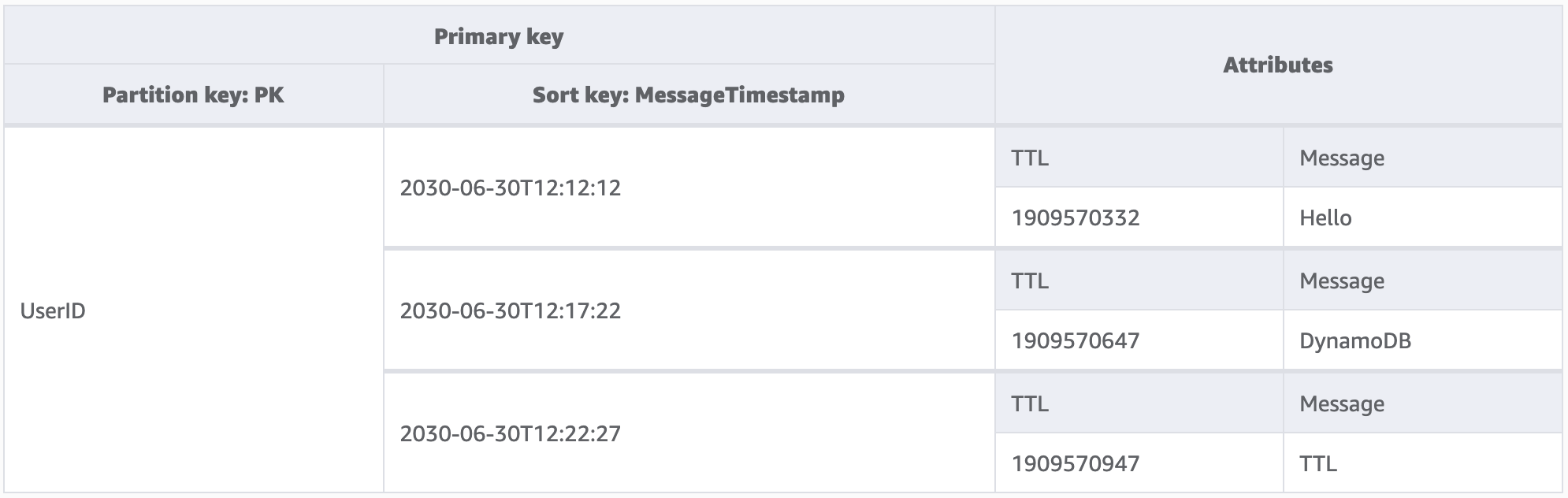
在此示例中,我们有一个应用程序,设计用于让用户创建短暂存在的消息。在 DynamoDB 中创建消息时,应用程序代码会将 TTL 属性设置为 7 天以后的日期。大约 7 天后,DynamoDB 会发现这些项目的纪元时间戳为过去的时间,并且会删除这些项目。
由于按 TTL 执行删除是免费的,因此强烈建议使用此功能从表中删除历史数据。这可以减少每个月的总存储账单费用,并且有可能减少用户的读取成本,因为这减少了他们在查询时需要检索的数据量。虽然可以在表级别启用 TTL,但您需要确定为哪些项目或实体创建 TTL 属性,以及将纪元时间戳设置为未来多长时间。
此构建基块的主要特点
-
TTL 删除操作在后台运行,不会影响您的表性能
-
TTL 是一个异步进程,大约每六小时运行一次,但最多可能需要 48 小时才能删除过期的记录
-
对于锁定记录或者状态管理等使用场景,如果必须在 48 小时内清理过时数据,则不要依赖 TTL 删除操作
-
-
您可以将 TTL 属性命名为有效的属性名称,但该值必须是数值类型
存档生存时间构建基块
尽管 TTL 是从 DynamoDB 中删除较早数据的有效工具,但在许多使用场景中,会要求将数据存档保留比主数据存储更长的时间。在这种情况下,我们可以利用 TTL 的定时删除记录,将过期记录推送到长期数据存储中。
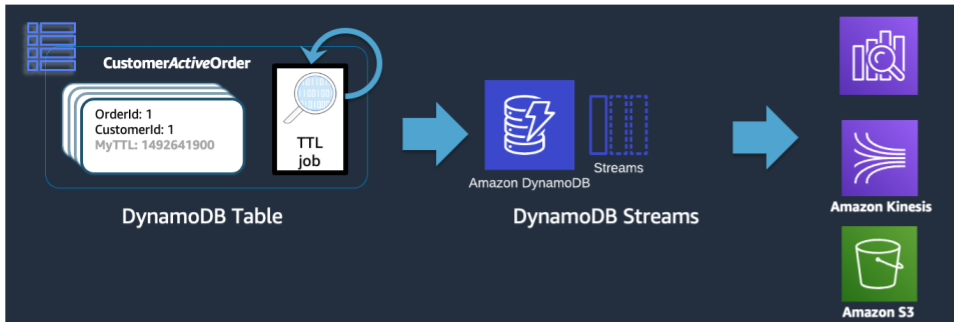
当 DynamoDB 完成 TTL 删除时,该操作仍会作为 Delete 事件推送到 DynamoDB Streams 中。但是,当 DynamoDB TTL 是执行删除操作的一方时,principal:dynamodb 的流记录上会有一个属性。使用订阅到 DynamoDB Streams 的 Lambda 订阅用户,我们可以仅对 DynamoDB 主体属性应用事件筛选条件,并且可以确定,与该筛选条件匹配的所有记录都将推送到存档存储中,例如 Amazon Glacier。
此构建基块的主要特点
-
对于历史项目,当不再需要 DynamoDB 的低延迟读取时,将其迁移到 Amazon Glacier 等冷存储中可以显著降低存储成本,同时满足使用案例的数据合规性需求
-
如果将数据保存到 Amazon S3 中,则可以使用 Amazon Athena 或 Redshift Spectrum 等经济高效的分析工具,对数据执行历史分析
垂直分区构建基块
用户如果熟悉文档模型数据库,那么也会熟悉将所有相关数据存储在单个 JSON 文档中的概念。尽管 DynamoDB 支持 JSON 数据类型,但不支持在嵌套 JSON 上执行 KeyConditions。由于 KeyConditions 决定从磁盘读取的数据量以及实际上查询使用的 RCU 数量,因此在大规模执行时,这可能会导致效率低下。为了更好地优化 DynamoDB 的写入和读取,我们建议将文档的单独实体拆分为单独的 DynamoDB 项目,这种方法也称为垂直分区。

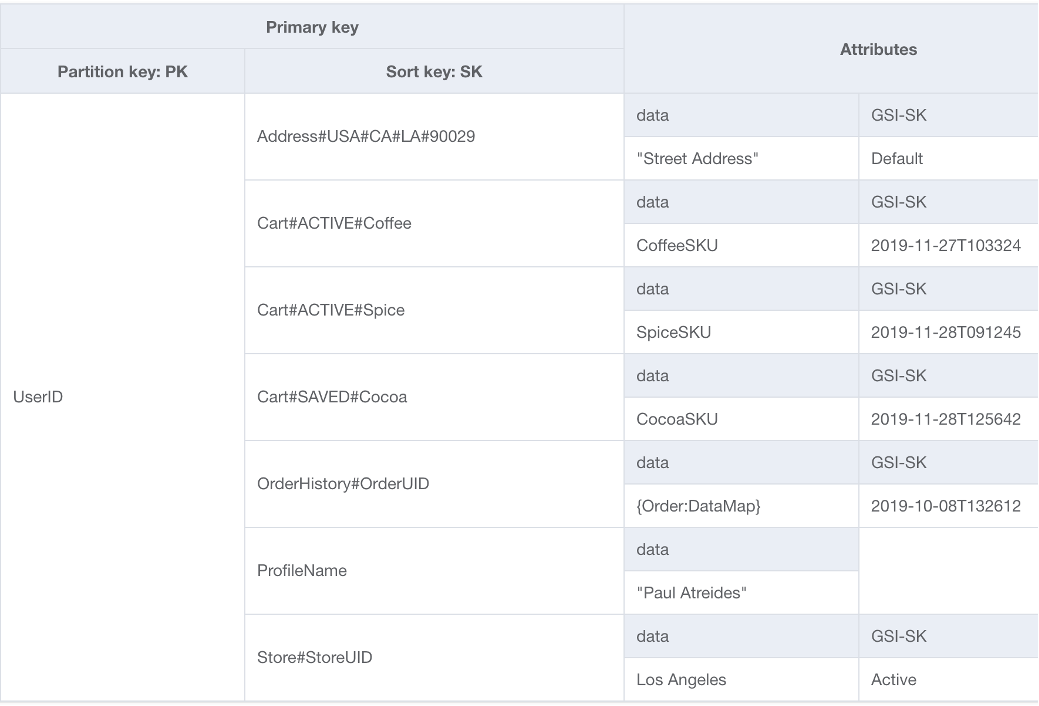
如上所示,垂直分区是单表设计在实际使用中的一个重要例子,但在需要时,也可以在多个表中实施。由于 DynamoDB 对写入以 1KB 为单位进行计费,因此理想情况下,您在对文档分区时,应该使得生成的项目小于 1KB。
此构建基块的主要特点
-
数据关系的层次结构通过排序键前缀维护,因此在需要时,可以在客户端重建单一文档结构
-
数据结构的单个组件可以独立更新,因此可以进行只需一个 WCU 的小项目更新
-
通过使用排序键
BeginsWith,应用程序可以在单个查询中检索相似的数据,聚合读取成本以降低总成本/延迟 -
大型文档很容易超过 DynamoDB 中 400 KB 的单个项目大小限制,垂直分区有助于解决这个限制
写入分片构建基块
DynamoDB 有很少几个硬性限制,其中之一是限制单个物理分区可以保持的每秒吞吐量(不一定是单个分区键)。目前,这些限制是:
-
1000 个 WCU(或每秒写入 1000 个 <=1KB 的项目)和 3000 个 RCU(或每秒 3000 个 <=4KB 的读取)(强一致性),或者
-
每秒 6000 个 <=4KB 的读取(最终一致性)
如果对表的请求数量超过上述任一限制,则会将错误 ThroughputExceededException 发送回客户端 SDK,这种情况通常称为节流。如果使用场景需要的读取操作数超出该限制,最适合的处理方法是在 DynamoDB 前面放置读取缓存,但写入操作需要采用称为写入分片的架构级别设计。
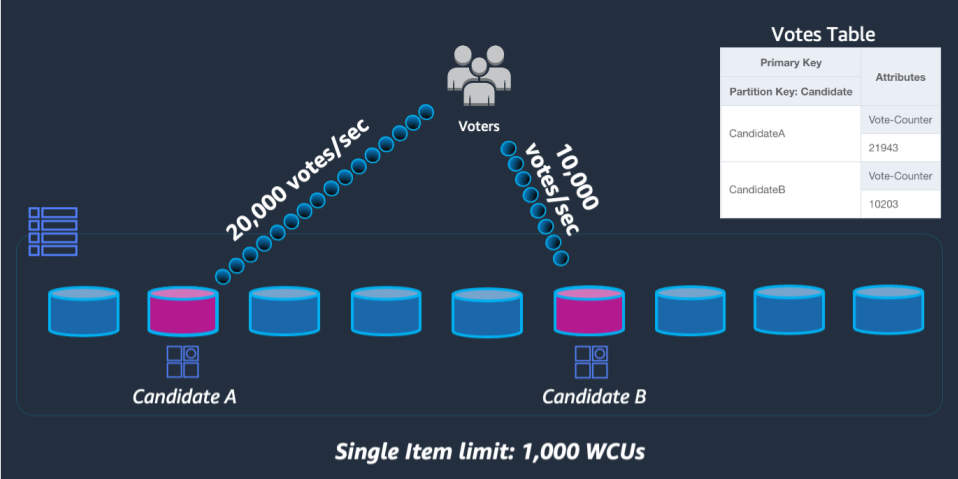
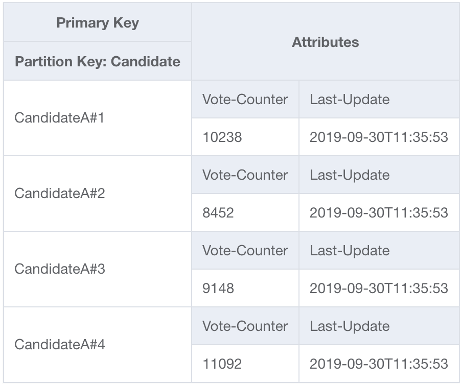
为了解决这个问题,我们将在应用程序的 UpdateItem 代码中,对每个参赛选手的分区键末尾附加一个随机整数。对于随机整数生成器,其范围上限必须等于或大于给定参赛选手预期的每秒写入数除以 1000。要支持每秒 2 万次投票,其上限应该类似于 rand(0,19)。现在,数据存储在单独的逻辑分区下,读取时必须将其重新合并在一起。由于投票总数不必是实时结果,因此 Lambda 函数计划每 X 分钟读取一次所有投票分区,这可以不定期地对每位参赛选手执行聚合操作,并将其写回单个投票总数记录以进行实时读取。
此构建基块的主要特点
-
如果在使用场景中,对于给定分区键具有极高的写入吞吐量且无法避免,可以人为地将写入操作分散到多个 DynamoDB 分区上
-
具有低基数分区键的 GSI 也应使用这种模式,因为 GSI 上的节流会对基表的写入操作带来反向压力