本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
Amazon AppSync JavaScript 解析器概述
Amazon AppSync 允许您通过对数据源执行操作来响应 GraphQL 请求。对于您希望运行查询、变更或订阅的每个 GraphQL 字段,必须附加一个解析器。
解析器是 GraphQL 和数据来源之间的连接器。它们讲述 Amazon AppSync 如何将传入的 GraphQL 请求转换为后端数据源的指令,以及如何将来自该数据源的响应转换回 GraphQL 响应。使用 Amazon AppSync,您可以使用编写解析器 JavaScript并在 Amazon AppSync (APPSYNC_JS) 环境中运行它们。
Amazon AppSync 允许您在管道中编写由多个 Amazon AppSync 函数组成的单元解析器或管道解析器。
支持的运行时系统功能
Amazon AppSync JavaScript 运行时提供了一部分 JavaScript 库、实用程序和功能。有关APPSYNC_JS运行时支持的特性和功能的完整列表,请参阅解析器和函数的JavaScript 运行时特性。
单位解析器
单位解析器由定义对数据来源执行的请求和响应处理程序的代码组成。请求处理程序将上下文对象作为参数,并返回用于调用数据来源的请求负载。响应处理程序接收从数据来源返回的负载以及执行的请求结果。响应处理程序将负载转换为 GraphQL 响应以解析 GraphQL 字段。在以下示例中,解析器从 DynamoDB 数据来源中检索项目:
import * as ddb from '@aws-appsync/utils/dynamodb' export function request(ctx) { return ddb.get({ key: { id: ctx.args.id } }); } export const response = (ctx) => ctx.result;
JavaScript 管道解析器的剖析
管道解析器由定义请求和响应处理程序以及函数列表的代码组成。每个函数具有一个对数据来源执行的请求和响应处理程序。由于管道解析器将运行委派给一组函数,因此,它不会链接到任何数据来源。单位解析器和函数是对数据来源执行操作的基元。
管道解析器请求处理程序
管道解析器的请求处理程序(预备步骤)允许您在运行定义的函数之前执行一些准备逻辑。
函数列表
管道解析器将按顺序运行的函数的列表。管道解析器请求处理程序评估结果作为 ctx.prev.result 提供给第一个函数。每个函数评估结果作为 ctx.prev.result 提供给下一个函数。
管道解析器响应处理程序
管道解析器的响应处理程序允许您执行从最后一个函数的输出到预期 GraphQL 字段类型的一些最终逻辑。函数列表中的最后一个函数的输出在管道解析器响应处理程序中作为 ctx.prev.result 或 ctx.result 提供。
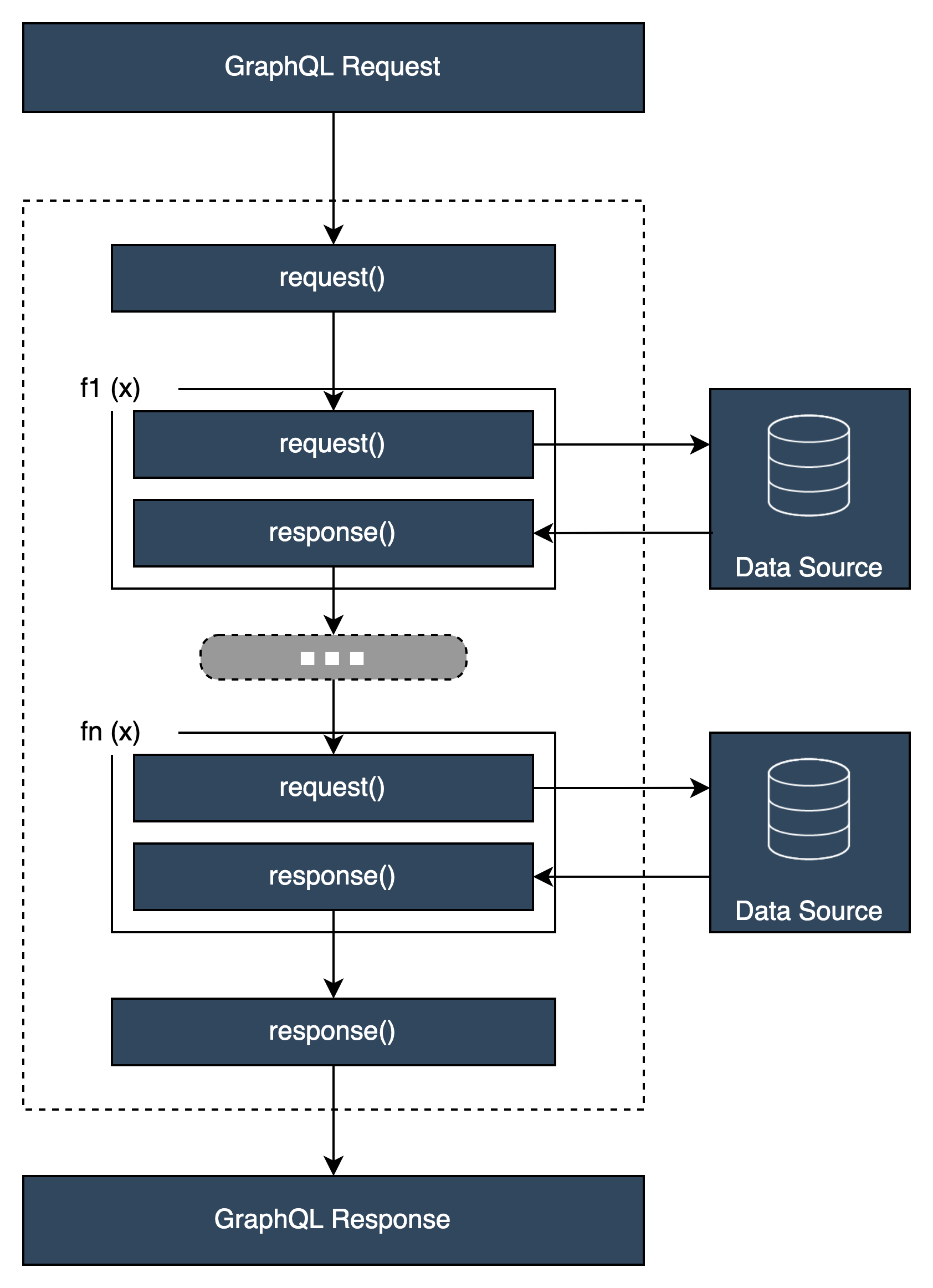
执行流程
假定一个管道解析器由两个函数组成,下面的列表表示调用解析器时的执行流程:
-
管道解析器请求处理程序
-
函数 1:函数请求处理程序
-
函数 1:数据来源调用
-
函数 1:函数响应处理程序
-
函数 2:函数请求处理程序
-
函数 2:数据来源调用
-
函数 2:函数响应处理程序
-
管道解析器响应处理程序
非常有用的 APPSYNC_JS 运行时系统内置实用程序
在使用管道解析器时,以下实用工具可为您提供帮助。
ctx.stash
存储区是一个在每个解析器以及函数请求和响应处理程序中提供的对象。相同的存储区实例在单次解析器运行时间内有效。这意味着,您可以使用存储区在请求和响应处理程序之间以及管道解析器中的函数之间传送任意数据。你可以像普通 JavaScript 物体一样测试藏匿处。
ctx.prev.result
ctx.prev.result 表示已在管道中执行的上一个操作的结果。如果上一个操作是管道解析器请求处理程序,则将 ctx.prev.result 提供给链中的第一个函数。如果上一个操作是第一个函数,则 ctx.prev.result 表示第一个函数的输出,并且可供管道中的第二个函数使用。如果上一个操作是最后一个函数,则 ctx.prev.result 表示最后一个函数的输出,并提供给管道解析器响应处理程序。
util.error
util.error 实用工具对于引发字段错误很有用。在函数请求或响应处理程序中使用 util.error 将立即引发字段错误,这会禁止执行后续的函数。有关更多详细信息和其他util.error签名,请访问解析器和函数的JavaScript运行时功能。
util.appendError
util.appendError 与 util.error() 类似,主要区别在于,它不会中断处理程序评估。相反,它指示字段存在错误,但允许评估处理程序并因而返回数据。在函数中使用 util.appendError 将不会中断管道的执行流。有关更多详细信息和其他util.error签名,请访问解析器和函数的JavaScript 运行时功能。
runtime.earlyReturn
runtime.earlyReturn 函数允许您从任何请求函数中提前返回。在解析器请求处理程序中使用 runtime.earlyReturn 将从解析器中返回。从 Amazon AppSync
函数请求处理程序中调用它将从该函数中返回,并继续运行到管道中的下一个函数或解析器响应处理程序。
编写管道解析器
管道解析器还具有运行管道中的函数之前和之后的请求和响应处理程序:其请求处理程序在第一个函数的请求之前运行,其响应处理程序在最后一个函数的响应之后运行。解析器请求处理程序可以设置管道中的函数使用的数据。解析器响应处理程序负责返回映射到 GraphQL 字段输出类型的数据。在以下示例中,解析器请求处理程序定义 allowedGroups;返回的数据应属于这些组之一。解析器的函数可以使用该值以请求数据。解析器的响应处理程序进行最终检查并筛选结果,以确保仅返回属于允许的组的项目。
import { util } from '@aws-appsync/utils'; /** * Called before the request function of the first AppSync function in the pipeline. * @param ctx the context object holds contextual information about the function invocation. */ export function request(ctx) { ctx.stash.allowedGroups = ['admin']; ctx.stash.startedAt = util.time.nowISO8601(); return {}; } /** * Called after the response function of the last AppSync function in the pipeline. * @param ctx the context object holds contextual information about the function invocation. */ export function response(ctx) { const result = []; for (const item of ctx.prev.result) { if (ctx.stash.allowedGroups.indexOf(item.group) > -1) result.push(item); } return result; }
写入 Amazon AppSync 函数
Amazon AppSync 函数使您能够编写通用逻辑,这些逻辑可以在架构中的多个解析器中重复使用。例如,您可以设置一个名为的函数QUERY_ITEMS,该 Amazon AppSync 函数负责查询来自 Amazon DynamoDB 数据源的项目。对于要用于查询项目的解析器,只需将函数添加到解析器的管道并提供要使用的查询索引即可。不必重新实施该逻辑。
补充主题
主题