将 Athena 连接到 Apache Hive 元存储
要将 Athena 连接到 Apache Hive 元数据仓,您必须创建和配置 Lambda 函数。对于基本实现,您可以从 Athena 管理控制台执行所有必需步骤。
注意
以下过程要求您具有为 Lambda 函数创建自定义 IAM 角色的权限。如果您没有权限创建自定义角色,则可以使用 Athena 参考实现以单独创建 Lambda 函数,然后使用 Amazon Lambda 控制台,为函数选择现有 IAM 角色。有关更多信息,请参阅 使用现有 IAM 执行角色将 Athena 连接到 Hive 元存储。
要将 Athena 连接到 Hive 元数据仓
从 https://console.aws.amazon.com/athena/
打开 Athena 控制台。 如果控制台导航窗格不可见,请选择左侧的扩展菜单。
-
选择数据来源和目录。
-
在控制台右上角,选择 Connect data source(连接数据源)。
-
在 Choose a data sources(选择数据源)页面中,对于 Data source(数据源),请选择 S3 - Apache Hive metastore(S3 - Apache Hive 元数据仓)。
-
选择下一步。
-
在 Data source details(数据源详细信息)部分,对于 Data source name(数据源名称),输入从 Athena 查询数据源时想要在 SQL 语句中使用的名称。名称最多可以包括 127 个字符,并且在您的账户中必须是唯一的。它在创建后即无法更改。有效字符包括 a-z、A-Z、0-9、_(下划线)、@(at 符号)和 -(连字符)。名称
awsdatacatalog、hive、jmx和system是 Athena 预留的名称,无法用于数据源名称。 -
对于 Lambda function(Lambda 函数),选择 Create Lambda function(创建 Lambda 函数),然后选择 Create a new Lambda function in Amazon Lambda(在 中新建 Lambda 函数)
AthenaHiveMetastoreFunction 页面将会在 Amazon Lambda 控制台中打开。该页面包括连接器的详细信息。
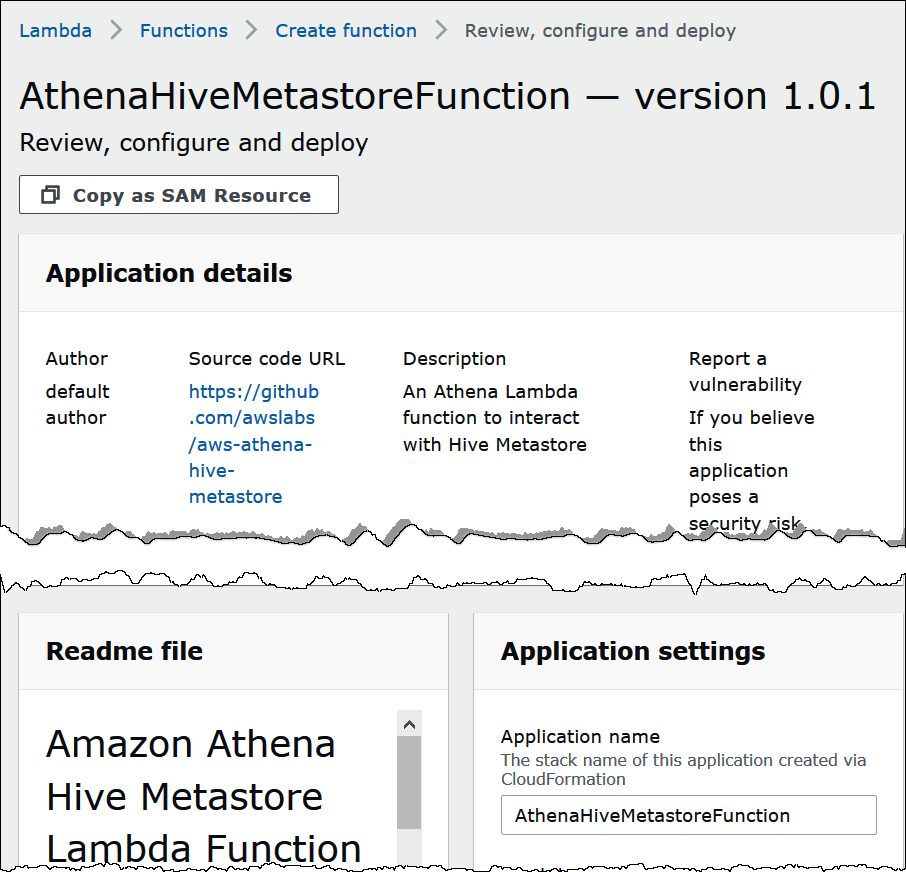
在 Application settings(应用程序设置)中,输入 Lambda 函数的参数。
-
LambdaFuncName – 提供函数的名称。例如,myHiveMetastore。
-
SpillLocation – 在此账户中指定 Amazon S3 位置,以便在 Lambda 函数响应大小超过 4 MB 时保存溢出元数据。
-
HMSUris – 输入您的 Hive 元数据仓主机的名称,该主机在端口 9083 使用 Thrift 协议。使用语法
thrift://<host_name>:9083。 -
LambdaMemory – 指定从 128 MB 到 3008 MB 的值。Lambda 函数分配与您配置的内存量成比例的 CPU 周期。默认值为 1024。
-
LambdaTimeout – 指定允许的最大 Lambda 调用运行时(以秒为单位),从 1 到 900(900 秒为 15 分钟)。默认值为 300 秒(5 分钟)。
-
VpcSecurityGroupIds – 为 Hive 元数据仓输入一个逗号分隔的 VPC 安全组 ID 列表。
-
VpcSubneIds – 为 Hive 元数据仓输入一个逗号分隔的 VPC 子网 ID 列表。
-
-
选择 I acknowledge that this app creates custom IAM roles(我确认此应用程序创建自定义 IAM 角色),然后选择 Deploy(部署)。
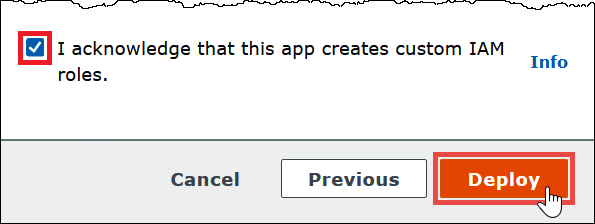
部署完成后,函数将显示在 Lambda 应用程序列表中。现在 Hive 元数据仓功能已部署到您的账户,您可以配置 Athena 配置以使用此功能。
-
返回至 Athena 控制台中的 Enter data source details(输入数据源详细信息)页面。
-
在 Lambda function(Lambda 函数)部分,选择 Lambda 函数搜索框旁的刷新图标。刷新可用函数列表会导致新创建的函数出现在列表中。
-
在 Lambda 控制台上选择刚创建的函数名称。将显示 Lambda 函数的 ARN。
-
(可选)对于 Tags(标签),添加要与此数据源关联的键值对。有关标签的更多信息,请参阅标记 Athena 资源。
-
选择下一步。
-
在 Review and create(审核和创建)页面中,查看数据源的详细信息,然后选择 Create data source(创建数据源)。
-
数据源此页面的 Data source details(数据源详细信息)部分显示了有关新连接器的信息。
您现在可以使用指定的 Data source name(数据源名称)以在 Athena 的 SQL 查询中引用 Hive 元数据仓。在 SQL 查询中,使用以下示例语法,并将
hms-catalog-1替换为您之前指定的目录名称。SELECT * FROM hms-catalog-1.CustomerData.customers -
有关查看、编辑或删除您创建的数据源的信息,请参阅 管理您的数据来源。