使用外部 Hive 元存储
您可以使用外部 Hive 元存储的 Amazon Athena 数据连接器来查询 Amazon S3 中使用 Apache Hive 元存储的数据集。无需将元数据迁移到 Amazon Glue Data Catalog。在 Athena 管理控制台中,配置 Lambda 函数以与私有 VPC 中的 Hive 元存储进行通信,然后将它连接到元存储。从 Lambda 到 Hive 元存储的连接由私有 Amazon VPC 通道提供保护,并且不使用公共 Internet。您可以提供您自己的 Lambda 函数代码,也可以使用外部 Hive 元存储的 Athena 数据连接器的默认实施。
主题
功能概览
利用外部 Hive 元存储的 Athena 数据连接器,您可以执行以下任务:
-
使用 Athena 控制台注册自定义目录并使用这些目录运行查询。
-
为不同的外部 Hive 元存储定义 Lambda 函数,并在 Athena 查询中联接它们。
-
在同一 Athena 查询中使用 Amazon Glue Data Catalog 和您的外部 Hive 元数据仓。
-
在查询执行上下文中指定目录作为当前默认目录。这样一来,便无需在查询中将目录名称置于数据库名称的前面。您可以使用
database.tablecatalog.database.table -
使用各种工具运行引用外部 Hive 元存储的查询。您可以使用 Athena 控制台、Amazon CLI、Amazon 软件开发工具包以及更新的 Athena JDBC 和 ODBC 驱动程序。更新后的驱动程序支持自定义目录。
API 支持
适用于外部 Hive 元数据仓的 Athena 数据连接器包含对目录注册 API 操作和元数据 API 操作的支持。
-
目录注册 – 为外部 Hive 元数据仓和联合数据源注册自定义目录。
-
元数据 – 使用元数据 API 为 Amazon Glue 和任何注册到 Athena 目录提供数据库和表信息。
-
Athena JAVA 软件开发工具包客户端 – 在更新后的 Athena JAVA 软件开发工具包客户端上的
StartQueryExecution操作中使用目录注册 API、元数据 API 并支持目录。
参考实现
Athena 提供连接到外部 Hive 元存储的 Lambda 函数的参考实施。参考实现在 GitHub 上作为 Athena Hive 元存储
参考实施在 Amazon Serverless Application Repository (SAR) 中作为以下两种 Amazon SAM 应用程序提供。您可以在 SAR 中使用这两种应用程序之一来创建您自己的 Lambda 函数。
-
AthenaHiveMetastoreFunction– Uber Lambda 函数.jar文件。“uber”JAR(也称为 fat JAR 或具有依赖关系的 JAR)是.jar文件,该文件在单个文件中同时包含 Java 程序及其依赖关系。 -
AthenaHiveMetastoreFunctionWithLayer– Lambda 层和 thin Lambda 函数.jar文件。
工作流
下图说明了 Athena 如何与外部 Hive 元数据仓进行交互。
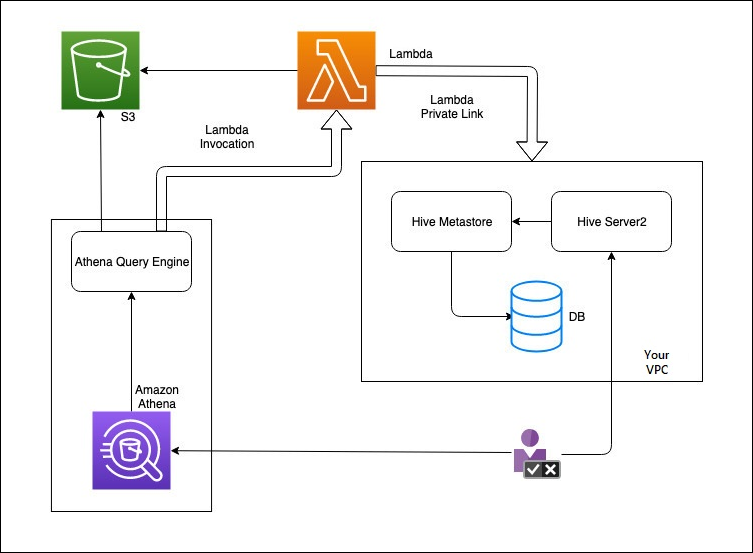
在此工作流程中,您的数据库连接的 Hive 元存储位于您的 VPC 中。您使用 Hive Server2 通过 Hive CLI 管理 Hive 元存储。
使用来自 Athena 的外部 Hive 元数据仓的工作流程包括以下步骤。
-
创建一个 Lambda 函数以将 Athena 连接到 VPC 中的 Hive 元数据仓。
-
为 Hive 元存储注册唯一目录名称,并在账户中注册相应的函数名称。
-
当您运行使用目录名称的 Athena DML 或 DDL 查询时,Athena 查询引擎将调用与目录名称关联的 Lambda 函数名称。
-
使用 Amazon PrivateLink,Lambda 函数与 VPC 中的外部 Hive 元数据仓进行通信,并接收对元数据请求的响应。Athena 使用外部 Hive 元数据仓中的元数据,就像使用默认 Amazon Glue Data Catalog 中的元数据一样。
注意事项和限制
在为外部 Hive 元数据仓使用 Athena 数据连接器时,请考虑以下几点:
-
您可以使用 CTAS 在外部 Hive 元存储上创建表。
-
您可以使用 INSERT INTO 将数据插入到外部 Hive 元存储中。
-
对外部 Hive 元数据仓的 DDL 支持仅限于以下语句。
-
ALTER DATABASE SET DBPROPERTIES
-
ALTER TABLE ADD COLUMNS
-
ALTER TABLE ADD PARTITION
-
ALTER TABLE DROP PARTITION
-
ALTER TABLE RENAME PARTITION
-
ALTER TABLE REPLACE COLUMNS
-
ALTER TABLE SET LOCATION
-
ALTER TABLE SET TBLPROPERTIES
-
CREATE DATABASE
-
CREATE TABLE
-
CREATE TABLE AS
-
DESCRIBE TABLE
-
DROP DATABASE
-
DROP TABLE
-
SHOW COLUMNS
-
SHOW CREATE TABLE
-
SHOW PARTITIONS
-
SHOW SCHEMAS
-
SHOW TABLES
-
SHOW TBLPROPERTIES
-
-
您可以拥有的已注册目录的最大数量为 1000。
-
无法对 Hive 元存储进行 Kerberos 身份验证。
-
若要将 JDBC 驱动程序与外部 Hive 元数据仓或联合查询结合使用,请在 JDBC 连接字符串中包含
MetadataRetrievalMethod=ProxyAPI。有关 JDBC 驱动程序的信息,请参阅 通过 JDBC 连接到 Amazon Athena。 -
Hive 隐藏列
$path、$bucket、$file_size、$file_modified_time、$partition、$row_id不能用于精细访问控制筛选。 -
Hive 的隐藏系统表,例如
example_table$partitionsexample_table$properties
权限
预构建和自定义数据连接器可能需要访问以下资源才能正常工作。检查您使用的连接器的信息,以确保您已正确配置 VPC。有关在 Athena 中运行查询和创建数据源连接器所需的 IAM 权限的信息,请参阅 允许访问适用于外部配置 Hive 元存储的 Athena 数据连接器 和 允许 Lambda 函数访问外部 Hive 元存储。
-
Amazon S3 – 除了将查询结果写入 Amazon S3 中的 Athena 查询结果位置之外,数据连接器还会写入到 Amazon S3 中的溢出存储桶。此 Amazon S3 位置的连接和权限是必需的。有关更多信息,请参阅本主题后面的Amazon S3 中的溢出位置。
-
Athena – 需要访问权限才能检查查询状态并防止过度扫描。
-
Amazon Glue – 如果您的连接器将 Amazon Glue 用于补充元数据或主元数据,则需要访问权限。
-
Amazon Key Management Service
-
策略 – 除了 Amazon 托管策略:AmazonAthenaFullAccess,Hive 元数据仓、Athena Query Federation 和 UDF 需要策略。有关更多信息,请参阅 Athena 中的 Identity and Access Management。
Amazon S3 中的溢出位置
由于对 Lambda 函数响应大小的限制,则大于阈值的响应会溢出到您在创建 Lambda 函数时指定的 Amazon S3 位置。Athena 直接从 Amazon S3 读取这些响应。
注意
Athena 不会删除 Amazon S3 上的响应文件。我们建议您设置保留策略以自动删除响应文件。