本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
使用以下命令启动 DLAMI 实例 Amazon Neuron
最新的 DLAMI 已准备好 Amazon 与 Inferentia 一起使用,并附带 Neuron API 包。 Amazon 要启动 DLAMI 实例,请参阅启动和配置 DLAMI。获得 DLAMI 后,请使用此处的步骤确保 Amazon 您的推理芯片 Amazon 和 Neuron 资源处于活动状态。
验证您的实例
在使用您的实例之前,验证该实例是否已针对 Neuron 进行正确的设置和配置。
识别 Amazon 推理设备
要确定实例上的 Inferentia 设备数量,请使用以下命令:
neuron-ls
如果您的实例已附加了 Inferentia 设备,则输出将如下所示:
+--------+--------+--------+-----------+--------------+ | NEURON | NEURON | NEURON | CONNECTED | PCI | | DEVICE | CORES | MEMORY | DEVICES | BDF | +--------+--------+--------+-----------+--------------+ | 0 | 4 | 8 GB | 1 | 0000:00:1c.0 | | 1 | 4 | 8 GB | 2, 0 | 0000:00:1d.0 | | 2 | 4 | 8 GB | 3, 1 | 0000:00:1e.0 | | 3 | 4 | 8 GB | 2 | 0000:00:1f.0 | +--------+--------+--------+-----------+--------------+
提供的输出取自 Inf1.6xlarge 实例,包括以下各列:
-
神经元设备:分配给的逻辑 ID。 NeuronDevice此 ID 用于将多个运行时配置为使用不同的 NeuronDevices运行时。
-
NEURON CORE: NeuronCores 存在于 NEURON CORES 中的 NeuronDevice数量。
-
神经元内存:中的 DRAM 内存量。 NeuronDevice
-
连接的设备:其他 NeuronDevices 连接到 NeuronDevice。
-
PCI BDF:的 PCI 总线设备功能 (BDF) ID。 NeuronDevice
查看资源使用量
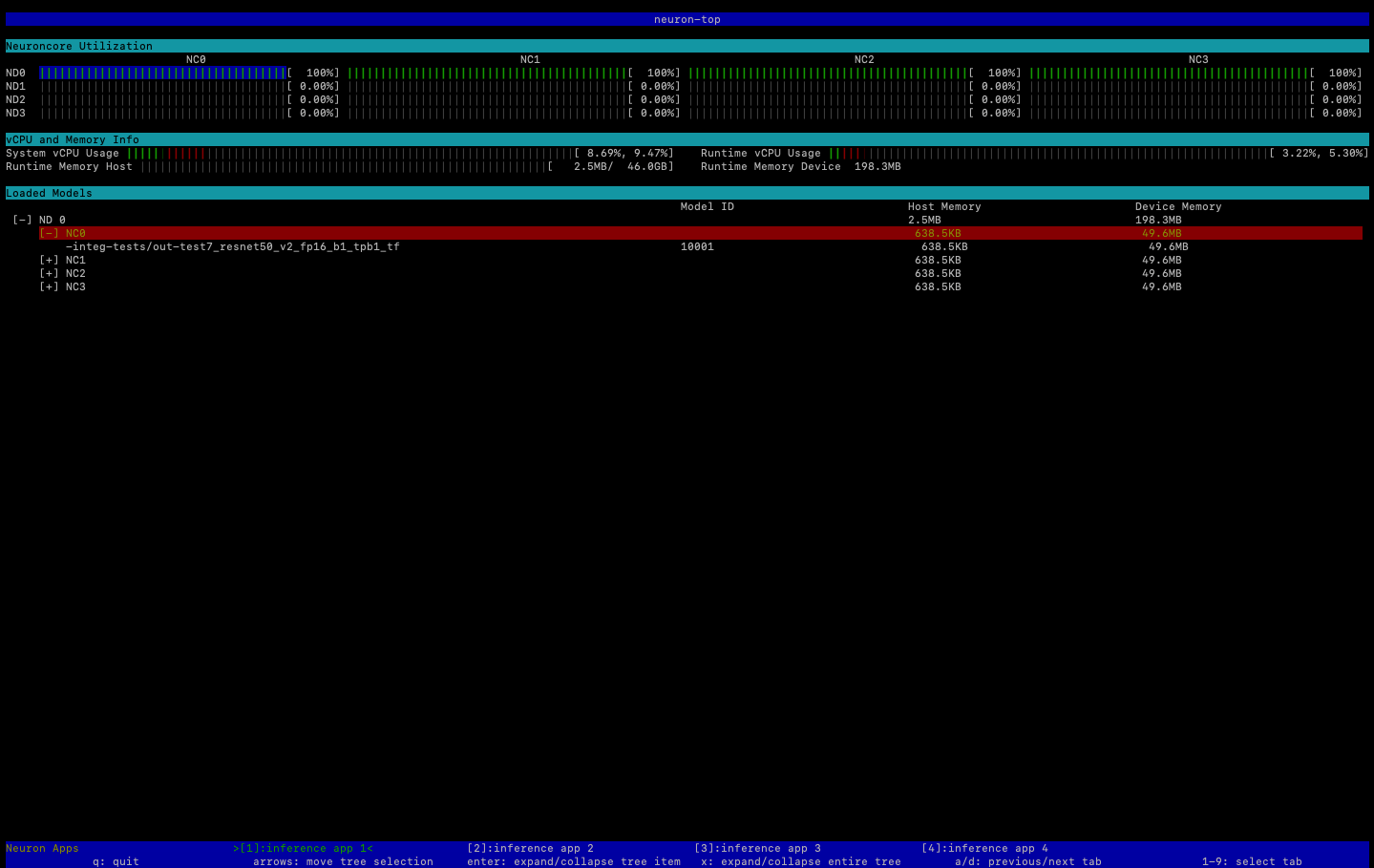
使用命令查看有关 NeuronCore vCPU 利用率、内存使用率、已加载模型和 Neuron 应用程序的有用信息。neuron-top不neuron-top带参数启动将显示所有使用的机器学习应用程序的数据 NeuronCores。
neuron-top
当应用程序使用四时 NeuronCores,输出应类似于下图:
有关用于监控和优化 Neuron-based 推理应用程序的资源的更多信息,请参阅 Neuron 工具
使用 Neuron Monitor(Neuron 监视器)
Neuron Monitor 从系统上运行的 Neuron 运行时系统收集指标,并将收集的数据以 JSON 格式流式传输到 stdout。这些指标按指标组进行组织,您可以通过提供配置文件进行配置。有关 Neuron Monitor 的更多信息,请参阅 Neuron Monitor 用户指南
升级 Neuron 软件
有关如何在 DLAMI 中更新 Neuron SDK 软件的信息,请参阅 Amazon 《神经元设置指南》。