本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
使用 Babelfish 作为目标 Amazon Database Migration Service
你可以使用将数据从 Microsoft SQL Server 源数据库迁移到 Babelfish 目标。 Amazon Database Migration Service
Aurora PostgreSQL 的 Babelfish 扩展了您的 Amazon Aurora PostgreSQL 兼容版数据库,能够接受来自 Microsoft SQL Server 客户端的数据库连接。这样做可以让最初为 SQL Server 构建的应用程序可以直接与 Aurora PostgreSQL 协作,与传统迁移相比,代码更改很少,而且无需更改数据库驱动程序。
有关 Amazon DMS 支持作为目标的 Babelfish 版本的信息,请参阅。的目标 Amazon DMS在使用 Babelfish 端点之前,需要升级 Aurora PostgreSQL 上 Babelfish 的早期版本。
注意
Aurora PostgreSQL 目标端点是将数据迁移到 Babelfish 的首选方式。有关更多信息,请参阅 将适用于 Aurora PostgreSQL 的 Babelfish 作为目标。
有关使用 Babelfish 作为数据库端点的信息,请参阅《Amazon Aurora 用户指南》中的适用于 Aurora PostgreSQL 的 Babelfish。
使用 Babelfish 作为目标的先决条件 Amazon DMS
在迁移数据之前,必须创建表,以确保表 Amazon DMS 使用正确的数据类型和表元数据。如果您在运行迁移之前未在目标上创建表,则 Amazon DMS 可能会使用不正确的数据类型和权限创建表。例如,改为将时间戳列 Amazon DMS 创建为二进制 (8),但不提供预期的 timestamp/rowversion 功能。
在迁移之前准备和创建表
-
运行包含任何唯一约束、主键或默认约束的创建表 DDL 语句。
请勿为视图、存储过程、函数或触发器等对象包含外键约束或任何 DDL 语句。您可以在迁移源数据库后应用它们。
-
为您的表标识任何标识列、计算列或包含行版本或时间戳数据类型的列。然后,创建必要的转换规则,以便在运行迁移任务时处理已知问题。有关更多信息,请参阅转换规则和操作。
-
识别包含 Babelfish 不支持的数据类型的列。然后,将目标表中受影响的列更改为使用支持的数据类型,或者创建在迁移任务期间将这些列删除的转换规则。有关更多信息,请参阅转换规则和操作。
下表列出了 Babelfish 不支持的源数据类型,以及推荐使用的相应目标数据类型。
源数据类型
推荐的 Babelfish 数据类型
HEIRARCHYID
NVARCHAR(250)
GEOMETRY
VARCHAR(MAX)
GEOGRAPHY
VARCHAR(MAX)
为 Aurora PostgreSQL Serverless V2 源数据库设置 Aurora 容量单位 (ACUs) 级别
在运行 Amazon DMS 迁移任务之前,您可以通过设置最小 ACU 值来提高其性能。
-
在 Sev erless v2 容量设置窗口中,将 Aurora 数据库集群的最小 ACUs容量设置为或合理级别。
2有关设置 Aurora 容量单位的其他信息,请参阅《Amazon Aurora 用户指南》中的为 Aurora 集群选择 Aurora Serverless v2 容量范围。
运行 Amazon DMS 迁移任务后,您可以将 Aurora PostgreSQL Serverless V2 源数据库的最小值重置为合理级别。 ACUs
使用 Babelfish 作为目标时的安全要求 Amazon Database Migration Service
以下内容描述了与 Babelfish Amazon DMS 目标一起使用的安全要求:
-
用于创建数据库的管理员用户名(管理员用户)。
-
PSQL 登录角色和具有足够的 SELECT、INSERT、UPDATE、DELETE 和 REFERENCES 权限的用户。
使用 Babelfish 作为目标的用户权限 Amazon DMS
重要
出于安全目的,用于数据迁移的用户账户,必须是您作为目标的任意 Babelfish 数据库中的注册用户。
您的 Babelfish 目标端点需要最低的用户权限才能运行 Amazon DMS 迁移。
创建登录角色和低权限的 Transact-SQL(T-SQL)用户
-
创建连接到服务器时使用的登录角色和密码。
CREATE LOGIN dms_user WITH PASSWORD ='password'; GO -
为您的 Babelfish 集群创建虚拟数据库。
CREATE DATABASE my_database; GO -
为您的目标数据库创建 T-SQL 用户。
USE my_database GO CREATE USER dms_user FOR LOGIN dms_user; GO -
对于 Babelfish 数据库中的每个表,授予对于这些表的权限。
GRANT SELECT, DELETE, INSERT, REFERENCES, UPDATE ON [dbo].[Categories] TO dms_user;
使用 Babelfish 作为目标的限制 Amazon Database Migration Service
将 Babelfish 数据库作为 Amazon DMS目标时,存在以下限制:
-
仅支持不进行任何操作的表准备模式。
-
ROWVERSION 数据类型需要一个表映射规则,该规则可在迁移任务期间从表中删除列名。
-
不支持 sql_variant 数据类型。
-
支持完整 LOB 模式。使用 SQL Server 作为源端点需要设置
ForceFullLob=TrueSQL Server 端点连接属性设置才能迁移到目标端点。 LOBs -
复制任务设置具有以下限制:
{ "FullLoadSettings": { "TargetTablePrepMode": "DO_NOTHING", "CreatePkAfterFullLoad": false, }. } -
Babelfish 中的时间 DATETIME2 (7)、(7) 和 DATETIMEOFFSET (7) 数据类型将时间中秒部分的精度值限制为 6 位数。使用这些数据类型时,请考虑对目标表使用精度值 6。对于 Babelfish 2.2.0 及更高版本,当使用 TIME (7) 和 DATETIME2 (7) 时,精度的第七位数始终为零。
-
在 DO_NOTHING 模式下,DMS 会检查此表是否已存在。如果目标架构中不存在此表,DMS 会根据源表定义创建表,并将任何用户定义的数据类型映射到其基本数据类型。
-
向 Babelfish 目标的 Amazon DMS 迁移任务不支持具有使用 ROWVERSION 或 TIMESTAMP 数据类型的列的表。您可以使用表映射规则,此规则可在传输过程中从表中删除列名。在以下转换规则示例中,源中名为
Actor的表经过转换后从目标上的Actor中删除了以字符col开头的所有列。{ "rules": [{ "rule-type": "selection",is "rule-id": "1", "rule-name": "1", "object-locator": { "schema-name": "test", "table-name": "%" }, "rule-action": "include" }, { "rule-type": "transformation", "rule-id": "2", "rule-name": "2", "rule-action": "remove-column", "rule-target": "column", "object-locator": { "schema-name": "test", "table-name": "Actor", "column-name": "col%" } }] } -
对于具有标识列或计算列的表,如果目标表使用混合大小写的名称(如 Categories),则必须创建转换规则操作,以便在 DMS 任务中将表名转换为小写形式。以下示例说明如何使用 Amazon DMS 控制台创建转换规则操作 “变为小写”。有关更多信息,请参阅 转换规则和操作。
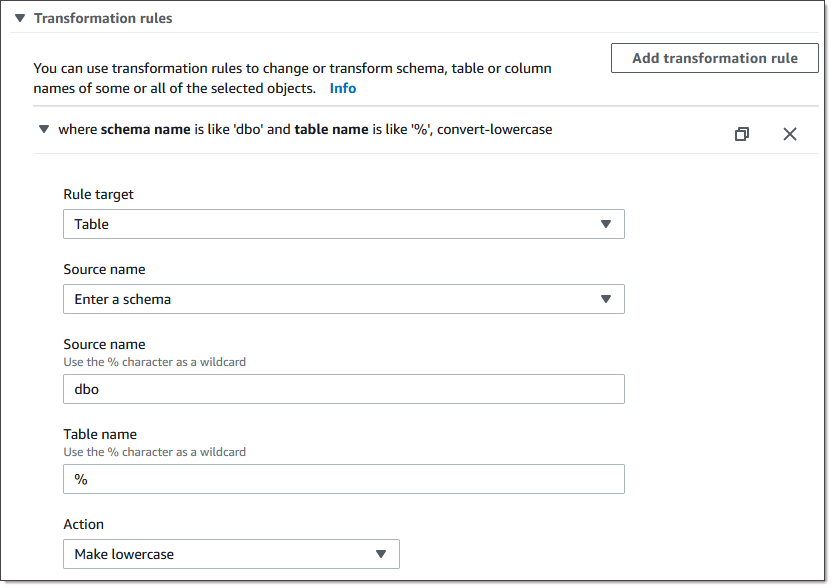
-
对于 2.2.0 之前的 Babelfish 版本,DMS 将可以复制到 Babelfish 目标端点的列数限制为二十(20)列。在 Babelfish 2.2.0 中,此限制增加到 100 列。但在 Babelfish 2.4.0 及更高版本中,您可以复制的列数再次增加。您可以对 SQL Server 数据库运行以下代码示例,以确定哪些表太长。
USE myDB; GO DECLARE @Babelfish_version_string_limit INT = 8000; -- Use 380 for Babelfish versions before 2.2.0 WITH bfendpoint AS ( SELECT [TABLE_SCHEMA] ,[TABLE_NAME] , COUNT( [COLUMN_NAME] ) AS NumberColumns , ( SUM( LEN( [COLUMN_NAME] ) + 3) + SUM( LEN( FORMAT(ORDINAL_POSITION, 'N0') ) + 3 ) + LEN( TABLE_SCHEMA ) + 3 + 12 -- INSERT INTO string + 12) AS InsertIntoCommandLength -- values string , CASE WHEN ( SUM( LEN( [COLUMN_NAME] ) + 3) + SUM( LEN( FORMAT(ORDINAL_POSITION, 'N0') ) + 3 ) + LEN( TABLE_SCHEMA ) + 3 + 12 -- INSERT INTO string + 12) -- values string >= @Babelfish_version_string_limit THEN 1 ELSE 0 END AS IsTooLong FROM [INFORMATION_SCHEMA].[COLUMNS] GROUP BY [TABLE_SCHEMA], [TABLE_NAME] ) SELECT * FROM bfendpoint WHERE IsTooLong = 1 ORDER BY TABLE_SCHEMA, InsertIntoCommandLength DESC, TABLE_NAME ;
Babelfish 的目标数据类型
下表显示了使用时支持的 Babelfish 目标数据类型 Amazon DMS 以及 Amazon DMS 数据类型的默认映射。
有关 Amazon DMS 数据类型的更多信息,请参见Amazon Database Migration Service 的数据类型。
|
Amazon DMS 数据类型 |
Babelfish 数据类型 |
|---|---|
|
BOOLEAN |
TINYINT |
|
BYTES |
VARBINARY(length) |
|
DATE |
DATE |
|
TIME |
TIME |
|
INT1 |
SMALLINT |
|
INT2 |
SMALLINT |
|
INT4 |
INT |
|
INT8 |
BIGINT |
|
NUMERIC |
NUMERIC (p,s) |
|
REAL4 |
REAL |
|
REAL8 |
FLOAT |
|
STRING |
如果列是日期或时间列,请执行以下操作:
如果列不是日期或时间列,请使用 VARCHAR (length)。 |
|
UINT1 |
TINYINT |
|
UINT2 |
SMALLINT |
|
UINT4 |
INT |
|
UINT8 |
BIGINT |
|
WSTRING |
NVARCHAR(长度) |
|
BLOB |
VARBINARY(max) 要在 DMS 中使用此数据类型,必须 BLOBs 为特定任务启用使用。DMS 仅在包含主键的表中支持 BLOB 数据类型。 |
|
CLOB |
VARCHAR(max) 要在 DMS 中使用此数据类型,必须 CLOBs 为特定任务启用使用。 |
|
NCLOB |
NVARCHAR(max) 要在 DMS 中使用此数据类型,必须 NCLOBs 为特定任务启用使用。在 CDC 期间,DMS 仅在包含主键的表中支持 NCLOB 数据类型。 |