本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
JDBC 自动生成架构
Amazon DocumentDB 是一个文档数据库,因此没有表和架构的概念。但是,像 Tableau 这样的商业智能工具会期望它所连接的数据库能够呈现架构。具体而言,当 JDBC 驱动程序连接需要获取数据库中集合的架构时,它将轮询数据库中的所有集合。驱动程序将确定该集合的架构的缓存版本是否已存在。如果缓存版本不存在,它将对文档集合进行采样,并基于以下行为创建架构。
架构生成限制
DocumentDB JDBC 驱动程序将标识符的长度限制为 128 个字符。架构生成器可能会截断生成的标识符(表名和列名)的长度,以确保它们符合该限制。
扫描方法选项
可以使用连接字符串或数据来源选项修改采样行为。
-
scanMethod= <选项>
-
random -(默认):按随机顺序返回示例文档。
-
idForward:按 id 顺序返回示例文档。
-
idReverse:按 id 的相反顺序返回示例文档。
-
all:对集合中的所有文档进行采样。
-
-
scanLimit=<n>:要采样的文档数。该值必须为正整数。默认值是 1000。如果 scanMethod 设置为 all,则忽略此选项。
Amazon DocumentDB 数据类型
Amazon DocumentDB 服务器支持多种 MongoDB 数据类型。下面列出了支持的数据类型及其关联的 JDBC 数据类型。
| MongoDB 数据类型 | DocumentDB 支持 | JDBC 数据类型 |
|---|---|---|
| 二进制数据 | 是 | VARBINARY |
| 布尔值 | 是 | BOOLEAN |
| 双精度 | 是 | DOUBLE |
| 32 位整数 | 是 | INTEGER |
| 64 位整数 | 是 | BIGINT |
| 字符串 | 是 | VARCHAR |
| ObjectId | 是 | VARCHAR |
| 日期 | 是 | TIMESTAMP |
| Null | 是 | VARCHAR |
| 正则表达式 | 是 | VARCHAR |
| Timestamp | 是 | VARCHAR |
| MinKey | 是 | VARCHAR |
| MaxKey | 是 | VARCHAR |
| 对象 | 是 | 虚拟表 |
| 数组 | 是 | 虚拟表 |
| Decimal128 | 否 | DECIMAL |
| JavaScript | 否 | VARCHAR |
| JavaScript (带瞄准镜) | 否 | VARCHAR |
| 未定义 | 否 | VARCHAR |
| 符号 | 否 | VARCHAR |
| DBPointer (4.0+) | 否 | VARCHAR |
映射标量文档字段
当扫描集合中的文档样本时,JDBC 驱动程序将创建一个或多个架构来表示集合中的样本。通常,文档中的标量字段会映射到表架构中的一列。例如,在名为 team 的集合和单个文档 { "_id" : "112233", "name" :
"Alastair", "age": 25 } 中,这将映射到架构:
| 表名称 | 列名称 | 数据类型 | Key |
|---|---|---|---|
| team | team id | VARCHAR | PK |
| team | 名称 | VARCHAR | |
| team | age | INTEGER |
数据类型冲突提升
扫描样本文档时,文档之间的字段数据类型可能不一致。在这种情况下,JDBC 驱动程序会将 JDBC 数据类型提升为通用数据类型,该数据类型将适合采样文档中的所有数据类型。
例如:
{ "_id" : "112233", "name" : "Alastair", "age" : 25 } { "_id" : "112244", "name" : "Benjamin", "age" : "32" }
age 字段在第一个文档中为 32 位整数类型,但在第二个文档中为字符串。在这里,JDBC 驱动程序会将 JDBC 数据类型提升为 VARCHAR,以便在遇到任一数据类型时进行处理。
| 表名称 | 列名称 | 数据类型 | Key |
|---|---|---|---|
| team | team id | VARCHAR | PK |
| team | 名称 | VARCHAR | |
| team | age | VARCHAR |
标量-标量冲突提升
下图显示了标量-标量数据类型冲突的解决方法。
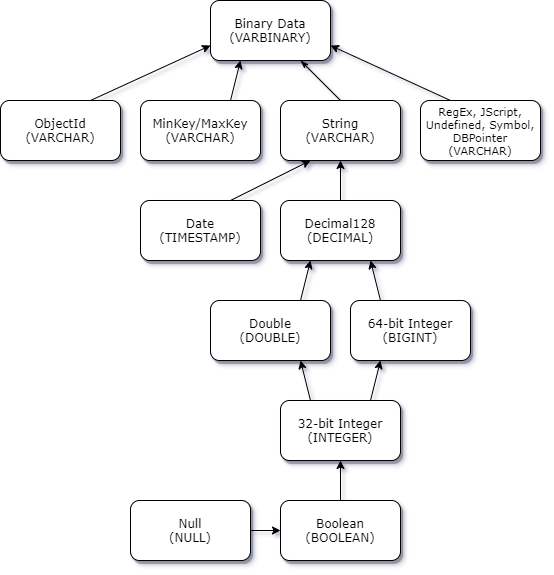
标量-复数类型冲突提升
与标量-标量类型冲突一样,不同文档中的同一字段在复数(数组和对象)和标量(整数、布尔值等)之间可能存在冲突的数据类型。对于这些字段,所有这些冲突都已解决(提升)为 VARCHAR。在这种情况下,数组和对象数据以 JSON 表示形式返回。
嵌入式数组:字符串字段冲突示例:
{ "_id":"112233", "name":"George Jackson", "subscriptions":[ "Vogue", "People", "USA Today" ] } { "_id":"112244", "name":"Joan Starr", "subscriptions":1 }
上述示例映射到 customer2 表的架构:
| 表名称 | 列名称 | 数据类型 | Key |
|---|---|---|---|
| customer2 | customer2 id | VARCHAR | PK |
| customer2 | name | VARCHAR | |
| customer2 | 订阅 | VARCHAR |
和 customer1_subscriptions 虚拟表:
| 表名称 | 列名称 | 数据类型 | Key |
|---|---|---|---|
| customer1_subscriptions | customer1 id | VARCHAR | PK/FK |
| customer1_subscriptions | subscriptions_index_lvl0 | BIGINT | PK |
| customer1_subscriptions | 值 | VARCHAR | |
| customer_address | city | VARCHAR | |
| customer_address | region | VARCHAR | |
| customer_address | country | VARCHAR | |
| customer_address | 代码 | VARCHAR |
对象和数组数据类型处理
到目前为止,我们只描述了标量数据类型的映射方式。对象和数组数据类型(当前)映射到虚拟表。JDBC 驱动程序将创建一个虚拟表来表示文档中的对象或数组字段。映射的虚拟表的名称将连接原始集合的名称,后跟由下划线字符(“_”)分隔的字段名称。
基表的主键(“_id”)在新虚拟表中采用新名称,并作为外键提供给关联的基表。
对于嵌入式数组类型字段,会生成索引列来表示数组每个级别的索引。
嵌入式对象字段示例
对于文档中的对象字段,JDBC 驱动程序会创建到虚拟表的映射。
{ "Collection: customer", "_id":"112233", "name":"George Jackson", "address":{ "address1":"123 Avenue Way", "address2":"Apt. 5", "city":"Hollywood", "region":"California", "country":"USA", "code":"90210" } }
上述示例映射到 customer 表的架构:
| 表名称 | 列名称 | 数据类型 | Key |
|---|---|---|---|
| customer | customer id | VARCHAR | PK |
| customer | name | VARCHAR |
和 customer_address 虚拟表:
| 表名称 | 列名称 | 数据类型 | Key |
|---|---|---|---|
| customer_address | customer id | VARCHAR | PK/FK |
| customer_address | address1 | VARCHAR | |
| customer_address | address2 | VARCHAR | |
| customer_address | city | VARCHAR | |
| customer_address | region | VARCHAR | |
| customer_address | country | VARCHAR | |
| customer_address | 代码 | VARCHAR |
嵌入式数组字段示例
对于文档中的数组字段,JDBC 驱动程序还会创建到虚拟表的映射。
{ "Collection: customer1", "_id":"112233", "name":"George Jackson", "subscriptions":[ "Vogue", "People", "USA Today" ] }
上述示例映射到 customer1 表的架构:
| 表名称 | 列名称 | 数据类型 | Key |
|---|---|---|---|
| customer1 | customer1 id | VARCHAR | PK |
| customer1 | name | VARCHAR |
和 customer1_subscriptions 虚拟表:
| 表名称 | 列名称 | 数据类型 | Key |
|---|---|---|---|
| customer1_subscriptions | customer1 id | VARCHAR | PK/FK |
| customer1_subscriptions | subscriptions_index_lvl0 | BIGINT | PK |
| customer1_subscriptions | 值 | VARCHAR | |
| customer_address | city | VARCHAR | |
| customer_address | region | VARCHAR | |
| customer_address | country | VARCHAR | |
| customer_address | 代码 | VARCHAR |