本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
使用 Performance Insights API 检索指标
启用 Performance Insights 后,API 将提供实例性能的可见性。Ama CloudWatch zon Logs 为 Amazon 服务的销售监控指标提供了权威来源。
Performance Insights 提供了按平均活动会话 (AAS) 衡量的数据库负载的特定于域的视图。对 API 使用者而言,此指标看起来像是二维时间序列数据集。数据的时间维度提供所查询时间范围的每个时间点的数据库负载数据。每个时间点将分解与所请求维度相关的整体负载,如相应时间点测量的 Query、Wait-state、Application 或 Host。
Amazon DocumentDB Performance Insights 用于监控您的 Amazon DocumentDB 数据库实例,使您可以分析数据库性能和排查数据库性能问题。查看 Performance Insights 数据的一种方法是在 Amazon Web Services 管理控制台中。Performance Insights 还提供公有 API,以便您可以查询自己的数据。您可以使用 API 来执行以下操作:
-
将数据卸载到数据库中
-
将 Performance Insights 数据添加到现有监控控制面板
-
构建监控工具
要使用 Performance Insights API,请在您的 Amazon DocumentDB 实例之一上启用 Performance Insights。有关启用 Performance Insights 的信息,请参阅 启用和禁用 Performance Insights。有关性能详情 API 的更多信息,请参阅性能详情 API 参考。
Performance Insights API 提供以下操作。
|
Performance Insights 操作 |
Amazon CLI 命令 |
说明 |
|---|---|---|
|
对于特定的时间段,检索指标的前 N 个维度键。 |
||
|
检索数据库实例或数据来源的指定维度组的属性。例如,如果您指定了查询 ID,并且有维度详细信息,则 |
||
GetResourceMetadata |
检索不同功能的元数据。例如,元数据可以表明特定数据库实例上的某个功能已打开或关闭。 |
|
|
检索一组数据来源在一段时间内的 Performance Insights 指标。您可以提供特定维度组和维度,并为每个组提供聚合和筛选条件。 |
||
ListAvailableResourceDimensions |
检索特定实例上每个特定指标类型可查询的维度。 |
|
ListAvailableResourceMetrics |
检索指定指标类型的所有可用指标,指定数据库实例可用该指标进行查询。 |
Amazon CLI 获取性能见解
您可以使用 Amazon CLI查看 Performance Insights 数据。可以通过在命令行上输入以下内容来查看 Performance Insights 的 Amazon CLI 命令的帮助。
aws pi help
如果您尚未 Amazon CLI 安装,请参阅Amazon CLI 用户指南中的安装 Amazon 命令行界面,了解有关安装命令行界面的信息。
检索时间序列指标
GetResourceMetrics 操作从 Performance Insights 数据中检索一个或多个时间序列指标。GetResourceMetrics 需要指标和时间段,并返回包含数据点列表的响应。
例如, Amazon Web Services 管理控制台 用于GetResourceMetrics填充 “计数器指标” 图表和 “数据库负载” 图表,如下图所示。
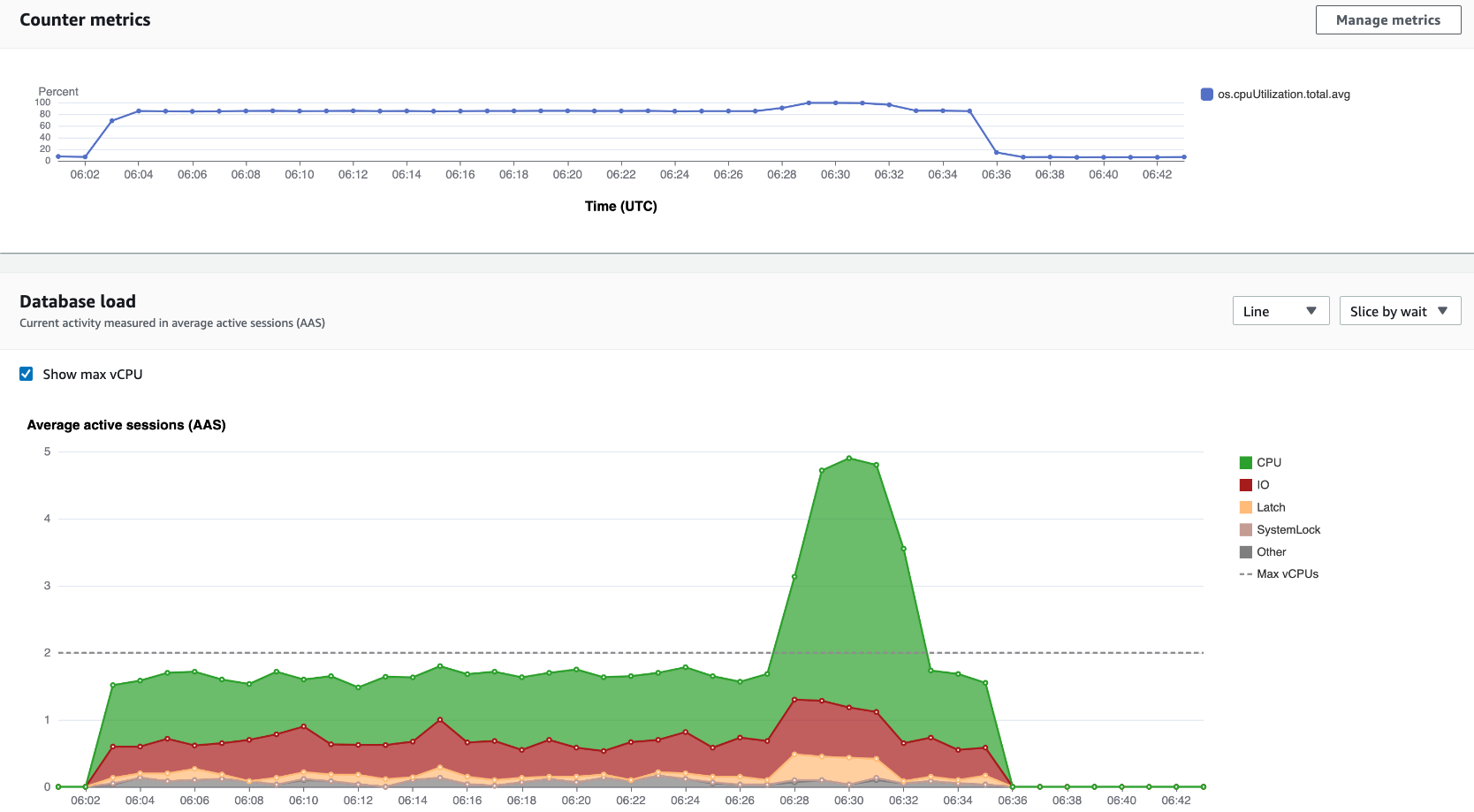
GetResourceMetrics 返回的所有指标都是标准的时间序列指标,但 db.load 除外。此指标显示在 Database Load (数据库负载) 图表中。db.load 指标不同于其他时间序列指标,因为您可以将它分为称为维度的子组件。在上图中,按组成 db.load 的等待状态对 db.load 进行细分和分组。
注意
GetResourceMetrics 也可以返回 db.sampleload 指标,但 db.load 指标在大多数情况下是合适的。
有关 GetResourceMetrics 返回的计数器指标的信息,请参阅Performance Insights 的计数器指标。
指标支持以下计算:
-
平均值:指标在一段时间内的平均值。在指标名称后面附加
.avg。 -
最小值:指标在一段时间内的最小值。在指标名称后面附加
.min。 -
最大值:指标在一段时间内的最大值。在指标名称后面附加
.max。 -
总计:指标值在一段时间内的总计。在指标名称后面附加
.sum。 -
样本数:在一段时间内收集指标的次数。在指标名称后面附加
.sample_count。
例如,假定在 300 秒(5 分钟)时段内收集指标,并且每分钟收集一次指标。各分钟的值为 1、2、3、4 和 5。在本例中,返回以下计算:
-
平均值:3
-
最小值:1
-
最大值:5
-
总计:15
-
样本数:5
有关使用该get-resource-metrics Amazon CLI 命令的信息,请参见get-resource-metrics。
对于 --metric-queries 选项,请指定一个或多个要获取其结果的查询。每个查询包括必需的 Metric 和可选的 GroupBy 和 Filter 参数。以下是 --metric-queries 选项规范的示例。
{ "Metric": "string", "GroupBy": { "Group": "string", "Dimensions": ["string", ...], "Limit": integer }, "Filter": {"string": "string" ...}
Amazon CLI 性能 Insights 的示例
以下示例说明了如何使用 Performance Insights 的。 Amazon CLI
检索计数器指标
以下屏幕截图显示 Amazon Web Services 管理控制台中的两个计数器指标图表。
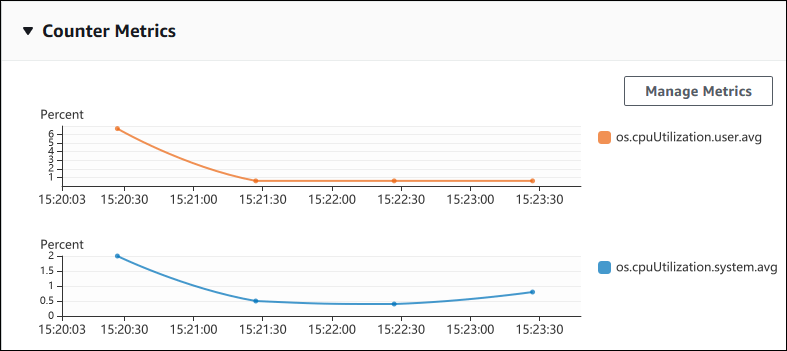
以下示例显示如何收集 Amazon Web Services 管理控制台 用于生成两个计数器指标图表的相同数据。
对于 Linux、macOS 或 Unix:
aws pi get-resource-metrics \ --service-type DOCDB \ --identifier db-ID\ --start-time2022-03-13T8:00:00Z\ --end-time2022-03-13T9:00:00Z\ --period-in-seconds60\ --metric-queries '[{"Metric": "os.cpuUtilization.user.avg" }, {"Metric": "os.cpuUtilization.idle.avg"}]'
对于 Windows:
aws pi get-resource-metrics ^ --service-type DOCDB ^ --identifier db-ID^ --start-time2022-03-13T8:00:00Z^ --end-time2022-03-13T9:00:00Z^ --period-in-seconds60^ --metric-queries '[{"Metric": "os.cpuUtilization.user.avg" }, {"Metric": "os.cpuUtilization.idle.avg"}]'
还可以通过为 --metrics-query 选项指定文件来使命令更易于读取。以下示例为该选项使用名为 query.json 的文件。此文件具有以下内容。
[ { "Metric": "os.cpuUtilization.user.avg" }, { "Metric": "os.cpuUtilization.idle.avg" } ]
运行以下命令来使用此文件。
对于 Linux、macOS 或 Unix:
aws pi get-resource-metrics \ --service-type DOCDB \ --identifier db-ID\ --start-time2022-03-13T8:00:00Z\ --end-time2022-03-13T9:00:00Z\ --period-in-seconds60\ --metric-queries file://query.json
对于 Windows:
aws pi get-resource-metrics ^ --service-type DOCDB ^ --identifier db-ID^ --start-time2022-03-13T8:00:00Z^ --end-time2022-03-13T9:00:00Z^ --period-in-seconds60^ --metric-queries file://query.json
上一个示例为各选项指定了以下值:
-
--service-type:DOCDB适用于 Amazon DocumentDB -
--identifier:数据库实例的资源 ID -
--start-time和--end-time:要查询的期间的 ISO 8601DateTime值,支持多种格式
它查询一小时时间范围:
-
--period-in-seconds:对于每分钟查询来说为60 -
--metric-queries:两个查询的数组,每个查询只用于一个指标。指标名称使用点在有用的类别中分类指标,最后一个元素是函数。在示例中,对于每个查询来说,此函数是
avg。与 Amazon 一样 CloudWatch,支持的函数有minmax、total、和avg。
响应类似于以下内容。
{ "AlignedStartTime": "2022-03-13T08:00:00+00:00", "AlignedEndTime": "2022-03-13T09:00:00+00:00", "Identifier": "db-NQF3TTMFQ3GTOKIMJODMC3KQQ4", "MetricList": [ { "Key": { "Metric": "os.cpuUtilization.user.avg" }, "DataPoints": [ { "Timestamp": "2022-03-13T08:01:00+00:00", //Minute1 "Value": 3.6 }, { "Timestamp": "2022-03-13T08:02:00+00:00", //Minute2 "Value": 2.6 }, //.... 60 datapoints for the os.cpuUtilization.user.avg metric { "Key": { "Metric": "os.cpuUtilization.idle.avg" }, "DataPoints": [ { "Timestamp": "2022-03-13T08:01:00+00:00", "Value": 92.7 }, { "Timestamp": "2022-03-13T08:02:00+00:00", "Value": 93.7 }, //.... 60 datapoints for the os.cpuUtilization.user.avg metric ] } ] //end of MetricList } //end of response
响应具有 Identifier、AlignedStartTime 和 AlignedEndTime。但 --period-in-seconds 值为 60,开始和结束时间已与分钟对齐。如果 --period-in-seconds 为 3600,则开始和结束时间已与小时对齐。
响应中的 MetricList 具有许多条目,每个条目具有 Key 和 DataPoints 条目。每个 DataPoint 具有 Timestamp 和 Value。每个 Datapoints 列表具有 60 个数据点,因为查询针对一小时内的每分钟数据,具有 Timestamp1/Minute1、Timestamp2/Minute2 等,一直到 Timestamp60/Minute60。
因为查询用于两个不同的计数器指标,响应 MetricList 中有两个元素。
检索首要等待状态的数据库负载平均值
以下示例与 Amazon Web Services 管理控制台 用于生成堆叠面积折线图的查询相同。此示例检索按前七个等待状态划分负载的最后一个小时的 db.load.avg。命令与 检索计数器指标 中的命令相同。不过,query.json 文件具有以下内容。
[ { "Metric": "db.load.avg", "GroupBy": { "Group": "db.wait_state", "Limit": 7 } } ]
运行以下命令。
对于 Linux、macOS 或 Unix:
aws pi get-resource-metrics \ --service-type DOCDB \ --identifier db-ID\ --start-time2022-03-13T8:00:00Z\ --end-time2022-03-13T9:00:00Z\ --period-in-seconds60\ --metric-queries file://query.json
对于 Windows:
aws pi get-resource-metrics ^ --service-type DOCDB ^ --identifier db-ID^ --start-time2022-03-13T8:00:00Z^ --end-time2022-03-13T9:00:00Z^ --period-in-seconds60^ --metric-queries file://query.json
此示例指定指标 db.load.avg 和前七个等待状态的 GroupBy。有关此示例有效值的详细信息,请参阅 Performance Insights API 参考DimensionGroup中的。
响应类似于以下内容。
{ "AlignedStartTime": "2022-04-04T06:00:00+00:00", "AlignedEndTime": "2022-04-04T06:15:00+00:00", "Identifier": "db-NQF3TTMFQ3GTOKIMJODMC3KQQ4", "MetricList": [ {//A list of key/datapoints "Key": { //A Metric with no dimensions. This is the total db.load.avg "Metric": "db.load.avg" }, "DataPoints": [ //Each list of datapoints has the same timestamps and same number of items { "Timestamp": "2022-04-04T06:01:00+00:00",//Minute1 "Value": 0.0 }, { "Timestamp": "2022-04-04T06:02:00+00:00",//Minute2 "Value": 0.0 }, //... 60 datapoints for the total db.load.avg key ] }, { "Key": { //Another key. This is db.load.avg broken down by CPU "Metric": "db.load.avg", "Dimensions": { "db.wait_state.name": "CPU" } }, "DataPoints": [ { "Timestamp": "2022-04-04T06:01:00+00:00",//Minute1 "Value": 0.0 }, { "Timestamp": "2022-04-04T06:02:00+00:00",//Minute2 "Value": 0.0 }, //... 60 datapoints for the CPU key ] },//... In total we have 3 key/datapoints entries, 1) total, 2-3) Top Wait States ] //end of MetricList } //end of response
在此响应中,MetricList 中有三个条目。有一个有关总 db.load.avg 的条目,还有三个条目,其中每个条目关于按前三个等待状态之一划分的 db.load.avg。由于具有分组维度(与第一个示例不同),所以必须具有一个用于每个指标分组的键。不能像在基本计数器指标使用案例中那样每个指标只有一个键。
检索主要查询的数据库负载平均值
以下示例按前 10 个查询语句对 db.wait_state 进行分组。有两个不同的查询语句组:
-
db.query:完整的查询语句,例如{"find":"customers","filter":{"FirstName":"Jesse"},"sort":{"key":{"$numberInt":"1"}}} -
db.query_tokenized:令牌化的查询语句,例如{"find":"customers","filter":{"FirstName":"?"},"sort":{"key":{"$numberInt":"?"}},"limit":{"$numberInt":"?"}}
在分析数据库性能时,将仅参数不同的查询语句视为一个逻辑项目很有用。因此,您在查询时可以使用 db.query_tokenized。不过,尤其在您对 explain() 感兴趣时,查看带参数的完整查询语句会更有用。令牌化和完整查询之间存在父-子关系,多个完整查询(子级)分组在同一令牌化查询(父级)下。
此示例中的命令类似于 检索首要等待状态的数据库负载平均值 中的命令。不过,query.json 文件具有以下内容。
[ { "Metric": "db.load.avg", "GroupBy": { "Group": "db.query_tokenized", "Limit": 10 } } ]
下面的示例使用了 db.query_tokenized。
对于 Linux、macOS 或 Unix:
aws pi get-resource-metrics \ --service-type DOCDB \ --identifier db-ID\ --start-time2022-03-13T8:00:00Z\ --end-time2022-03-13T9:00:00Z\ --period-in-seconds3600\ --metric-queries file://query.json
对于 Windows:
aws pi get-resource-metrics ^ --service-type DOCDB ^ --identifier db-ID^ --start-time2022-03-13T8:00:00Z^ --end-time2022-03-13T9:00:00Z^ --period-in-seconds3600^ --metric-queries file://query.json
此示例查询时间超过 1 小时,其中 1 分钟 period-in-seconds。
此示例指定指标 db.load.avg 和前七个等待状态的 GroupBy。有关此示例有效值的详细信息,请参阅 Performance Insights API 参考DimensionGroup中的。
响应类似于以下内容。
{ "AlignedStartTime": "2022-04-04T06:00:00+00:00", "AlignedEndTime": "2022-04-04T06:15:00+00:00", "Identifier": "db-NQF3TTMFQ3GTOKIMJODMC3KQQ4", "MetricList": [ {//A list of key/datapoints "Key": { "Metric": "db.load.avg" }, "DataPoints": [ //... 60 datapoints for the total db.load.avg key ] }, { "Key": {//Next key are the top tokenized queries "Metric": "db.load.avg", "Dimensions": { "db.query_tokenized.db_id": "pi-1064184600", "db.query_tokenized.id": "77DE8364594EXAMPLE", "db.query_tokenized.statement": "{\"find\":\"customers\",\"filter\":{\"FirstName\":\"?\"},\"sort\":{\"key\":{\"$numberInt\":\"?\"}},\"limit\" :{\"$numberInt\":\"?\"},\"$db\":\"myDB\",\"$readPreference\":{\"mode\":\"primary\"}}" } }, "DataPoints": [ //... 60 datapoints ] }, // In total 11 entries, 10 Keys of top tokenized queries, 1 total key ] //End of MetricList } //End of response
此响应的 MetricList 中具有 11 个条目(1 个总计,10 个首要令牌化查询),其中每个条目具有 24 个每小时 DataPoints。
对于令牌化查询,每个维度列表中具有三个条目:
-
db.query_tokenized.statement:令牌化的查询语句。 -
db.query_tokenized.db_id:Performance Insights 为您生成的合成 ID。此示例返回pi-1064184600合成 ID。 -
db.query_tokenized.id:Performance Insights 中的查询的 ID。在中 Amazon Web Services 管理控制台,此 ID 被称为 Support ID。之所以这样命名,是因为 ID 是 Su Amazon pport 可以检查的数据,以帮助您解决数据库问题。 Amazon 非常重视数据的安全性和隐私性,几乎所有数据都使用您的数据加密存储 Amazon KMS key。因此,里面没有人 Amazon 可以查看这些数据。在上一个示例中,
tokenized.statement和tokenized.db_id都进行了加密存储。如果您的数据库出现问题,Su Amazon pport 可以通过引用 Support ID 来帮助您。
在查询时,在 Group 中指定 GroupBy 可能很方便。不过,要更精细地控制返回的数据,请指定维度列表。例如,如果所需的所有内容是 db.query_tokenized.statement,则可将 Dimensions 属性添加到 query.json 文件中。
[ { "Metric": "db.load.avg", "GroupBy": { "Group": "db.query_tokenized", "Dimensions":["db.query_tokenized.statement"], "Limit": 10 } } ]
检索按查询筛选的数据库负载平均值
此示例中的相应 API 查询类似于 检索主要查询的数据库负载平均值 中的命令。不过,query.json 文件具有以下内容。
[ { "Metric": "db.load.avg", "GroupBy": { "Group": "db.wait_state", "Limit": 5 }, "Filter": { "db.query_tokenized.id": "AKIAIOSFODNN7EXAMPLE" } } ]
在此响应中,所有值均根据 query.json 文件中指定的标记化查询 AKIAIOSFODNN7示例的贡献进行过滤。键还可能遵循与没有筛选条件的查询不同的顺序,因为前五个等待状态影响了筛选的查询。