帮助改进此页面
要帮助改进本用户指南,请选择位于每个页面右侧窗格中的在 GitHub 上编辑此页面链接。
了解 Amazon EKS 中的 Amazon 应用程序恢复控制器(ARC)可用区转移
Kubernetes 具有原生功能,可让您的应用程序对可用区(AZ)运行状况下降或损坏等事件更具弹性。在 Amazon EKS 集群中运行工作负载时,您可以使用 Amazon 应用程序恢复控制器(ARC)的可用区转移或可用区自动转移,进一步改善应用程序环境的容错能力和应用程序恢复。ARC 可用区转移旨在作为一种临时措施,可让您将资源流量从损坏的可用区转出,直到可用区转移到期或您取消它。如有必要,可以延长可用区转移。
您可以为 EKS 集群启动可用区转移,也可以通过启用可用区自动转移来让 Amazon 为您执行可用区转移。这种转移会更新集群中东-西网络流量,使其仅考虑在运行状况良好的可用区中的 Worker 节点上运行的容器组(pod)的网络端点。此外,任何处理 EKS 集群中应用程序入口流量的 ALB 或 NLB 都会自动将流量路由到运行状况良好的可用区中的目标。对于那些寻求最高可用性目标的客户来说,在可用区损坏的情况下,能够将所有流量从损坏的可用区转移出去可能很重要,直到可用区恢复为止。为此,您还可以启用带有 ARC 可用区转移的 ALB 或 NLB。
了解容器组(pod)之间的东-西网络流量
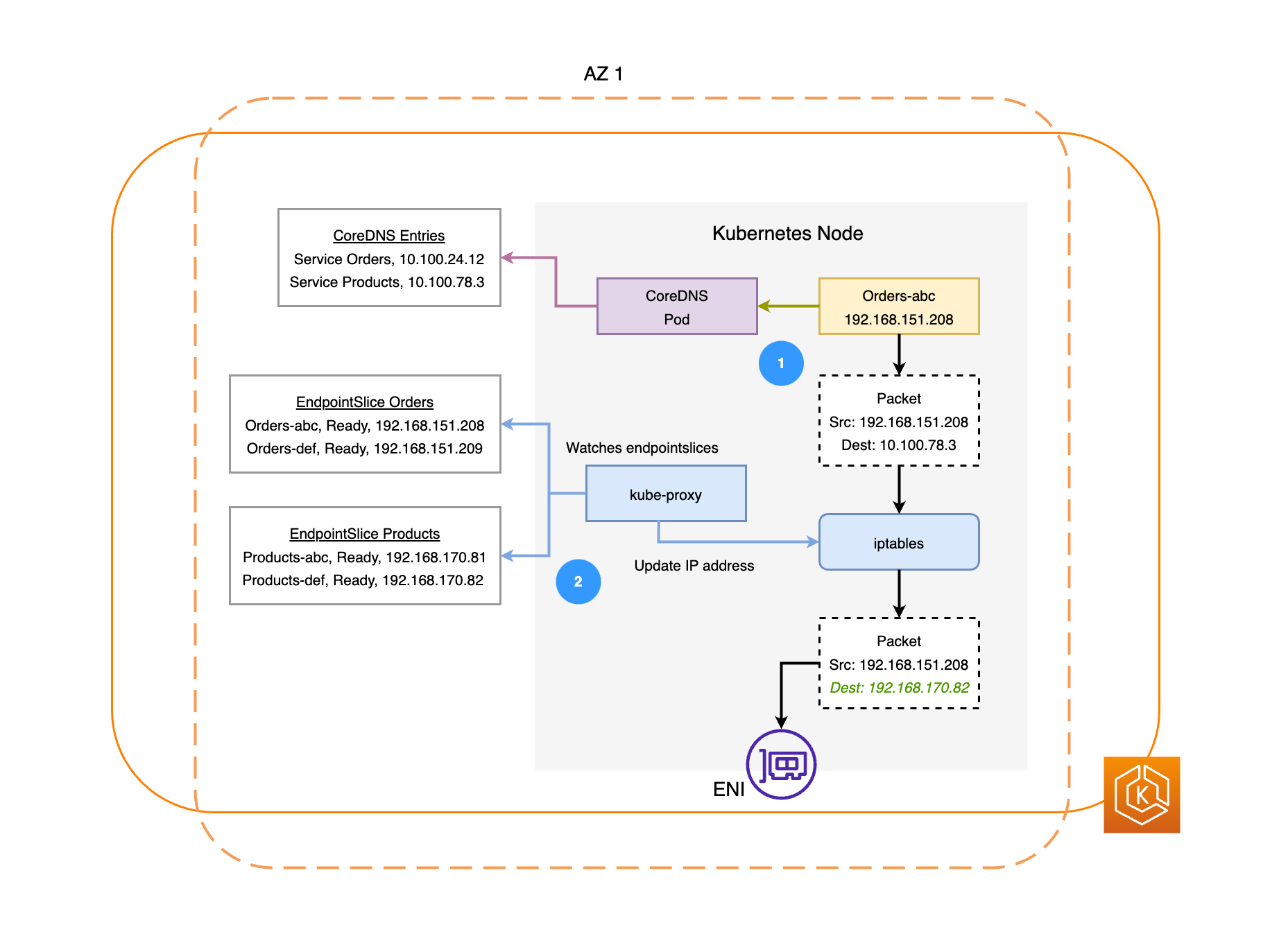
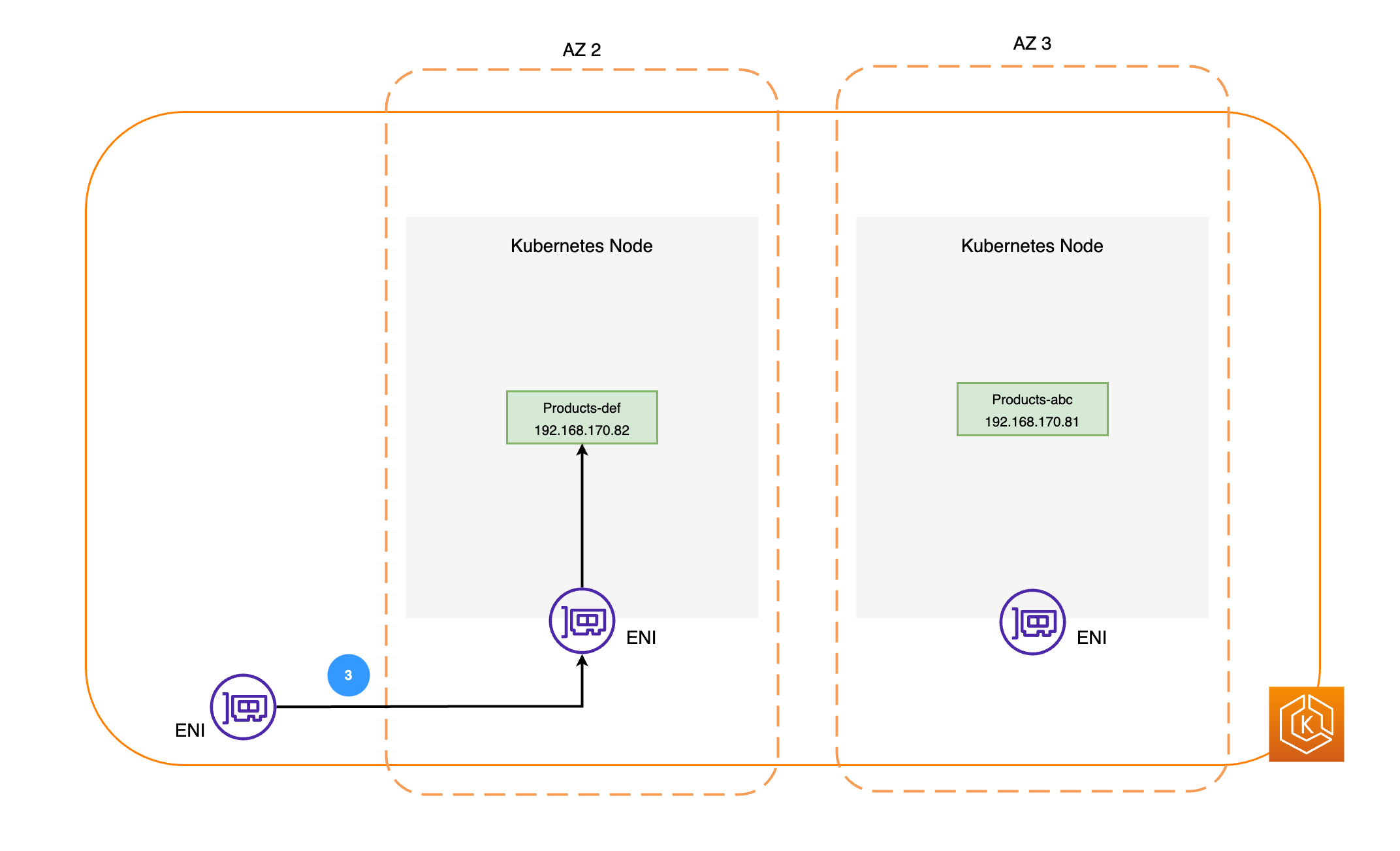
下图说明了两个示例工作负载,即“订单”和“产品”。此示例的目的是展示不同可用区中的工作负载和容器组(pod)是如何通信的。
-
要使“订单”与“产品”通信,它必须首先解析目标服务的 DNS 名称。“订单”将与 CoreDNS 通信以获取该服务的虚拟 IP 地址(集群 IP)。“订单”解析“产品”服务名称后,它会将流量发送到该目标 IP 地址。
-
kube-proxy 在集群中的每个节点上运行,并持续监视 EndpointSlices
的服务。创建服务时,EndpointSlice 控制器将在后台创建和管理 EndpointSlice。每个 EndpointSlice 都有一个端点列表或表格,其中包含容器组(pod)地址的子集以及它们在其中正在运行的节点。kube-proxy 在节点上为每个容器组(pod)端点设置 iptables路由规则。kube-proxy 还负责一种基本的负载均衡,也就是将发往服务集群 IP 地址的流量重定向为直接发送到容器组(pod)的 IP 地址。kube-proxy 通过重写传出连接上的目标 IP 地址来实现此目的。 -
然后,网络数据包通过相应节点上的 ENI 发送到可用区 2 中的“产品”容器组(pod)(如前面的图表所示)。
了解 Amazon EKS 中的 ARC 可用区转移
如果您的环境中存在可用区损坏,则可以为您的 EKS 集群环境启动可用区转移。或者,您可以允许 Amazon 使用可用区自动转移来为您管理流量转移。使用可用区自动转移,Amazon 可监控整体可用区运行状况,并通过自动将流量从集群环境中损坏的可用区转移出去来应对潜在的可用区损坏。
使用 ARC 启用 Amazon EKS 集群可用区转移后,您可以使用 ARC 控制台、Amazon CLI 或可用区转移和可用区自动转移 API,启动可用区转移或启用可用区自动转移。在 EKS 可用区转移期间,将自动执行以下操作:
-
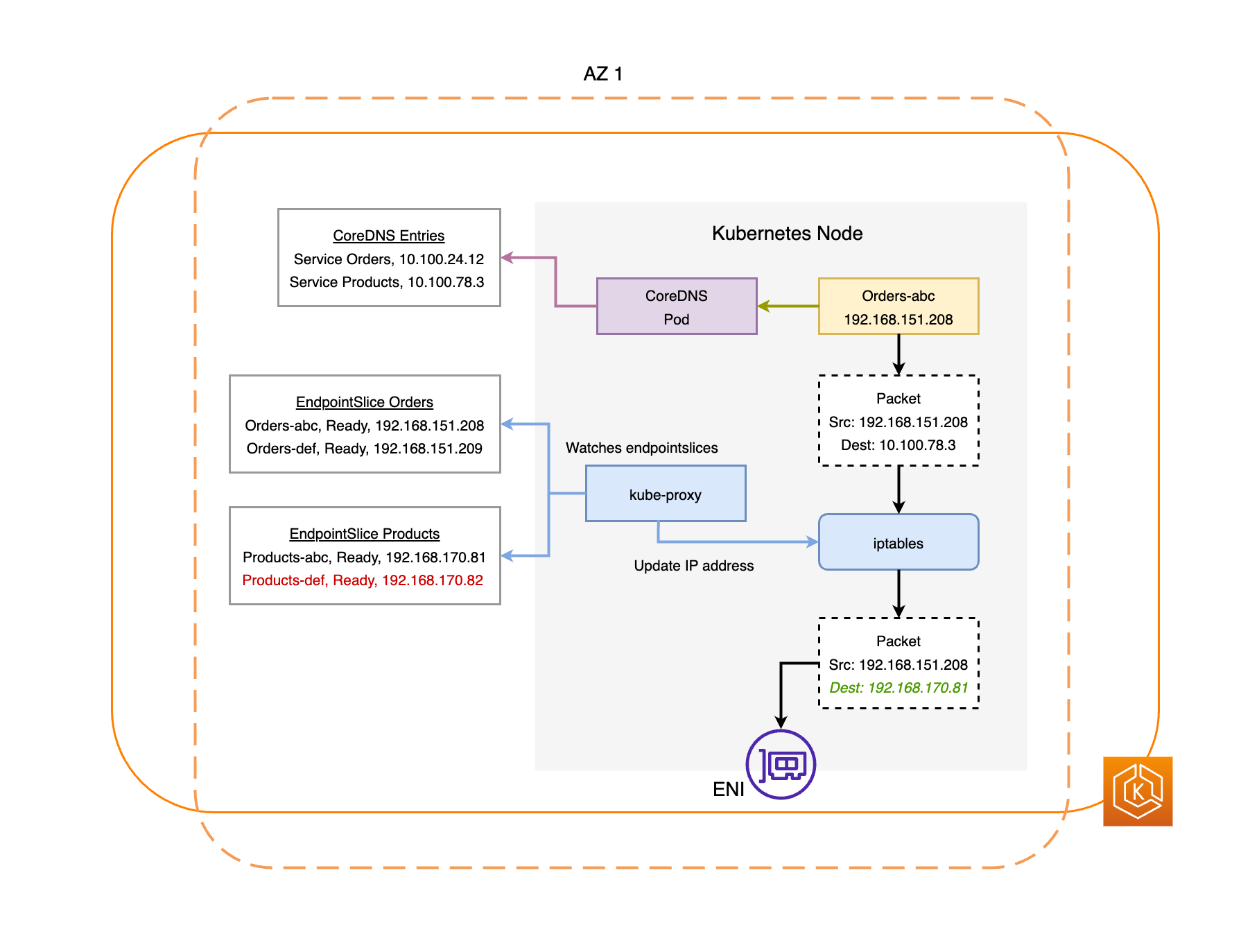
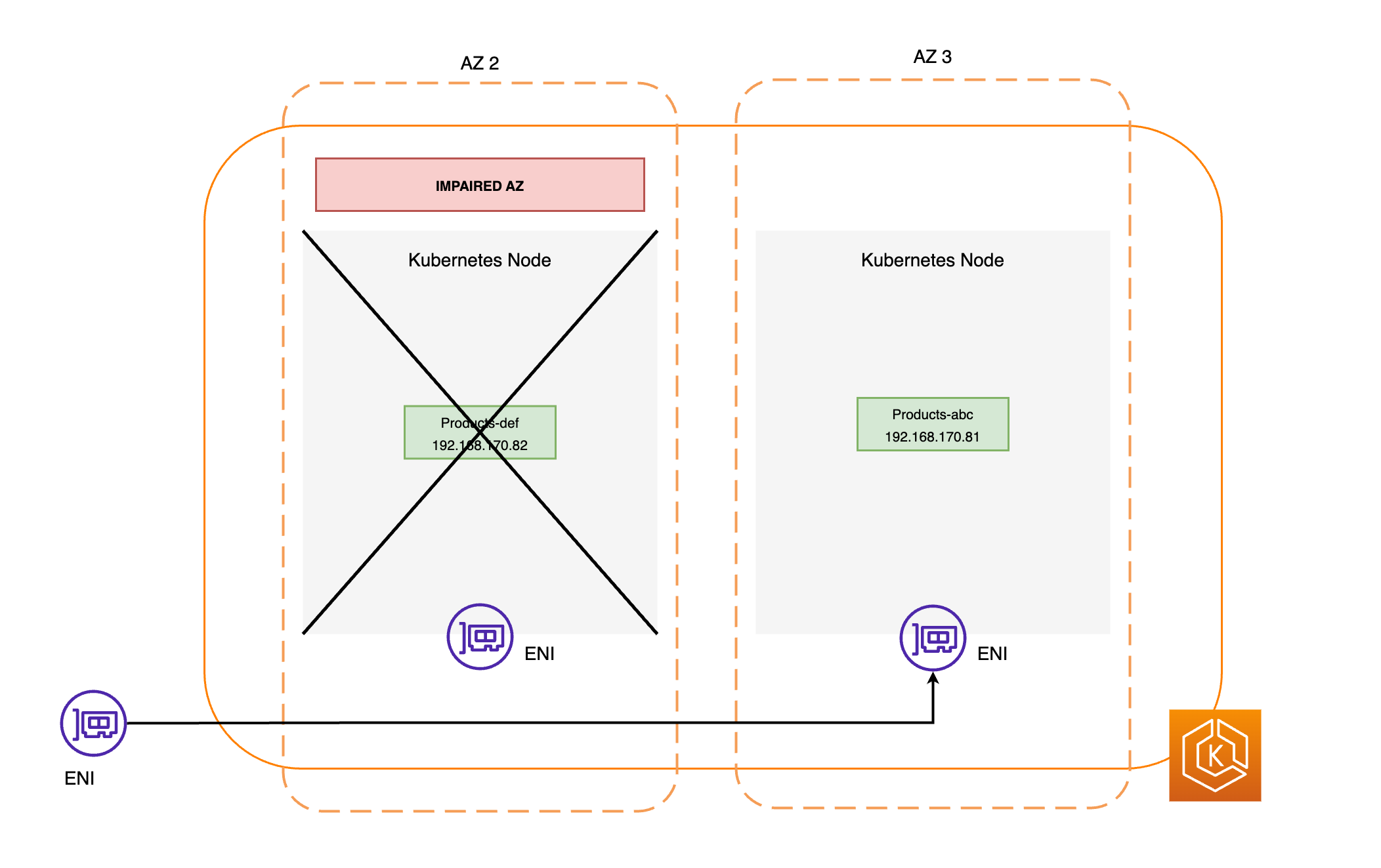
受影响可用区中的所有节点都被封锁。这将防止 Kubernetes 调度器将新容器组(pod)调度到运行状况不佳的可用区中的节点上。
-
如果您使用的是托管节点组,则可用区重新平衡将被暂停,并且您的自动扩缩组也将更新,以确保新的 EKS 数据面板节点仅在运行状况良好的可用区中启动。
-
运行状况不佳的可用区中的节点不会被终止,容器组(pod)也不会被逐出这些节点。这可确保当可用区转移到期或被取消时,您的流量可以安全地返回到可用区以获得完整容量。
-
EndpointSlice 控制器将在损坏的可用区中找到所有容器组(pod)端点,并将它们从相关的 EndpointSlices 中移除。这将确保只有运行状况良好的可用区中的容器组(pod)端点才会成为接收网络流量的目标。当可用区转移被取消或到期时,EndpointSlice 控制器将更新 EndpointSlices 以包括已恢复的可用区中的端点。
下图简要概述了 EKS 可用区转移如何确保集群环境中仅针对运行状况良好的容器组(pod)端点。
EKS 可用区转移要求
要在 EKS 中成功进行可用区转移,您必须事先设置集群环境,使其能够抵御可用区损坏。以下是有助于确保韧性的配置选项列表。
-
跨多个可用区配置集群的 Worker 节点
-
预调配足够的计算容量,以适应单个可用区的移除
-
在每个可用区预先扩展容器组(pod)(包括 CoreDNS)
-
将多个容器组(pod)副本分布在所有可用区中,帮助确保从单个可用区转出后,仍会给您留下足够的容量
-
将相互依赖或相关的容器组(pod)托管在同一可用区中
-
通过手动启动从可用区的可用区转移,测试集群环境是否能在没有可用区的情况下按预期运行。或者,您可以启用可用区自动转移并在自动转移练习运行时回复。要在 EKS 中进行可用区转移,手动测试或进行可用区转移并非强制要求,但强烈建议执行此操作。
跨多个可用区预调配您的 EKS Worker 节点
Amazon 区域有多个独立的地点,其物理数据中心称为可用区(AZ)。可用区在物理上相互隔离,以避免同时影响整个区域的冲击。在预调配 EKS 集群时,建议将 Worker 节点部署到一个区域中的多个可用区。这有助于使您的集群环境更能抵御单个可用区的损坏,并让您能够保持在其它可用区中运行的应用程序的高可用性(HA)。当您开始从受影响的可用区启动可用区转移时,EKS 环境的集群内网络将自动更新为仅使用运行状况良好的可用区,以帮助保持集群的高可用性。
确保为 EKS 环境设置多可用区将提高系统的整体可靠性。但是,多可用区环境会影响应用程序数据的传输和处理方式,这反过来又会影响您环境的网络费用。特别是,频繁的跨可用区出站流量(流量分布在可用区之间)可能会对您的网络相关成本产生重大影响。您可以应用不同的策略来控制 EKS 集群中容器组(pod)之间的跨可用区流量并降低相关成本。有关在运行高可用性 EKS 环境时如何优化网络成本的更多信息,请参阅这些最佳实践
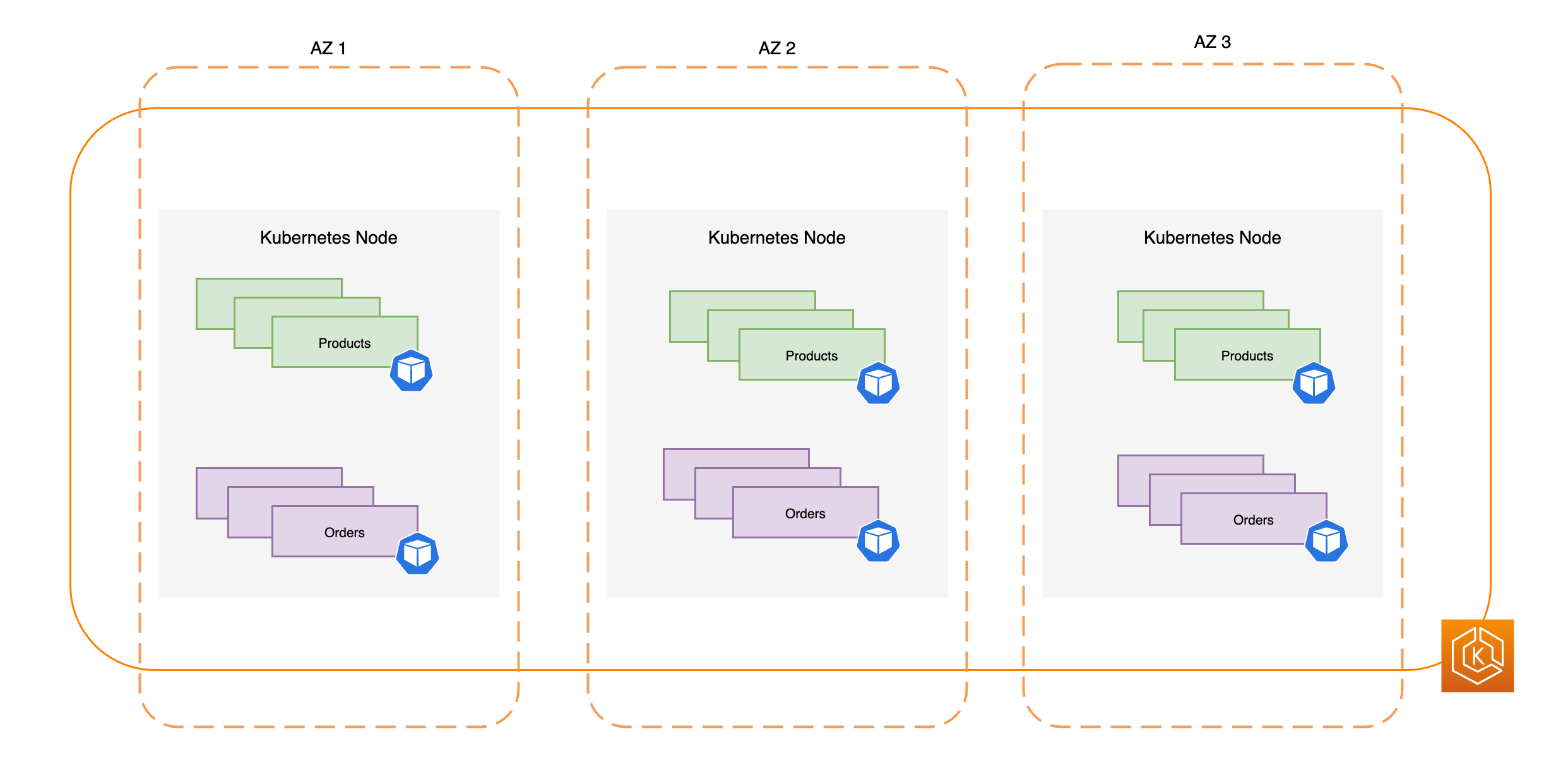
下图说明了具有三个运行状况良好的可用区的高可用性 EKS 环境。
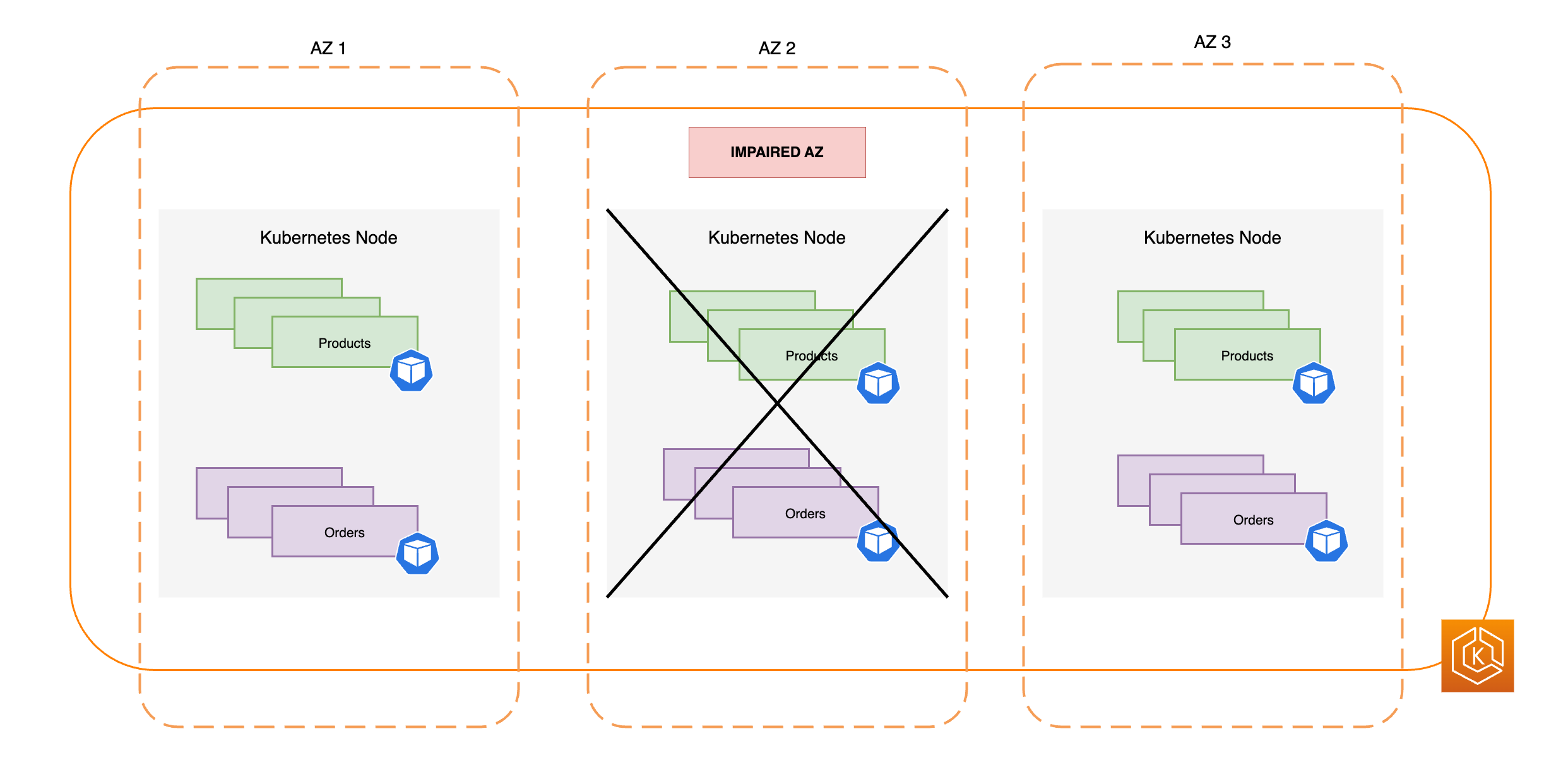
下图说明了具有三个可用区的 EKS 环境如何抵御可用区损坏,并且由于剩余两个可用区运行状况良好,因此仍保持高可用性。
预调配足够的计算容量,以适应单个可用区的移除
为了优化 EKS 数据面板中计算基础设施的资源利用率和成本,最佳做法是使计算容量与工作负载要求保持一致。但是,如果您的所有 Worker 节点都已满负荷,则在调度新的容器组(pod)之前,您只能依赖将新的 Worker 节点添加到 EKS 数据面板中。在运行关键工作负载时,通常最好使用冗余容量在线运行,以应对负载突然增加、节点运行状况问题等意外情况。如果您计划使用可用区转移,则要计划在出现损坏时移除整个可用区的容量。这意味着您必须调整冗余计算容量,使其足以处理负载,即使其中一个可用区处于离线状态也不例外。
扩展计算资源时,向 EKS 数据面板添加新节点的过程需要一些时间。这可能会对应用程序的实时性能和可用性产生影响,尤其是在出现可用区损坏的情况下。您的 EKS 环境应能够承受丢失一个可用区所带来的负载,而不会导致最终用户或客户体验降级。这意味着要最大限度地减少或消除需要新容器组(pod)的时间与实际调度到 Worker 节点上的时间之间的延迟。
此外,如果出现可用区损坏,您应旨在降低遇到计算容量限制的风险,这将阻止在运行状况良好的可用区中将新需要的节点添加到您的 EKS 数据面板中。
为降低这些潜在负面影响的风险,建议您在每个可用区的某些 Worker 节点中过度预调配计算容量。通过执行此操作,Kubernetes 调度器有预先存在的容量可用于放置新容器组(pod),当您在环境中丢失其中一个可用区时,这一点尤为重要。
跨可用区运行和分布多个容器组(pod)副本
Kubernetes 允许您通过运行单个应用程序的多个实例(容器组(pod)副本)来预先扩展工作负载。为一个应用程序运行多个容器组(pod)副本可以消除单点故障,并通过减少单个副本的资源紧张来提高其整体性能。但是,为了使应用程序具有高可用性和更好的容错能力,建议在不同的故障域(也称为拓扑域)中运行应用程序的多个副本并将它们分散到不同的故障域。这种情况下的故障域是可用区。通过使用拓扑分布约束
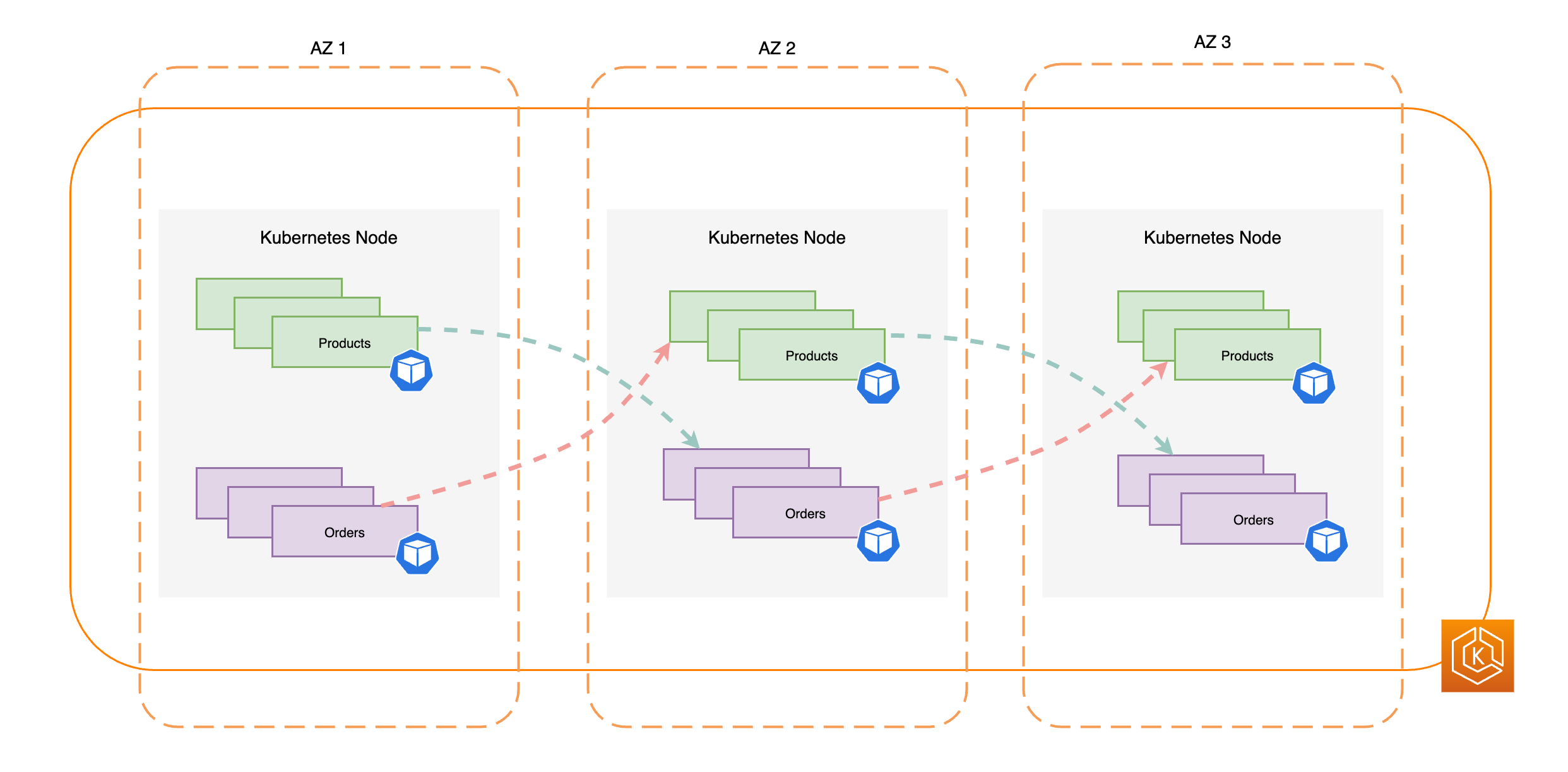
下图展示了当所有可用区都运行状况良好时,具有东-西流量流向的 EKS 环境。
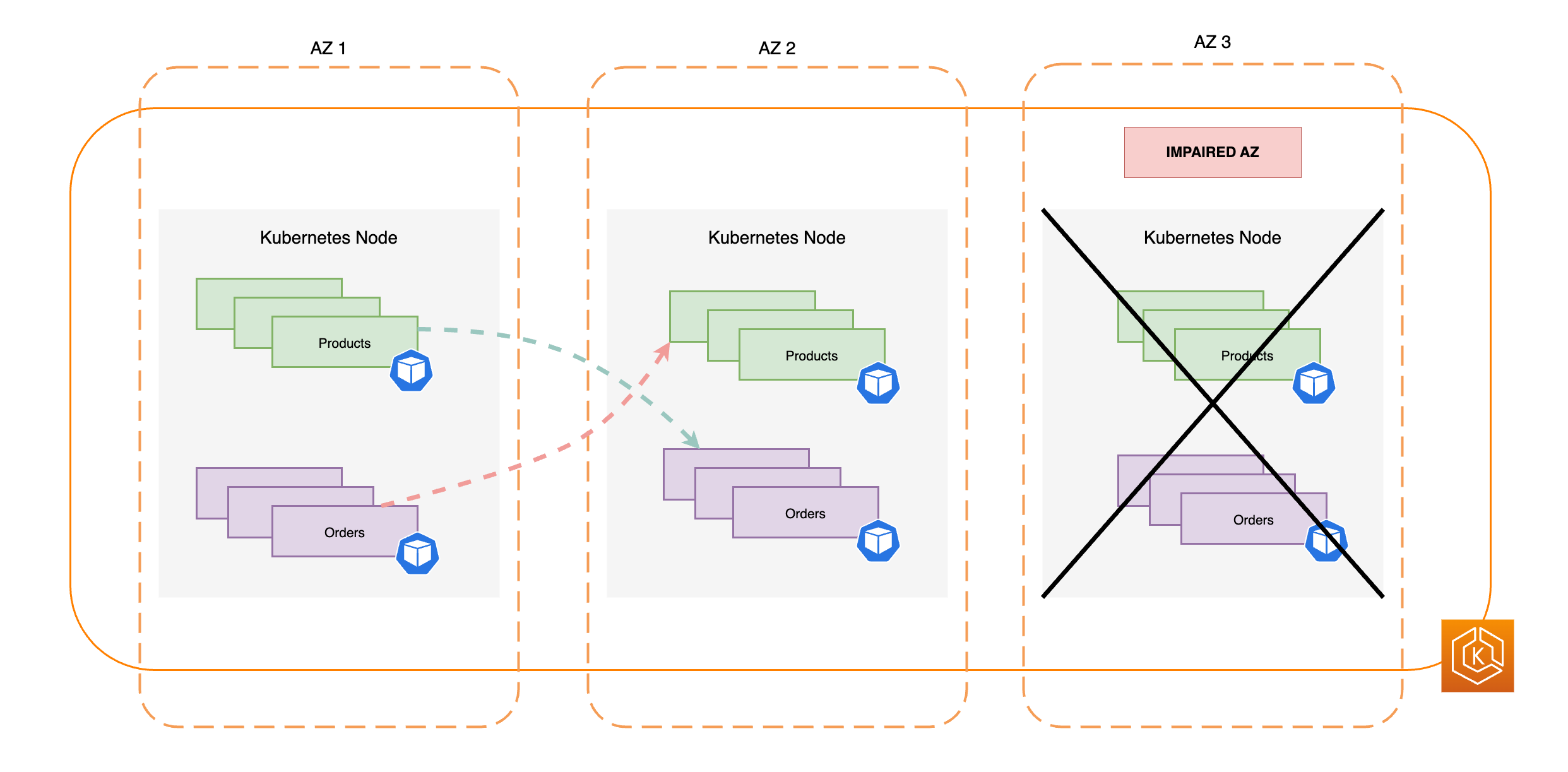
下图展示了具有东-西流量流向的 EKS 环境,其中单个可用区出现故障,且您已启动可用区转移。
以下代码片段是如何在 Kubernetes 中使用多个副本设置工作负载的示例。
apiVersion: apps/v1 kind: Deployment metadata: name: orders spec: replicas: 9 selector: matchLabels: app: orders template: metadata: labels: app: orders tier: backend spec: topologySpreadConstraints: - maxSkew: 1 topologyKey: "topology.kubernetes.io/zone" whenUnsatisfiable: ScheduleAnyway labelSelector: matchLabels: app: orders
最重要的是,您应该运行 DNS 服务器软件(CoreDNS/kube-dns)的多个副本,如果默认情况下尚未配置这些副本,则应用类似的拓扑分布约束。这有助于确保在出现单个可用区损坏时,您在运行状况良好的可用区中有足够的 DNS 容器组(pod),以便继续处理集群中其他通信容器组(pod)的服务发现请求。CoreDNS EKS 附加组件具有 CoreDNS 容器组(pod)默认设置,可确保如果多个可用区中有节点可用,则 CoreDNS 容器组(pod)将分布在集群的可用区域中。您也可以根据需要将这些默认设置替换为自己的自定义配置。
使用 Helm 安装 CoreDNSreplicaCount,以确保每个可用区中有足够的副本。此外,为确保这些副本分布在集群环境中的不同可用区中,请确保更新同一个 values.yaml 文件中的 topologySpreadConstraints 属性。以下代码片段说明了如何配置 CoreDNS 来执行此操作。
CoreDNS Helm values.yaml
replicaCount: 6 topologySpreadConstraints: - maxSkew: 1 topologyKey: topology.kubernetes.io/zone whenUnsatisfiable: ScheduleAnyway labelSelector: matchLabels: k8s-app: kube-dns
如果出现可用区损坏,您可以使用 CoreDNS 的自动缩放系统来承受 CoreDNS 容器组(pod)上增加的负载。您需要的 DNS 实例数取决于集群中运行的工作负载数量。CoreDNS 受 CPU 约束,允许它使用 Horizontal Pod Autoscaler(HPA)
apiVersion: autoscaling/v1 kind: HorizontalPodAutoscaler metadata: name: coredns namespace: default spec: maxReplicas: 20 minReplicas: 2 scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: coredns targetCPUUtilizationPercentage: 50
另外,EKS 可以在 CoreDNS 的 EKS 附加组件版本中管理 CoreDNS 部署的自动扩缩。此 CoreDNS 自动扩缩器会持续监控集群状态,包括节点数量和 CPU 核心数量。控制器会根据这些信息,动态调整 EKS 集群中 CoreDNS 部署的副本数量。
要在 CoreDNS EKS 附加组件中启用自动扩缩配置,请使用以下配置设置:
{ "autoScaling": { "enabled": true } }
您也可以使用 NodeLocal DNS
将相互依赖的容器组(pod)托管在同一个可用区中
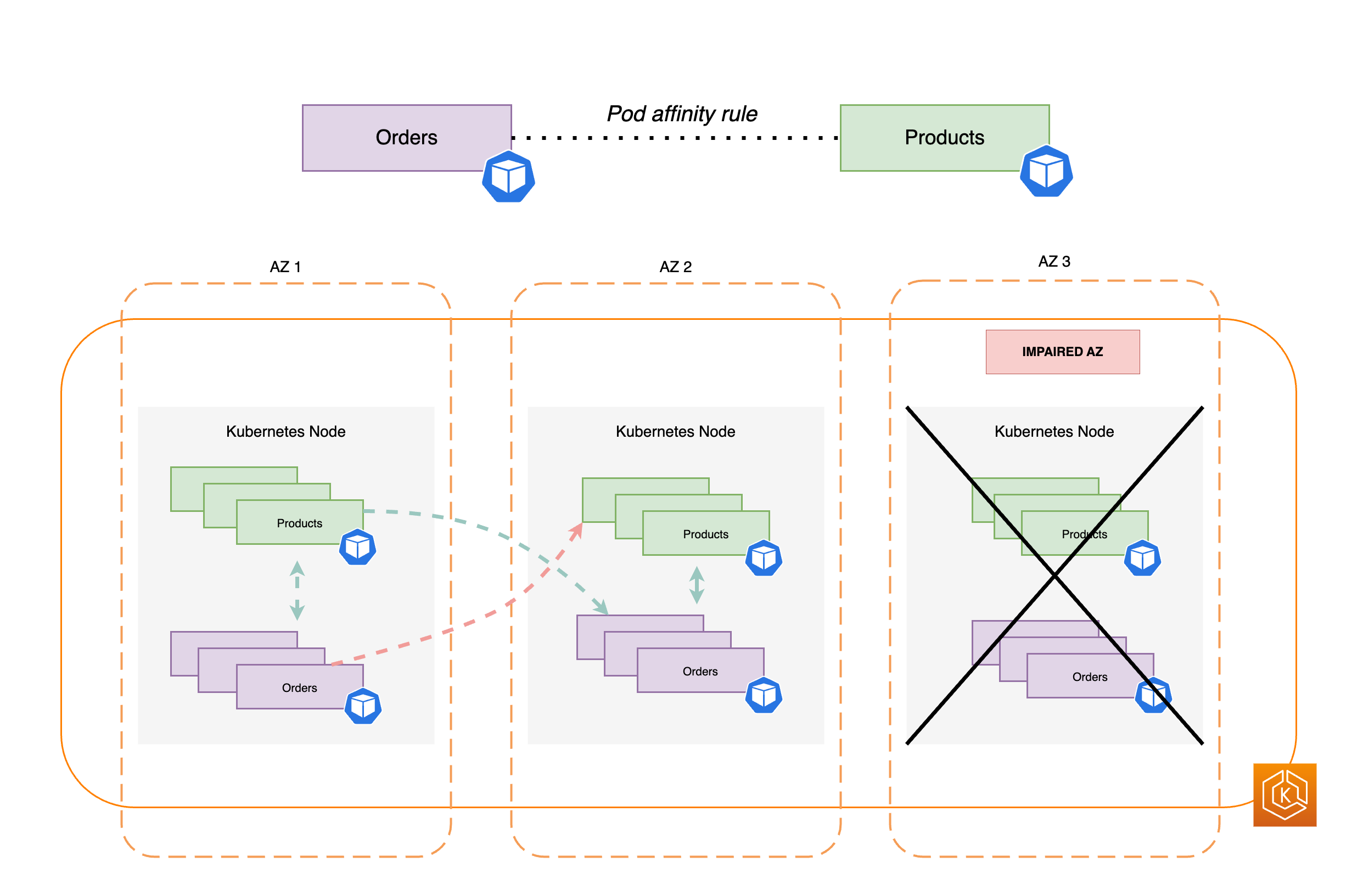
通常,应用程序有不同的工作负载,这些工作负载需要相互通信才能成功完成端到端流程。如果这些不同的应用程序分布在不同的可用区中,但托管在同一个可用区中,则单个可用区损坏可能会影响端到端流程。例如,如果应用程序 A 在可用区 1 和可用区 2 中有多个副本,但应用程序 B 的所有副本都在可用区 3 中,则可用区 3 丢失将影响两个工作负载(应用程序 A 和应用程序 B)之间的端到端流程。如果您将拓扑分布约束与容器组(pod)亲和性相结合,则可以通过将容器组(pod)分布到所有可用区来增强应用程序的韧性。此外,这还配置了某些容器组(pod)之间的关系,确保它们已托管。
借助容器组(pod)亲和性规则
apiVersion: apps/v1 kind: Deployment metadata: name: products namespace: ecommerce labels: app.kubernetes.io/version: "0.1.6" spec: serviceAccountName: graphql-service-account affinity: podAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: app operator: In values: - orders topologyKey: "kubernetes.io/hostname"
下图展示了使用容器组(pod)亲和性规则托管在同一节点上的多个容器组(pod)。
测试您的集群环境能否应对可用区的丢失
完成之前章节所述的要求后,下一个步骤是测试您是否有足够的计算和工作负载容量来应对可用区的丢失。您可以通过在 EKS 中手动启动可用区转移来实现此目的。或者,您可以启用可用区自动转移并配置练习运行,这种运行还可测试在集群环境中少一个可用区的情况下,您的应用程序是否按预期运行。
常见问题
为什么应该使用此功能?
通过在 EKS 集群中使用 ARC 可用区转移或可用区自动转移,您可以自动执行将集群内网络流量从损坏的可用区转移出去的快速恢复过程,从而更好地维护 Kubernetes 应用程序的可用性。使用 ARC,您可以避免漫长而复杂的步骤,这些步骤会导致在可用区损坏事件期间延长恢复期。
此功能如何与其它 Amazon 服务结合使用?
EKS 与 ARC 集成,后者为您提供了在 Amazon 中完成恢复操作所需的主要接口。为了确保集群内流量从损坏的可用区适当路由,EKS 对在 Kubernetes 数据面板中运行的容器组(pod)的网络端点列表进行了修改。如果您使用弹性负载均衡将外部流量路由到集群,则可以向 ARC 注册您的负载均衡器,并对其启动可用区转移,以防止流量流入降级的可用区。可用区转移还适用于由 EKS 托管节点组创建的 Amazon EC2 Auto Scaling 组。为了防止损坏的可用区被用于新的 Kubernetes 容器组(pod)或节点启动,EKS 会将损坏的可用区从自动扩缩组中移除。
此功能与默认的 Kubernetes 保护有何不同?
此功能与多个 Kubernetes 内置保护结合使用,可帮助客户应用程序保持韧性。您可以配置容器组(pod)就绪性和存活性探测器,以决定容器组(pod)何时应接入流量。当这些探测器失败时,Kubernetes 会移除将这些容器组(pod)作为服务的目标,流量将不再发送到这些容器组(pod)。虽然这很有用,但对于客户来说,配置这些运行状况检查以确保在可用区降级时它们会失败并非易事。ARC 可用区转移功能提供了额外的安全网,可以帮助您在 Kubernetes 的原生保护不足时完全隔离已降级的可用区。可用区转移还为用户提供了一种测试架构的运行就绪性和韧性的简便方法。
Amazon 可以代表我启动可用区转移吗?
可以。如果您想以一种全自动的方式使用 ARC 可用区转移,则可以启用 ARC 可用区自动转移。借助可用区自动转移,您可以依靠 Amazon 来监控 EKS 集群的可用区运行状况,并在检测到可用区损坏时自动启动可用区转移。
如果我使用此功能,但我的 Worker 节点和工作负载未预先扩展,会发生什么情况?
如果您没有预先扩展,并且依赖于在可用区转移期间预调配其他节点或容器组(pod),则可能会面临恢复延迟的风险。向 Kubernetes 数据面板添加新节点的过程将需要一些时间,这可能会对应用程序的实时性能和可用性产生影响,尤其是在出现可用区损坏的情况下。此外,如果出现可用区损坏,您可能会遇到潜在的计算容量约束,这会阻止将新需要的节点添加到运行状况良好的可用区。
如果您的工作负载未预先扩展并分布在集群中的所有可用区,则可用区损坏可能会影响仅在受影响可用区的 Worker 节点上运行的应用程序的可用性。为了降低应用程序可用性完全中断的风险,如果工作负载的所有端点都位于运行状况不佳的可用区中,EKS 提供了故障安全功能,可以将流量发送到损坏的可用区中的容器组(pod)端点。但是,强烈建议您预先扩展应用程序并将其分散到所有可用区,以便在出现可用区问题时保持可用性。
如果我运行的是有状态的应用程序会怎样?
如果您运行的是有状态的应用程序,则须根据使用案例和架构评测其容错能力。如果您采用主动/备用架构或模式,则可能存在主动服务器位于损坏的可用区中的情况。在应用程序级别,如果未激活备用副本,则您的应用程序可能会遇到问题。在运行状况良好的可用区中启动新的 Kubernetes 容器组(pod)时,您也可能会遇到问题,因为它们将无法附加到损坏的可用区的持久卷。
此功能适用于 Karpenter 吗?
Karpenter 支持适用于搭载 Karpenter 版本 1.12 或更新版本
此功能是否可以与 EKS Fargate 结合使用?
此功能不能与 EKS Fargate 结合使用。默认情况下,当 EKS Fargate 识别出可用区运行状况值事件时,容器组(pod)将更愿意在其它可用区中运行。
EKS 托管的 Kubernetes 控制面板是否会受到影响?
不会。默认情况下,Amazon EKS 跨多个可用区运行和扩展 Kubernetes 控制面板以确保高可用性。ARC 可用区转移和可用区自动转移只能在 Kubernetes 数据面板上起作用。
这项新功能有什么相关费用吗?
您可以在 EKS 集群中使用 ARC 可用区转移和可用区自动转移,无需额外付费。但是,您将继续为预调配实例付费,因此强烈建议您在使用此功能之前预先扩展 Kubernetes 数据面板。您应该考虑在成本和应用程序可用性之间取得平衡。