Auto Scaling Valkey and Redis OSS clusters
Prerequisites
ElastiCache Auto Scaling is limited to the following:
-
Valkey or Redis OSS (cluster mode enabled) clusters running Valkey 7.2 onwards, or running Redis OSS 6.0 onwards
-
Data tiering (cluster mode enabled) clusters running Valkey 7.2 onwards, or running Redis OSS 7.0.7 onwards
-
Instance sizes - Large, XLarge, 2XLarge
-
Instance type families - R7g, R6g, R6gd, R5, M7g, M6g, M5, C7gn
-
Auto Scaling in ElastiCache is not supported for clusters running in Global datastores, Outposts or Local Zones.
Managing Capacity Automatically with ElastiCache Auto Scaling with Valkey or Redis OSS
ElastiCache auto scaling with Valkey or Redis OSS is the ability to increase or decrease the desired shards or replicas in your ElastiCache service automatically. ElastiCache leverages the Application Auto Scaling service to provide this functionality. For more information, see Application Auto Scaling. To use automatic scaling, you define and apply a scaling policy that uses CloudWatch metrics and target values that you assign. ElastiCache auto scaling uses the policy to increase or decrease the number of instances in response to actual workloads.
You can use the Amazon Web Services Management Console to apply a scaling policy based on a predefined metric. A
predefined metric is defined in an enumeration so that you can specify
it by name in code or use it in the Amazon Web Services Management Console. Custom metrics are not available for
selection using the Amazon Web Services Management Console. Alternatively, you can use either the Amazon CLI or the
Application Auto Scaling API to apply a scaling policy based on a predefined or custom
metric.
ElastiCache for Valkey and Redis OSS supports scaling for the following dimensions:
-
Shards – Automatically add/remove shards in the cluster similar to manual online resharding. In this case, ElastiCache auto scaling triggers scaling on your behalf.
-
Replicas – Automatically add/remove replicas in the cluster similar to manual Increase/Decrease replica operations. ElastiCache auto scaling for Valkey and Redis OSS adds/removes replicas uniformly across all shards in the cluster.
ElastiCache for Valkey and Redis OSS supports the following types of automatic scaling policies:
-
Target tracking scaling policies – Increase or decrease the number of shards/replicas that your service runs based on a target value for a specific metric. This is similar to the way that your thermostat maintains the temperature of your home. You select a temperature and the thermostat does the rest.
-
Scheduled scaling for your application. – ElastiCache for Valkey and Redis OSS auto scaling can increase or decrease the number of shards/replicas that your service runs based on the date and time.
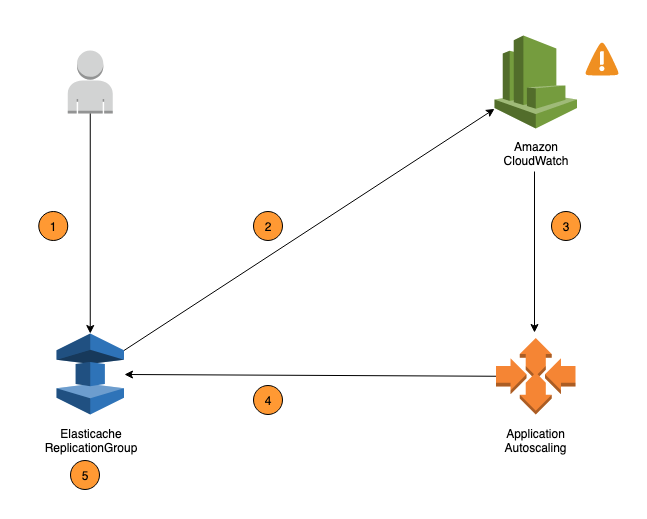
The following steps summarize the ElastiCache for Valkey and Redis OSS auto scaling process as shown in the previous diagram:
-
You create an ElastiCache auto scaling policy for your Replication Group.
-
ElastiCache auto scaling creates a pair of CloudWatch alarms on your behalf. Each pair represents your upper and lower boundaries for metrics. These CloudWatch alarms are triggered when the cluster's actual utilization deviates from your target utilization for a sustained period of time. You can view the alarms in the console.
-
If the configured metric value exceeds your target utilization (or falls below the target) for a specific length of time, CloudWatch triggers an alarm that invokes auto scaling to evaluate your scaling policy.
-
ElastiCache auto scaling issues a Modify request to adjust your cluster capacity.
-
ElastiCache processes the Modify request, dynamically increasing (or decreasing) the cluster Shards/Replicas capacity so that it approaches your target utilization.
To understand how ElastiCache Auto Scaling works, suppose that you have a cluster named
UsersCluster. By monitoring the CloudWatch metrics for
UsersCluster, you determine the Max shards that the cluster requires
when traffic is at its peak and Min Shards when traffic is at its lowest point. You also
decide a target value for CPU utilization for the UsersCluster cluster.
ElastiCache auto scaling uses its target tracking algorithm to ensure that the provisioned
shards of UsersCluster is adjusted as required so that utilization remains
at or near to the target value.
Note
Scaling may take noticeable time and will require extra cluster resources for shards to rebalance. ElastiCache Auto Scaling modifies resource settings only when the actual workload stays elevated (or depressed) for a sustained period of several minutes. The auto scaling target-tracking algorithm seeks to keep the target utilization at or near your chosen value over the long term.
IAM Permissions Required for Auto Scaling
ElastiCache for Valkey and Redis OSS Auto Scaling is made possible by a combination of the ElastiCache, CloudWatch, and
Application Auto Scaling APIs. Clusters are created and updated with ElastiCache, alarms are
created with CloudWatch, and scaling policies are created with Application Auto Scaling. In
addition to the standard IAM permissions for creating and updating clusters, the IAM
user that accesses ElastiCache Auto Scaling settings must have the appropriate permissions
for the services that support dynamic scaling. In this most recent policy we have added support for Memcached vertical scaling, with the action elasticache:ModifyCacheCluster. IAM users must have permissions to use
the actions shown in the following example policy:
Service-linked role
The ElastiCache for Valkey and Redis OSS auto scaling service also needs permission to describe your clusters and
CloudWatch alarms, and permissions to modify your ElastiCache target capacity on your behalf. If
you enable Auto Scaling for your cluster, it creates a service-linked role named
AWSServiceRoleForApplicationAutoScaling_ElastiCacheRG. This
service-linked role grants ElastiCache auto scaling permission to describe the alarms for
your policies, to monitor the current capacity of the fleet, and to modify the capacity
of the fleet. The service-linked role is the default role for ElastiCache auto scaling. For
more information, see Service-linked roles for ElastiCache for Redis OSS auto scaling in the Application Auto
Scaling User Guide.
Auto Scaling Best Practices
Before registering to Auto Scaling, we recommend the following:
-
Use just one tracking metric – Identify if your cluster has CPU or data intensive workloads and use a corresponding predefined metric to define Scaling Policy.
-
Engine CPU:
ElastiCachePrimaryEngineCPUUtilization(shard dimension) orElastiCacheReplicaEngineCPUUtilization(replica dimension) -
Database usage:
ElastiCacheDatabaseCapacityUsageCountedForEvictPercentageThis scaling policy works best with maxmemory-policy set to noeviction on the cluster.
We recommend you avoid multiple policies per dimension on the cluster. ElastiCache for Valkey and Redis OSS Auto scaling will scale out the scalable target if any target tracking policies are ready for scale out, but will scale in only if all target tracking policies (with the scale-in portion enabled) are ready to scale in. If multiple policies instruct the scalable target to scale out or in at the same time, it scales based on the policy that provides the largest capacity for both scale in and scale out.
-
-
Customized Metrics for Target Tracking – Be cautious when using customized metrics for Target Tracking as Auto scaling is best suited to scale-out/in proportional to changes in metrics chosen for the policy. If those metrics don't change proportionally to the scaling actions used for policy creation, it might lead to continuous scale-out or scale-in actions which might affect availability or cost.
For data-tiering clusters (r6gd family instance types), avoid using memory-based metrics for scaling.
-
Scheduled Scaling – If you identify that your workload is deterministic (reaches high/low at a specific time), we recommend using Scheduled Scaling and configure your target capacity according to the need. Target Tracking is best suitable for non-deterministic workloads and for the cluster to operate at the required target metric by scaling out when you need more resources and scaling in when you need less.
-
Disable Scale-In – Auto scaling on Target Tracking is best suited for clusters with gradual increase/decrease of workloads as spikes/dip in metrics can trigger consecutive scale-out/in oscillations. In order to avoid such oscillations, you can start with scale-in disabled and later you can always manually scale-in to your need.
-
Test your application – We recommend you test your application with your estimated Min/Max workloads to determine absolute Min,Max shards/replicas required for the cluster while creating Scaling policies to avoid availability issues. Auto scaling can scale out to the Max and scale-in to the Min threshold configured for the target.
-
Defining Target Value – You can analyze corresponding CloudWatch metrics for cluster utilization over a four-week period to determine the target value threshold. If you are still not sure of of what value to choose, we recommend starting with a minimum supported predefined metric value.
-
AutoScaling on Target Tracking is best suited for clusters with uniform distribution of workloads across shards/replicas dimension. Having non-uniform distribution can lead to:
-
Scaling when not required due to workload spike/dip on a few hot shards/replicas.
-
Not scaling when required due to overall avg close to target even though having hot shards/replicas.
-
Note
When scaling out your cluster, ElastiCache will automatically replicate the
Functions loaded in one of the existing nodes (selected at random) to the new
node(s). If your cluster has Valkey or Redis OSS 7.0 or above and your application uses Functions
After registering to AutoScaling, note the following:
-
There are limitations on Auto scaling Supported Configurations, so we recommend you not change configuration of a replication group that is registered for Auto scaling. The following are examples:
-
Manually modifying instance type to unsupported types.
-
Associating the replication group to a Global datastore.
-
Changing
ReservedMemoryPercentparameter. -
Manually increasing/decreasing shards/replicas beyond the Min/Max capacity configured during policy creation.
-