Core components of Amazon DynamoDB
In DynamoDB, tables, items, and attributes are the core components that you work with. A table is a collection of items, and each item is a collection of attributes. DynamoDB uses primary keys to uniquely identify each item in a table. You can use DynamoDB Streams to capture data modification events in DynamoDB tables.
There are limits in DynamoDB. For more information, see Quotas in Amazon DynamoDB.
The following video will give you an introductory look at tables, items, and attributes.
Tables, items, and attributes
The following are the basic DynamoDB components:
-
Tables – Similar to other database systems, DynamoDB stores data in tables. A table is a collection of data. For example, see the example table called People that you could use to store personal contact information about friends, family, or anyone else of interest. You could also have a Cars table to store information about vehicles that people drive.
-
Items – Each table contains zero or more items. An item is a group of attributes that is uniquely identifiable among all of the other items. In a People table, each item represents a person. For a Cars table, each item represents one vehicle. Items in DynamoDB are similar in many ways to rows, records, or tuples in other database systems. In DynamoDB, there is no limit to the number of items you can store in a table.
-
Attributes – Each item is composed of one or more attributes. An attribute is a fundamental data element, something that does not need to be broken down any further. For example, an item in a People table contains attributes called PersonID, LastName, FirstName, and so on. For a Department table, an item might have attributes such as DepartmentID, Name, Manager, and so on. Attributes in DynamoDB are similar in many ways to fields or columns in other database systems.
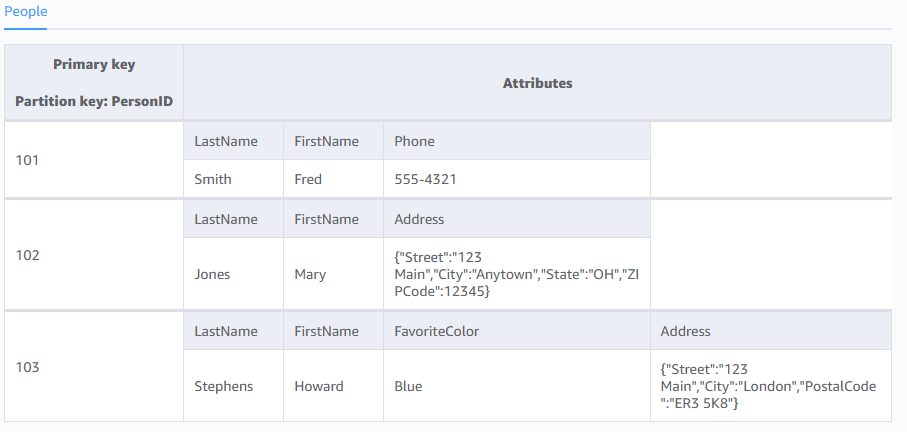
The following diagram shows a table named People with some example items and attributes.
People
{
"PersonID": 101,
"LastName": "Smith",
"FirstName": "Fred",
"Phone": "555-4321"
}
{
"PersonID": 102,
"LastName": "Jones",
"FirstName": "Mary",
"Address": {
"Street": "123 Main",
"City": "Anytown",
"State": "OH",
"ZIPCode": 12345
}
}
{
"PersonID": 103,
"LastName": "Stephens",
"FirstName": "Howard",
"Address": {
"Street": "123 Main",
"City": "London",
"PostalCode": "ER3 5K8"
},
"FavoriteColor": "Blue"
}Note the following about the People table:
-
Each item in the table has a unique identifier, or primary key, that distinguishes the item from all of the others in the table. In the People table, the primary key consists of one attribute (PersonID).
-
Other than the primary key, the People table is schemaless, which means that neither the attributes nor their data types need to be defined beforehand. Each item can have its own distinct attributes.
-
Most of the attributes are scalar, which means that they can have only one value. Strings and numbers are common examples of scalars.
-
Some of the items have a nested attribute (Address). DynamoDB supports nested attributes up to 32 levels deep.
The following is another example table named Music that you could use to keep track of your music collection.
Music
{
"Artist": "No One You Know",
"SongTitle": "My Dog Spot",
"AlbumTitle": "Hey Now",
"Price": 1.98,
"Genre": "Country",
"CriticRating": 8.4
}
{
"Artist": "No One You Know",
"SongTitle": "Somewhere Down The Road",
"AlbumTitle": "Somewhat Famous",
"Genre": "Country",
"CriticRating": 8.4,
"Year": 1984
}
{
"Artist": "The Acme Band",
"SongTitle": "Still in Love",
"AlbumTitle": "The Buck Starts Here",
"Price": 2.47,
"Genre": "Rock",
"PromotionInfo": {
"RadioStationsPlaying": [
"KHCR",
"KQBX",
"WTNR",
"WJJH"
],
"TourDates": {
"Seattle": "20150622",
"Cleveland": "20150630"
},
"Rotation": "Heavy"
}
}
{
"Artist": "The Acme Band",
"SongTitle": "Look Out, World",
"AlbumTitle": "The Buck Starts Here",
"Price": 0.99,
"Genre": "Rock"
} Note the following about the Music table:
-
The primary key for Music consists of two attributes (Artist and SongTitle). Each item in the table must have these two attributes. The combination of Artist and SongTitle distinguishes each item in the table from all of the others.
-
Other than the primary key, the Music table is schemaless, which means that neither the attributes nor their data types need to be defined beforehand. Each item can have its own distinct attributes.
-
One of the items has a nested attribute (PromotionInfo), which contains other nested attributes. DynamoDB supports nested attributes up to 32 levels deep.
For more information, see Working with tables and data in DynamoDB.
Primary key
When you create a table, in addition to the table name, you must specify the primary key of the table. The primary key uniquely identifies each item in the table, so that no two items can have the same key.
DynamoDB supports two different kinds of primary keys:
-
Partition key – A simple primary key, composed of one attribute known as the partition key.
DynamoDB uses the partition key's value as input to an internal hash function. The output from the hash function determines the partition (physical storage internal to DynamoDB) in which the item will be stored.
In a table that has only a partition key, no two items can have the same partition key value.
The People table described in Tables, items, and attributes is an example of a table with a simple primary key (PersonID). You can access any item in the People table directly by providing the PersonId value for that item.
-
Partition key and sort key – Referred to as a composite primary key, this type of key is composed of two attributes. The first attribute is the partition key, and the second attribute is the sort key.
DynamoDB uses the partition key value as input to an internal hash function. The output from the hash function determines the partition (physical storage internal to DynamoDB) in which the item will be stored. All items with the same partition key value are stored together, in sorted order by sort key value.
In a table that has a partition key and a sort key, it's possible for multiple items to have the same partition key value. However, those items must have different sort key values.
The Music table described in Tables, items, and attributes is an example of a table with a composite primary key (Artist and SongTitle). You can access any item in the Music table directly, if you provide the Artist and SongTitle values for that item.
A composite primary key gives you additional flexibility when querying data. For example, if you provide only the value for Artist, DynamoDB retrieves all of the songs by that artist. To retrieve only a subset of songs by a particular artist, you can provide a value for Artist along with a range of values for SongTitle.
Note
The partition key of an item is also known as its hash attribute. The term hash attribute derives from the use of an internal hash function in DynamoDB that evenly distributes data items across partitions, based on their partition key values.
The sort key of an item is also known as its range attribute. The term range attribute derives from the way DynamoDB stores items with the same partition key physically close together, in sorted order by the sort key value.
Each primary key attribute must be a scalar (meaning that it can hold only a single value). The only data types allowed for primary key attributes are string, number, or binary. There are no such restrictions for other, non-key attributes.
Secondary indexes
You can create one or more secondary indexes on a table. A secondary index lets you query the data in the table using an alternate key, in addition to queries against the primary key. DynamoDB doesn't require that you use indexes, but they give your applications more flexibility when querying your data. After you create a secondary index on a table, you can read data from the index in much the same way as you do from the table.
DynamoDB supports two kinds of indexes:
-
Global secondary index – An index with a partition key and sort key that can be different from those on the table. The primary key values in global secondary indexes don't need to be unique.
-
Local secondary index – An index that has the same partition key as the table, but a different sort key.
In DynamoDB, global secondary indexes (GSIs) are indexes that span the entire table, allowing you to query across all partition keys. Local secondary indexes (LSIs) are indexes that have the same partition key as the base table but a different sort key.
Each table in DynamoDB has a quota of 20 global secondary indexes (default quota) and 5 local secondary indexes.
In the example Music table shown previously, you can query data items by Artist (partition key) or by Artist and SongTitle (partition key and sort key). What if you also wanted to query the data by Genre and AlbumTitle? To do this, you could create an index on Genre and AlbumTitle, and then query the index in much the same way as you'd query the Music table.
The following diagram shows the example Music table, with a new index called GenreAlbumTitle. In the index, Genre is the partition key and AlbumTitle is the sort key.
| Music Table | GenreAlbumTitle |
|---|---|
|
|
|
|
|
|
|
|
Note the following about the GenreAlbumTitle index:
-
Every index belongs to a table, which is called the base table for the index. In the preceding example, Music is the base table for the GenreAlbumTitle index.
-
DynamoDB maintains indexes automatically. When you add, update, or delete an item in the base table, DynamoDB adds, updates, or deletes the corresponding item in any indexes that belong to that table.
-
When you create an index, you specify which attributes will be copied, or projected, from the base table to the index. At a minimum, DynamoDB projects the key attributes from the base table into the index. This is the case with
GenreAlbumTitle, where only the key attributes from theMusictable are projected into the index.
You can query the GenreAlbumTitle index to find all albums of a particular genre (for example, all Rock albums). You can also query the index to find all albums within a particular genre that have certain album titles (for example, all Country albums with titles that start with the letter H).
For more information, see Improving data access with secondary indexes in DynamoDB.
DynamoDB Streams
DynamoDB Streams is an optional feature that captures data modification events in DynamoDB tables. The data about these events appear in the stream in near-real time, and in the order that the events occurred.
Each event is represented by a stream record. If you enable a stream on a table, DynamoDB Streams writes a stream record whenever one of the following events occurs:
-
A new item is added to the table: The stream captures an image of the entire item, including all of its attributes.
-
An item is updated: The stream captures the "before" and "after" image of any attributes that were modified in the item.
-
An item is deleted from the table: The stream captures an image of the entire item before it was deleted.
Each stream record also contains the name of the table, the event timestamp, and other metadata. Stream records have a lifetime of 24 hours; after that, they are automatically removed from the stream.
You can use DynamoDB Streams together with Amazon Lambda to create a
trigger—code that runs automatically whenever an event of
interest appears in a stream. For example, consider a Customers
table that contains customer information for a company. Suppose that you want to
send a "welcome" email to each new customer. You could enable a stream on that
table, and then associate the stream with a Lambda function. The Lambda function would
run whenever a new stream record appears, but only process new items added to the
Customers table. For any item that has an
EmailAddress attribute, the Lambda function would invoke Amazon Simple Email Service
(Amazon SES) to send an email to that address.

Note
In this example, the last customer, Craig Roe, will not receive an email
because he doesn't have an EmailAddress.
In addition to triggers, DynamoDB Streams enables powerful solutions such as data replication within and across Amazon Regions, materialized views of data in DynamoDB tables, data analysis using Kinesis materialized views, and much more.
For more information, see Change data capture for DynamoDB Streams.