Scanning tables in DynamoDB
A Scan operation in Amazon DynamoDB reads every item in a table or a secondary index. By
default, a Scan operation returns all of the data attributes for every item in
the table or index. You can use the ProjectionExpression parameter so that
Scan only returns some of the attributes, rather than all of them.
Scan always returns a result set. If no matching items are found, the result
set is empty.
A single Scan request can retrieve a maximum of 1 MB of data.
Optionally, DynamoDB can apply a filter expression to this data, narrowing the results before
they are returned to the user.
Topics
Filter expressions for scan
If you need to further refine the Scan results, you can optionally
provide a filter expression. A filter expression determines which
items within the Scan results should be returned to you. All of the other
results are discarded.
A filter expression is applied after a Scan finishes but before the
results are returned. Therefore, a Scan consumes the same amount of read
capacity, regardless of whether a filter expression is present.
A Scan operation can retrieve a maximum of 1 MB of data.
This limit applies before the filter expression is evaluated.
With Scan, you can specify any attributes in a filter
expression—including partition key and sort key attributes.
The syntax for a filter expression is identical to that of a condition expression. Filter expressions can use the same comparators, functions, and logical operators as a condition expression. See Condition and filter expressions, operators, and functions in DynamoDB for more information about logical operators.
Example
The following Amazon Command Line Interface (Amazon CLI) example scans the Thread table and
returns only the items that were last posted to by a particular user.
aws dynamodb scan \ --table-name Thread \ --filter-expression "LastPostedBy = :name" \ --expression-attribute-values '{":name":{"S":"User A"}}'
Limiting the number of items in the result set
The Scan operation enables you to limit the number of items that it
returns in the result. To do this, set the Limit parameter to the maximum
number of items that you want the Scan operation to return, prior to filter
expression evaluation.
For example, suppose that you Scan a table with a Limit
value of 6 and without a filter expression. The Scan result
contains the first six items from the table.
Now suppose that you add a filter expression to the Scan. In this case,
DynamoDB applies the filter expression to the six items that were returned, discarding
those that do not match. The final Scan result contains six items or fewer,
depending on the number of items that were filtered.
Paginating the results
DynamoDB paginates the results from Scan operations.
With pagination, the Scan results are divided into "pages" of data that are
1 MB in size (or less). An application can process the first page of
results, then the second page, and so on.
A single Scan only returns a result set that fits within the
1 MB size limit.
To determine whether there are more results and to retrieve them one page at a time, applications should do the following:
-
Examine the low-level
Scanresult:-
If the result contains a
LastEvaluatedKeyelement, proceed to step 2. -
If there is not a
LastEvaluatedKeyin the result, then there are no more items to be retrieved.
-
-
Construct a new
Scanrequest, with the same parameters as the previous one. However, this time, take theLastEvaluatedKeyvalue from step 1 and use it as theExclusiveStartKeyparameter in the newScanrequest. -
Run the new
Scanrequest. -
Go to step 1.
In other words, the LastEvaluatedKey from a Scan response
should be used as the ExclusiveStartKey for the next Scan
request. If there is not a LastEvaluatedKey element in a Scan
response, you have retrieved the final page of results. (The absence of
LastEvaluatedKey is the only way to know that you have reached the end
of the result set.)
You can use the Amazon CLI to view this behavior. The Amazon CLI sends low-level
Scan requests to DynamoDB, repeatedly, until LastEvaluatedKey
is no longer present in the results. Consider the following Amazon CLI example that scans the
entire Movies table but returns only the movies from a particular
genre.
aws dynamodb scan \ --table-name Movies \ --projection-expression "title" \ --filter-expression 'contains(info.genres,:gen)' \ --expression-attribute-values '{":gen":{"S":"Sci-Fi"}}' \ --page-size 100 \ --debug
Ordinarily, the Amazon CLI handles pagination automatically. However, in this example, the
Amazon CLI --page-size parameter limits the number of items per page. The
--debug parameter prints low-level information about requests and
responses.
Note
Your pagination results will also differ based on the input parameters you pass.
-
Using
aws dynamodb scan --table-name Prices --max-items 1returns aNextToken -
Using
aws dynamodb scan --table-name Prices --limit 1returns aLastEvaluatedKey.
Also be aware that using --starting-token in particular requires the
NextToken value.
If you run the example, the first response from DynamoDB looks similar to the following.
2017-07-07 12:19:14,389 - MainThread - botocore.parsers - DEBUG - Response body: b'{"Count":7,"Items":[{"title":{"S":"Monster on the Campus"}},{"title":{"S":"+1"}}, {"title":{"S":"100 Degrees Below Zero"}},{"title":{"S":"About Time"}},{"title":{"S":"After Earth"}}, {"title":{"S":"Age of Dinosaurs"}},{"title":{"S":"Cloudy with a Chance of Meatballs 2"}}], "LastEvaluatedKey":{"year":{"N":"2013"},"title":{"S":"Curse of Chucky"}},"ScannedCount":100}'
The LastEvaluatedKey in the response indicates that not all of the items
have been retrieved. The Amazon CLI then issues another Scan request to DynamoDB.
This request and response pattern continues, until the final response.
2017-07-07 12:19:17,830 - MainThread - botocore.parsers - DEBUG - Response body: b'{"Count":1,"Items":[{"title":{"S":"WarGames"}}],"ScannedCount":6}'
The absence of LastEvaluatedKey indicates that there are no more items to
retrieve.
Note
The Amazon SDKs handle the low-level DynamoDB responses (including the presence or
absence of LastEvaluatedKey) and provide various abstractions for
paginating Scan results. For example, the SDK for Java document interface
provides java.util.Iterator support so that you can walk through the
results one at a time.
For code examples in various programming languages, see the Amazon DynamoDB Getting Started Guide and the Amazon SDK documentation for your language.
Counting the items in the results
In addition to the items that match your criteria, the Scan response
contains the following elements:
-
ScannedCount— The number of items evaluated, before anyScanFilteris applied. A highScannedCountvalue with few, or no,Countresults indicates an inefficientScanoperation. If you did not use a filter in the request,ScannedCountis the same asCount. -
Count— The number of items that remain, after a filter expression (if present) was applied.
Note
If you do not use a filter expression, ScannedCount and
Count have the same value.
If the size of the Scan result set is larger than 1 MB,
ScannedCount and Count represent only a partial count of
the total items. You need to perform multiple Scan operations to retrieve
all the results (see Paginating the results).
Each Scan response contains the ScannedCount and
Count for the items that were processed by that particular
Scan request. To get grand totals for all of the Scan
requests, you could keep a running tally of both ScannedCount and
Count.
Capacity units consumed by scan
You can Scan any table or secondary index. Scan operations consume read
capacity units, as follows.
If you Scan a... |
DynamoDB consumes read capacity units from... |
|---|---|
| Table | The table's provisioned read capacity. |
| Global secondary index | The index's provisioned read capacity. |
| Local secondary index | The base table's provisioned read capacity. |
Note
Cross-account access for secondary index scan operations is currently not supported with resource-based policies.
By default, a Scan operation does not return any data on how much read
capacity it consumes. However, you can specify the ReturnConsumedCapacity
parameter in a Scan request to obtain this information. The following are
the valid settings for ReturnConsumedCapacity:
-
NONE— No consumed capacity data is returned. (This is the default.) -
TOTAL— The response includes the aggregate number of read capacity units consumed. -
INDEXES— The response shows the aggregate number of read capacity units consumed, together with the consumed capacity for each table and index that was accessed.
DynamoDB calculates the number of read capacity units consumed based on the number of
items and the size of those items, not on the amount of data that is returned to an
application. For this reason, the number of capacity units consumed is the same whether
you request all of the attributes (the default behavior) or just some of them (using a
projection expression). The number is also the same whether or not you use a filter
expression. Scan consumes a minimum read capacity unit to perform one
strongly consistent read per second, or two eventually consistent reads per second for
an item up to 4 KB. If you need to read an item that is larger than 4 KB, DynamoDB needs
additional read request units. Empty tables and very large tables which have a sparse
amount of partition keys might see some additional RCUs charged beyond the amount of
data scanned. This covers the cost of serving the Scan request, even if no
data exists.
Read consistency for scan
A Scan operation performs eventually consistent reads, by default. This
means that the Scan results might not reflect changes due to recently
completed PutItem or UpdateItem operations. For more
information, see DynamoDB read consistency.
If you require strongly consistent reads, as of the time that the Scan
begins, set the ConsistentRead parameter to true in the
Scan request. This ensures that all of the write operations that
completed before the Scan began are included in the Scan
response.
Setting ConsistentRead to true can be useful in table backup
or replication scenarios, in conjunction with DynamoDB Streams.
You first use Scan with ConsistentRead set to true to obtain a
consistent copy of the data in the table. During the Scan, DynamoDB Streams records any
additional write activity that occurs on the table. After the Scan is
complete, you can apply the write activity from the stream to the table.
Note
A Scan operation with ConsistentRead set to
true consumes twice as many read capacity units as compared to
leaving ConsistentRead at its default value
(false).
Parallel scan
By default, the Scan operation processes data sequentially. Amazon DynamoDB returns
data to the application in 1 MB increments, and an application performs
additional Scan operations to retrieve the next 1 MB of data.
The larger the table or index being scanned, the more time the Scan takes to
complete. In addition, a sequential Scan might not always be able to fully use
the provisioned read throughput capacity: Even though DynamoDB distributes a large table's data
across multiple physical partitions, a Scan operation can only read one
partition at a time. For this reason, the throughput of a Scan is constrained
by the maximum throughput of a single partition.
To address these issues, the Scan operation can logically divide a table or
secondary index into multiple segments, with multiple application workers scanning
the segments in parallel. Each worker can be a thread (in programming languages that support
multithreading) or an operating system process. To perform a parallel scan, each worker
issues its own Scan request with the following parameters:
-
Segment— A segment to be scanned by a particular worker. Each worker should use a different value forSegment. -
TotalSegments— The total number of segments for the parallel scan. This value must be the same as the number of workers that your application will use.
The following diagram shows how a multithreaded application performs a parallel
Scan with three degrees of parallelism.
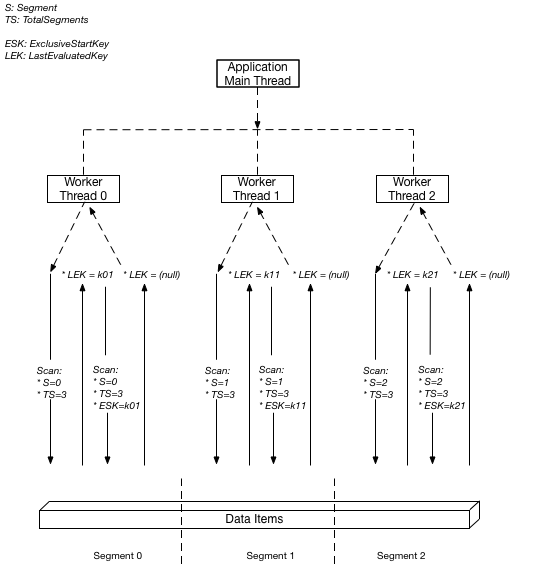
In this diagram, the application spawns three threads and assigns each thread a
number. (Segments are zero-based, so the first number is always 0.) Each thread issues a
Scan request, setting Segment to its designated number
and setting TotalSegments to 3. Each thread scans its designated segment,
retrieving data 1 MB at a time, and returns the data to the application's main
thread.
DynamoDB assigns items to segments by applying a hash function to each item's partition key.
For a given TotalSegments value, all items with the same partition key are always assigned to the same Segment. This means that in a table where
Item 1, Item 2, and Item 3 all share pk="account#123" (but have different sort keys),
these items will be processed by the same worker, regardless of the sort key values or the size of the item collection.
Because segment assignment is based solely on the partition key hash, segments can be unevenly distributed. Some segments might contain no items, while others might contain many partition keys with large item collections. As a result, increasing the total number of segments does not guarantee faster scan performance, particularly when partition keys are not uniformly distributed across the keyspace.
The values for Segment and TotalSegments apply to individual
Scan requests, and you can use different values at any time. You
might need to experiment with these values, and the number of workers you use, until your
application achieves its best performance.
Note
A parallel scan with a large number of workers can easily consume all of the provisioned throughput for the table or index being scanned. It is best to avoid such scans if the table or index is also incurring heavy read or write activity from other applications.
To control the amount of data returned per request, use the Limit
parameter. This can help prevent situations where one worker consumes all of the
provisioned throughput, at the expense of all other workers.