Using Global Secondary Index write sharding for selective table queries in DynamoDB
When you need to query recent data within a specific time window, DynamoDB's requirement of providing a partition key for most read operations can present a challenge. To address this scenario, you can implement an effective query pattern using a combination of write sharding and a Global Secondary Index (GSI).
This approach allows you to efficiently retrieve and analyze time-sensitive data without performing full table scans, which can be resource-intensive and costly. By strategically designing your table structure and indexing, you can create a flexible solution that supports time-based data retrieval while maintaining optimal performance.
Topics
Pattern design
When working with DynamoDB, you can overcome time-based data retrieval challenges by implementing a sophisticated pattern that combines write sharding and Global Secondary Indexes to enable flexible, efficient querying across recent data windows.
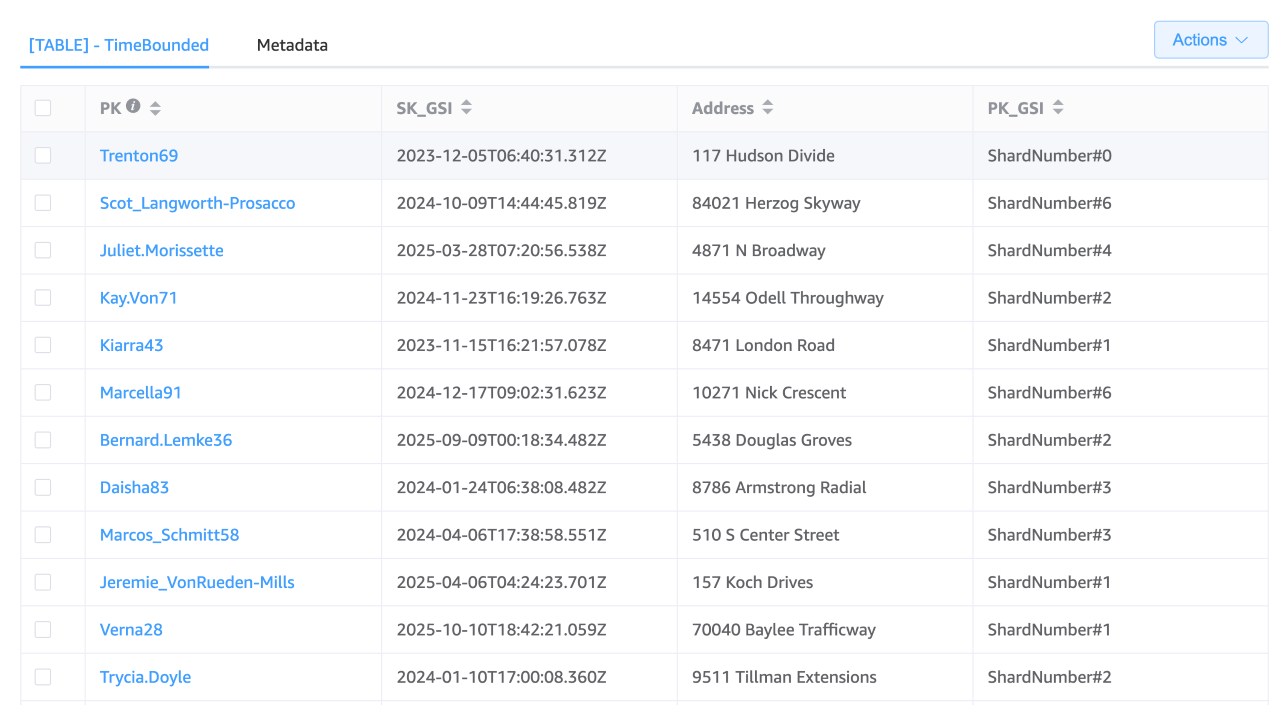
Structure of the table
Partition Key (PK): "Username"
Structure of the GSI
GSI Partition Key (PK_GSI): "ShardNumber#"
GSI Sort Key (SK_GSI): ISO 8601 timestamp (e.g., "2030-04-01T12:00:00Z")
Sharding strategy
Assuming you decide to use 10 shards, your shard numbers could range from 0 to 9. When logging an activity, you would calculate the shard number (for example, by using a hash function on the user ID and then taking the modulus of the number of shards) and prepend it to the GSI partition key. This method distributes the entries across different shards, mitigating the risk of hot partitions.
Querying the sharded GSI
Querying across all shards for items within a particular time range in a DynamoDB table, where data is sharded across multiple partition keys, requires a different approach than querying a single partition. Since DynamoDB queries are limited to a single partition key at a time, you can't directly query across multiple shards with a single query operation. However, you can achieve the desired result through application-level logic by performing multiple queries, each targeting a specific shard, and then aggregating the results. The procedure below explains how to do this.
To query and aggregate shards
Identify the range of shard numbers used in your sharding strategy. For instance, if you have 10 shards, your shard numbers would range from 0-9.
For each shard, construct and execute a query to fetch items within the desired time range. These queries can be executed in parallel to improve efficiency. Use the partition key with the shard number and the sort key with your time range for these queries. Here's an example query for a single shard:
aws dynamodb query \ --table-name "YourTableName" \ --index-name "YourIndexName" \ --key-condition-expression "PK_GSI = :pk_val AND SK_GSI BETWEEN :start_date AND :end_date" \ --expression-attribute-values '{ ":pk_val": {"S": "ShardNumber#0"}, ":start_date": {"S": "2024-04-01"}, ":end_date": {"S": "2024-04-30"} }'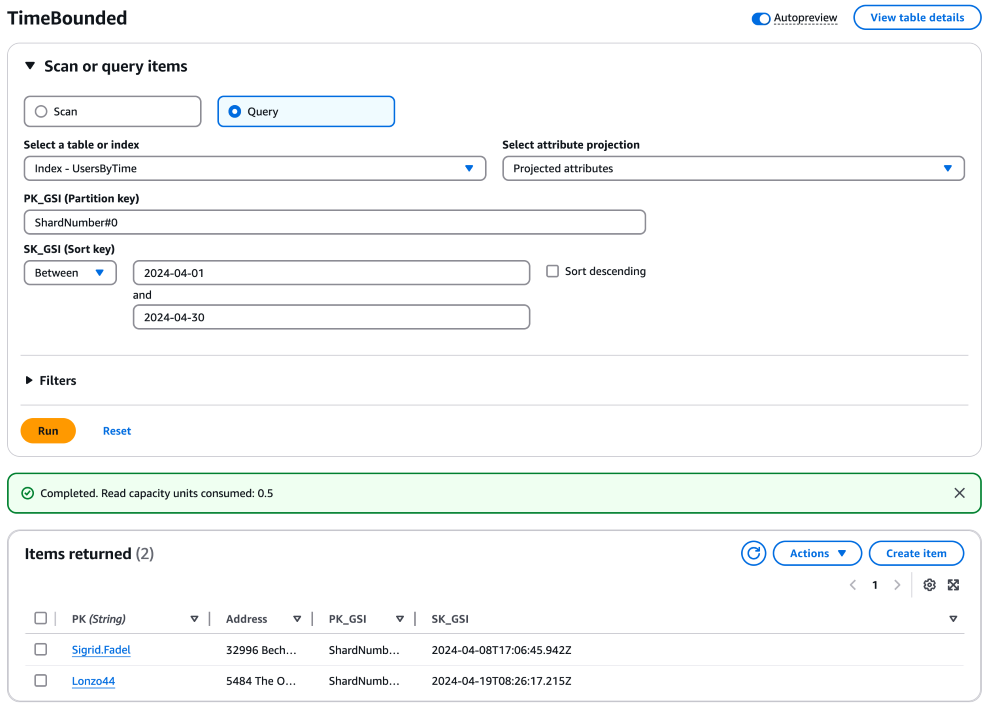
You would replicate this query for each shard, adjusting the partition key accordingly (e.g., "ShardNumber#1", "ShardNumber#2", ..., "ShardNumber#9").
Aggregate the results from each query after all queries are complete. Perform this aggregation in your application code, combining the results into a single dataset that represents the items from all shards within your specified time range.
Parallel query execution considerations
Each query consumes read capacity from your table or index. If you're using provisioned throughput, ensure that your table is provisioned with enough capacity to handle the burst of parallel queries. If you're using on-demand capacity, be mindful of the potential cost implications.
Code example
To execute parallel queries across shards in DynamoDB using Python, you can use the boto3 library, which is the Amazon Web Services SDK for Python. This example assumes you have boto3 installed and configured with appropriate Amazon credentials.
The following Python code demonstrates how to perform parallel queries across multiple shards for a given time range. It uses concurrent futures to execute queries in parallel, reducing the overall execution time compared to sequential execution.
import boto3 from concurrent.futures import ThreadPoolExecutor, as_completed # Initialize a DynamoDB client dynamodb = boto3.client('dynamodb') # Define your table name and the total number of shards table_name = 'YourTableName' total_shards = 10 # Example: 10 shards numbered 0 to 9 time_start = "2030-03-15T09:00:00Z" time_end = "2030-03-15T10:00:00Z" def query_shard(shard_number): """ Query items in a specific shard for the given time range. """ response = dynamodb.query( TableName=table_name, IndexName='YourGSIName', # Replace with your GSI name KeyConditionExpression="PK_GSI = :pk_val AND SK_GSI BETWEEN :date_start AND :date_end", ExpressionAttributeValues={ ":pk_val": {"S": f"ShardNumber#{shard_number}"}, ":date_start": {"S": time_start}, ":date_end": {"S": time_end}, } ) return response['Items'] # Use ThreadPoolExecutor to query across shards in parallel with ThreadPoolExecutor(max_workers=total_shards) as executor: # Submit a future for each shard query futures = {executor.submit(query_shard, shard_number): shard_number for shard_number in range(total_shards)} # Collect and aggregate results from all shards all_items = [] for future in as_completed(futures): shard_number = futures[future] try: shard_items = future.result() all_items.extend(shard_items) print(f"Shard {shard_number} returned {len(shard_items)} items") except Exception as exc: print(f"Shard {shard_number} generated an exception: {exc}") # Process the aggregated results (e.g., sorting, filtering) as needed # For example, simply printing the count of all retrieved items print(f"Total items retrieved from all shards: {len(all_items)}")
Before running this code, make sure to replace YourTableName and YourGSIName with the
actual table and GSI names from your DynamoDB setup. Also, adjust total_shards, time_start,
and time_end variables according to your specific requirements.
This script queries each shard for items within the specified time range and aggregates the results.