Best practices for using sort keys to organize data in DynamoDB
In an Amazon DynamoDB table, the primary key that uniquely identifies each item in the table can be composed of a partition key and a sort key.
Well-designed sort keys have two key benefits:
They gather related information together in one place where it can be queried efficiently. Careful design of the sort key lets you retrieve commonly needed groups of related items using range queries with operators such as
begins_with,between,>,<, and so on.-
Composite sort keys let you define hierarchical (one-to-many) relationships in your data that you can query at any level of the hierarchy.
For example, in a table listing geographical locations, you might structure the sort key as follows.
[country]#[region]#[state]#[county]#[city]#[neighborhood]This would let you make efficient range queries for a list of locations at any one of these levels of aggregation, from
country, to aneighborhood, and everything in between.
Using sort keys for version control
Many applications need to maintain a history of item-level revisions for audit or compliance purposes and to be able to retrieve the most recent version easily. There is an effective design pattern that accomplishes this using sort key prefixes:
For each new item, create two copies of the item: One copy should have a version-number prefix of zero (such as
v0_) at the beginning of the sort key, and one should have a version-number prefix of one (such asv1_).Every time the item is updated, use the next higher version-prefix in the sort key of the updated version, and copy the updated contents into the item with version-prefix zero. This means that the latest version of any item can be located easily using the zero prefix.
For example, a parts manufacturer might use a schema like the one illustrated below.
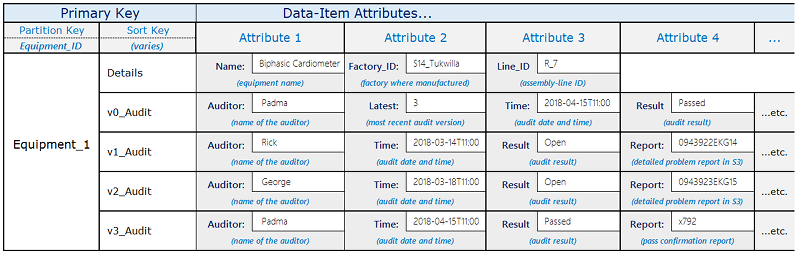
The Equipment_1 item goes through a sequence of audits by various auditors.
The results of each new audit are captured in a new item in the table, starting with version
number one, and then incrementing the number for each successive revision.
When each new revision is added, the application layer replaces the contents of the
zero-version item (having sort key equal to v0_Audit) with the contents of the
new revision.
Whenever the application needs to retrieve for the most recent audit status, it can query
for the sort key prefix of v0_.
If the application needs to retrieve the entire revision history,
it can query all the items under the item's partition key and filter out
the v0_ item.
This design also works for audits across multiple parts of a piece of equipment, if you include the individual part-IDs in the sort key after the sort key prefix.