Data Modeling foundations in DynamoDB
This section covers the foundation layer by examining the two types of table design: single table and multiple table.
Single table design foundation
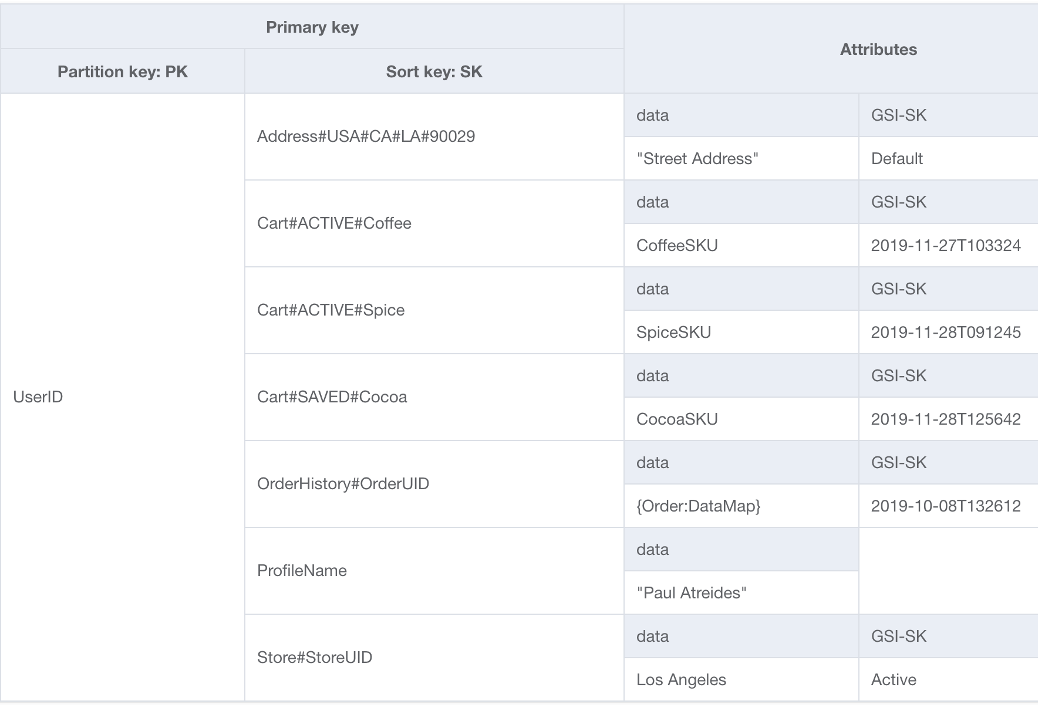
One choice for the foundation of our DynamoDB schema is single table design. Single table design is a pattern that allows you to store multiple types (entities) of data in a single DynamoDB table. It aims to optimize data access patterns, improve performance, and reduce costs by eliminating the need for maintaining multiple tables and complex relationships between them. This is possible because DynamoDB stores items with the same partition key (known as an item collection) on the same partition(s) as each other. In this design, different types of data are stored as items in the same table, and each item is identified by a unique sort key.
Advantages
-
Data locality to support queries for multiple entity types in a single database call
-
Reduces overall financial and latency costs of reads:
-
A single query for two items totalling less than 4KB is 0.5 RCU eventually consistent
-
Two queries for two items totalling less than 4KB is 1 RCU eventually consistent (0.5 RCU each)
-
The time to return two separate database calls will average higher than a single call
-
-
Reduces the number of tables to manage:
-
Permissions do not need to be maintained across multiple IAM roles or policies
-
Capacity management for the table is averaged across all entities, usually resulting in a more predictable consumption pattern
-
Monitoring requires fewer alarms
-
Customer Managed Encryption Keys only need to be rotated on one table
-
-
Smooths traffic to the table:
-
By aggregating multiple usage patterns to the same table, the overall usage tends to be smoother (the way a stock index's performance tends to be smoother than any individual stock) which works better for achieving higher utilization with provisioned mode tables
-
Disadvantages
-
Learning curve can be steep due to paradoxical design compared to relational databases
-
Data requirements must be consistent across all entity types
-
Backups are all or nothing so if some data is not mission critical, consider keeping it in a separate table
-
Table encryption is shared across all items. For multi-tenant applications with individual tenant encryption requirements, client side encryption would be required
-
Tables with a mix of historical data and operational data will not see as much of a benefit from enabling the Infrequent Access Storage Class. For more information, see DynamoDB table classes
-
-
All changed data will be propagated to DynamoDB Streams even if only a subset of entities need to be processed.
-
Thanks to Lambda event filters, this will not affect your bill when using Lambda, but will be an added cost when using the Kinesis Consumer Library
-
-
When using GraphQL, single table design will be more difficult to implement
-
When using higher-level SDK clients like Java's DynamoDBMapper or Enhanced Client, it can be more difficult to process results because items in the same response may be associated with different classes
When to use
Single table design works well for applications that frequently query multiple entity types together or need to maintain relationships between different data types. It's particularly effective when your access patterns benefit from data locality and when you want to minimize the overhead of managing multiple tables.
Multiple table design foundation
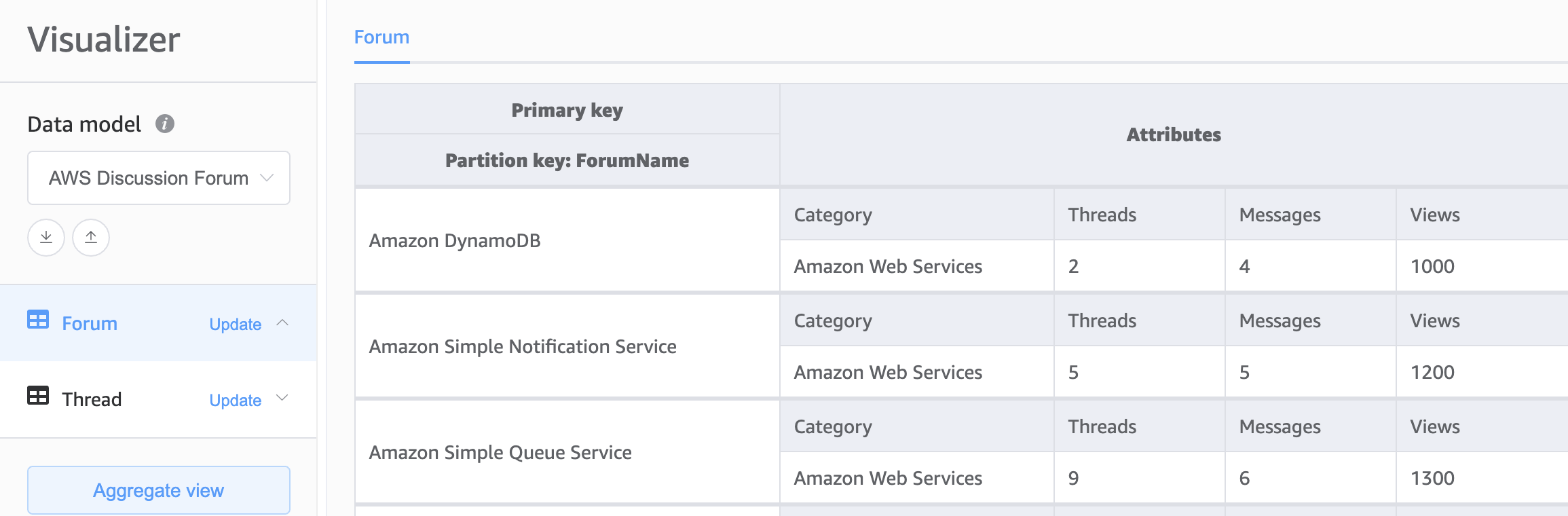
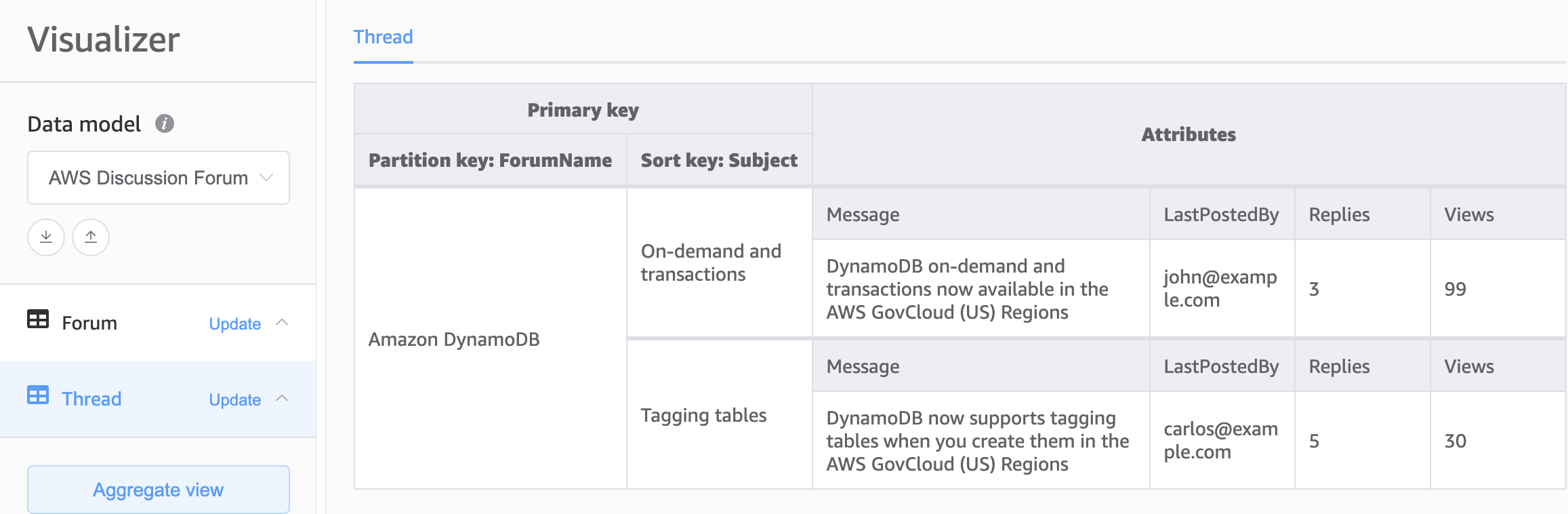
The second choice for the foundation of our DynamoDB schema is multiple table design. Multiple table design is a pattern that is more like a traditional database design where you store a single type(entity) of data in a each DynamoDB table. Data within each table will still be organized by partition key so performance within a single entity type will be optimized for scalability and performance, but queries across multiple tables must be done independently.
Advantages
-
Simpler to design for those who aren't used to working with single table design
-
Easier implementation of GraphQL resolvers due to each resolver mapping to a single entity(table)
-
Allows for unique data requirements across different entity types:
-
Backups can be made for the individual tables that are mission critical
-
Table encryption can be managed for each table. For multi-tenant applications with individual tenant encryption requirements, separate tenant tables make it possible for each customer to have their own encryption key
-
Infrequent Access Storage Class can be enabled on just the tables with historical data to realize the full cost savings benefit. For more information, see DynamoDB table classes
-
-
Each table will have its own change data stream allowing for a dedicated Lambda function to be designed for each type of item rather than a single monolithic processor
Disadvantages
-
For access patterns that require data across multiple tables, multiple reads from DynamoDB will be required and data may need to be processed/joined on the client code.
-
Operations and monitoring of multiple tables requires more CloudWatch alarms and each table must be scaled independently
-
Each tables permissions will need to be managed separately. The addition of tables in the future will require a change to any necessary IAM roles or policies
When to use
If your application’s access patterns do not have the need to query multiple entities or tables together, then multiple table design is a good and sufficient approach.