ETL features
This topic provides reference information about migrating ETL (Extract, Transform, Load) functionality from Microsoft SQL Server 2019 to Amazon Aurora PostgreSQL. It introduces Amazon Glue as an alternative to SQL Server’s native ETL tools, specifically SQL Server Integration Services (SSIS) which replaced the older Data Transformation Services (DTS).
| Feature compatibility | Amazon SCT / Amazon DMS automation level | Amazon SCT action code index | Key differences |
|---|---|---|---|
|
|
N/A |
N/A |
Use Amazon Glue |

SQL Server Usage
SQL Server offers a native extract, transform, and load (ETL) framework of tools and services to support enterprise ETL requirements. The legacy Data Transformation Services (DTS) has been deprecated as of SQL
Server 2008 and replaced with SQL Server Integration Services (SSIS), which was introduced in SQL Server 2005. For more information, see Data Transformation Services (DTS)
DTS
DTS was introduced in SQL Server version 7 in 1998. It was significantly expanded in SQL Server 2000 with features such as FTP, database level operations, and Microsoft Message Queuing (MSMQ) integration. It included a set of objects, utilities, and services that enabled easy, visual construction of complex ETL operations across heterogeneous data sources and targets.
DTS supported OLE DB, ODBC, and text file drivers. It allowed transformations to be scheduled using SQL Server Agent. For more information, see SQL Server Agent. DTS also provided version control and backup capabilities with version control systems such as Microsoft Visual SourceSafe.
The fundamental entity in DTS was the DTS Package. Packages were the logical containers for DTS objects such as connections, data transfers, transformations, and notifications. The DTS framework also included the following tools:
-
DTS Wizards.
-
DTS Package Designers.
-
DTS Query Designer.
-
DTS Run Utility.
SSIS
The SSIS framework was introduced in SQL Server 2005, but was limited to the top-tier editions only, unlike DTS which was available with all editions.
SSIS has evolved over DTS to offer a true modern, enterprise class, heterogeneous platform for a broad range of data migration and processing tasks. It provides a rich workflow-oriented design with features for all types of enterprise data warehousing. It also supports scheduling capabilities for multi-dimensional cubes management.
SSIS provides the following tools:
-
SSIS Import/Export Wizard is an SQL Server Management Studio extension that enables quick creation of packages for moving data between a wide array of sources and destinations. However, it has limited transformation capabilities.
-
SQL Server Business Intelligence Development Studio (BIDS) is a developer tool for creating complex packages and transformations. It provides the ability to integrate procedural code into package transformations and provides a scripting environment. Recently, BIDS has been replaced by SQL Server Data Tools - Business intelligence (SSDT-BI).
SSIS objects include:
-
Connections.
-
Event handlers.
-
Workflows.
-
Error handlers.
-
Parameters (starting with SQL Server 2012).
-
Precedence constraints.
-
Tasks.
-
Variables.
SSIS packages are constructed as XML documents and you can save them to the file system or store within a SQL Server instance using a hierarchical name space.
For more information, see SQL Server Integration Services
PostgreSQL Usage
Amazon Aurora PostgreSQL-Compatible Edition (Aurora PostgreSQL) provides Amazon Glue
Amazon Glue Key Features
Integrated data catalog
The Amazon Glue Data Catalog is a persistent metadata store, that you can use to store all data assets, whether in the cloud or on-premises. It stores table schemas, job steps, and additional meta data information for managing these processes. Amazon Glue can automatically calculate statistics and register partitions to make queries more efficient. It maintains a comprehensive schema version history for tracking changes over time.
Automatic schema discovery
Amazon Glue provides automatic crawlers that can connect to source or target data providers. The crawler uses a prioritized list of classifiers to determine the schema for your data and then generates and stores the metadata in the Amazon Glue Data Catalog. You can schedule crawlers or run on-demand. You can also trigger a crawler when an event occurs to keep metadata current.
Code generation
Amazon Glue automatically generates the code to extract, transform, and load data. All you need to do is point Glue to your data source and target. The ETL scripts to transform, flatten, and enrich data are created automatically. You can generate Amazon Glue scripts in Scala or Python and use them in Apache Spark.
Developer endpoints
When interactively developing Amazon Glue ETL code, Amazon Glue provides development endpoints for editing, debugging, and testing. You can use any IDE or text editor for ETL development. You can import custom readers, writers, and transformations into Glue ETL jobs as libraries. You can also use and share code with other developers in the Amazon Glue GitHub repository
Flexible job scheduler
You can trigger Amazon Glue jobs for running either on a pre-defined schedule, on-demand, or as a response to an event.
You can start multiple jobs in parallel and explicitly define dependencies across jobs to build complex ETL pipelines. Amazon Glue handles all inter-job dependencies, filters bad data, and retries failed jobs. All logs and notifications are pushed to Amazon CloudWatch; you can monitor and get alerts from a central service.
Migration Considerations
You can use Amazon Schema Conversion Tool (Amazon SCT) to convert your Microsoft SSIS ETL scripts to Amazon Glue. For more information, see Converting SSIS.
Examples
The following walkthrough describes how to create an Amazon Glue job to upload a comma-separated values (CSV) file from Amazon S3 to Aurora PostgreSQL.
The source file for this walkthrough is a simple Visits table in CSV format. The objective is to upload this file to an Amazon S3 bucket and create an Amazon Glue job to discover and copy it into an Aurora PostgreSQL database.
Step 1 — Create a Bucket in Amazon S3 and Upload the CSV File
-
In the Amazon console, choose S3, and then choose Create bucket.
Note
This walkthrough demonstrates how to create the buckets and upload the files manually, which is automated using the Amazon S3 API for production ETLs. Using the console to manually run all the settings will help you get familiar with the terminology, concepts, and workflow.
-
Enter a unique name for the bucket, select a region, and define the level of access.
-
Turn on versioning, add tags, turn on server-side encryption, and choose Create bucket.
-
On the Amazon S3 Management Console, choose the newly created bucket.
-
On the bucket page, choose Upload.
-
Choose Add files, select your CSV file, and choose Upload.
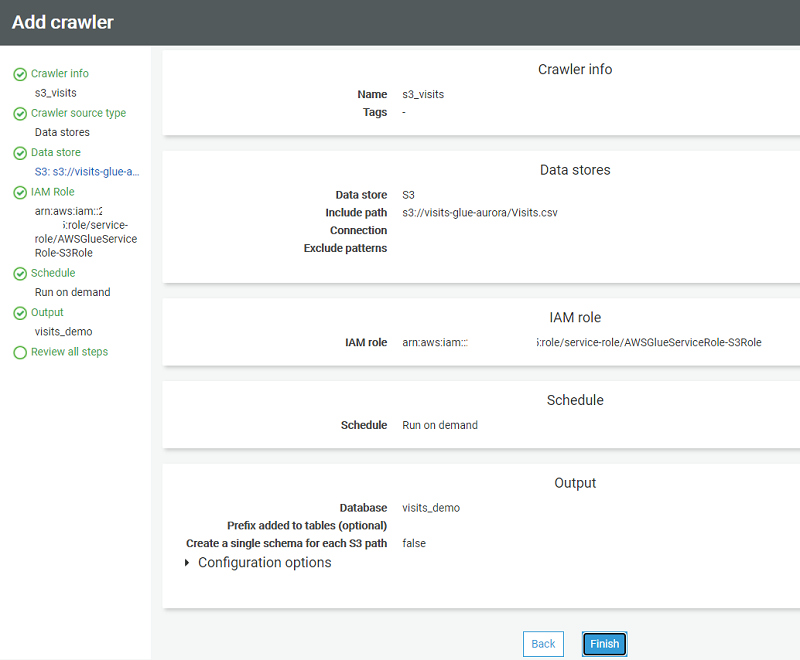
Step 2 — Add an Amazon Glue Crawler to Discover and Catalog the Visits File
-
In the Amazon console, choose Amazon Glue .
-
Choose Tables, and then choose Add tables using a crawler.
-
Enter the name of the crawler and choose Next.
-
On the Specify crawler source type page, leave the default values, and choose Next.
-
On the Add a data store page, specify a valid Amazon S3 path, and choose Next.
-
On the Choose an IAM role page, choose an existing IAM role, or create a new IAM role. Choose Next.
-
On the Create a schedule for this crawler page, choose Run on demand, and choose Next.
-
On the Configure the crawler’s output page, choose a database for the crawler’s output, enter an optional table prefix for easy reference, and choose Next.
-
Review the information that you provided and choose Finish to create the crawler.
Step 3 — Run the Amazon Glue Crawler
-
In the Amazon console, choose Amazon Glue , and then choose Crawlers.
-
Choose the crawler that you created on the previous step, and choose Run crawler.
After the crawler completes, the table should be discovered and recorded in the catalog in the table specified.
Click the link to get to the table that was just discovered and then click the table name.
Verify the crawler identified the table’s properties and schema correctly.
Note
You can manually adjust the properties and schema JSON files using the buttons on the top right.
If you don’t want to add a crawler, you can add tables manually.
-
In the Amazon console, choose Amazon Glue .
-
Choose Tables, and then choose Add table manually.
Step 4 — Create an ETL Job to Copy the Visits Table to an Aurora PostgreSQL Database
-
In the Amazon console, choose Amazon Glue .
-
Choose Jobs (legacy), and then choose Add job.
-
Enter a name for the ETL job and pick a role for the security context. For this example, use the same role created for the crawler. The job may consist of a pre-existing ETL script, a manually-authored script, or an automatic script generated by Amazon Glue. For this example, use Amazon Glue. Enter a name for the script file or accept the default, which is also the job’s name. Configure advanced properties and parameters if needed and choose Next.
-
Select the data source for the job and choose Next.
-
On the Choose a transform type page, choose Change schema.
-
On the Choose a data target page, choose Create tables in your data target, use the JDBC Data store, and the
gluerdsconnection type. Choose Add Connection. -
On the Add connection page, enter the access details for the Amazon Aurora Instance and choose Add.
-
Choose Next to display the column mapping between the source and target. Leave the default mapping and data types, and choose Next.
-
Review the job properties and choose Save job and edit script.
-
Review the generated script and make manual changes if needed. You can use the built-in templates for source, target, target location, transform, and spigot using the buttons at the top right section of the screen.
-
Choose Run job.
-
In the Amazon console, choose Amazon Glue , and then choose Jobs (legacy).
-
On the history tab, verify that the job status is set to Succeeded.
-
Open your query IDE, connect to the Aurora PostgreSQL cluster, and query the visits database to make sure the data has been transferred successfully.
For more information, see Amazon Glue Developer Guide and Amazon Glue resources