Help improve this page
To contribute to this user guide, choose the Edit this page on GitHub link that is located in the right pane of every page.
Kubernetes concepts
Amazon Elastic Kubernetes Service (Amazon EKS) is an Amazon managed service based on the open source Kubernetes
This page divides Kubernetes concepts into three sections: Why Kubernetes?, Clusters, and Workloads. The first section describes the value of running a Kubernetes service, in particular as a managed service like Amazon EKS. The Workloads section covers how Kubernetes applications are built, stored, run, and managed. The Clusters section lays out the different components that make up Kubernetes clusters and what your responsibilities are for creating and maintaining Kubernetes clusters.
As you go through this content, links will lead you to further descriptions of Kubernetes concepts in both Amazon EKS and Kubernetes documentation, in case you want to take deep dives into any of the topics we cover here. For details about how Amazon EKS implements Kubernetes control plane and compute features, see Amazon EKS architecture.
Why Kubernetes?
Kubernetes was designed to improve availability and scalability when running mission-critical, production-quality containerized applications. Rather than just running Kubernetes on a single machine (although that is possible), Kubernetes achieves those goals by allowing you to run applications across sets of computers that can expand or contract to meet demand. Kubernetes includes features that make it easier for you to:
-
Deploy applications on multiple machines (using containers deployed in Pods)
-
Monitor container health and restart failed containers
-
Scale containers up and down based on load
-
Update containers with new versions
-
Allocate resources between containers
-
Balance traffic across machines
Having Kubernetes automate these types of complex tasks allows an application developer to focus on building and improving their application workloads, rather than worrying about infrastructure. The developer typically creates configuration files, formatted as YAML files, that describe the desired state of the application. This could include which containers to run, resource limits, number of Pod replicas, CPU/memory allocation, affinity rules, and more.
Attributes of Kubernetes
To achieve its goals, Kubernetes has the following attributes:
-
Containerized — Kubernetes is a container orchestration tool. To use Kubernetes, you must first have your applications containerized. Depending on the type of application, this could be as a set of microservices, as batch jobs or in other forms. Then, your applications can take advantage of a Kubernetes workflow that encompasses a huge ecosystem of tools, where containers can be stored as images in a container registry
, deployed to a Kubernetes cluster , and run on an available node . You can build and test individual containers on your local computer with Docker or another container runtime , before deploying them to your Kubernetes cluster. -
Scalable — If the demand for your applications exceeds the capacity of the running instances of those applications, Kubernetes is able to scale up. As needed, Kubernetes can tell if applications require more CPU or memory and respond by either automatically expanding available capacity or using more of existing capacity. Scaling can be done at the Pod level, if there is enough compute available to just run more instances of the application (horizontal Pod autoscaling
), or at the node level, if more nodes need to be brought up to handle the increased capacity (Cluster Autoscaler or Karpenter ). As capacity is no longer needed, these services can delete unnecessary Pods and shut down unneeded nodes. -
Available — If an application or node becomes unhealthy or unavailable, Kubernetes can move running workloads to another available node. You can force the issue by simply deleting a running instance of a workload or node that’s running your workloads. The bottom line here is that workloads can be brought up in other locations if they can no longer run where they are.
-
Declarative — Kubernetes uses active reconciliation to constantly check that the state that you declare for your cluster matches the actual state. By applying Kubernetes objects
to a cluster, typically through YAML-formatted configuration files, you can, for example, ask to start up the workloads you want to run on your cluster. You can later change the configurations to do something like use a later version of a container or allocate more memory. Kubernetes will do what it needs to do to establish the desired state. This can include bringing nodes up or down, stopping and restarting workloads, or pulling updated containers. -
Composable — Because an application typically consists of multiple components, you want to be able to manage a set of these components (often represented by multiple containers) together. While Docker Compose offers a way to do this directly with Docker, the Kubernetes Kompose
command can help you do that with Kubernetes. See Translate a Docker Compose File to Kubernetes Resources for an example of how to do this. -
Extensible — Unlike proprietary software, the open source Kubernetes project is designed to be open to you extending Kubernetes any way that you like to meet your needs. APIs and configuration files are open to direct modifications. Third-parties are encouraged to write their own Controllers
, to extend both infrastructure and end-user Kubernetes features. Webhooks let you set up cluster rules to enforce policies and adapt to changing conditions. For more ideas on how to extend Kubernetes clusters, see Extending Kubernetes . -
Portable — Many organizations have standardized their operations on Kubernetes because it allows them to manage all of their application needs in the same way. Developers can use the same pipelines to build and store containerized applications. Those applications can then be deployed to Kubernetes clusters running on-premises, in clouds, on point-of-sales terminals in restaurants, or on IoT devices dispersed across a company’s remote sites. Its open source nature makes it possible for people to develop these special Kubernetes distributions, along with tools needed to manage them.
Managing Kubernetes
Kubernetes source code is freely available, so with your own equipment you could install and manage Kubernetes yourself. However, self-managing Kubernetes requires deep operational expertise and takes time and effort to maintain. For those reasons, most people deploying production workloads choose a cloud provider (such as Amazon EKS) or on-premises provider (such as Amazon EKS Anywhere) with its own tested Kubernetes distribution and support of Kubernetes experts. This allows you to offload much of the undifferentiated heavy lifting needed to maintain your clusters, including:
-
Hardware — If you don’t have hardware available to run Kubernetes per your requirements, a cloud provider such as Amazon Amazon EKS can save you on upfront costs. With Amazon EKS, this means that you can consume the best cloud resources offered by Amazon, including compute instances (Amazon Elastic Compute Cloud), your own private environment (Amazon VPC), central identity and permissions management (IAM), and storage (Amazon EBS). Amazon manages the computers, networks, data centers, and all the other physical components needed to run Kubernetes. Likewise, you don’t have to plan your datacenter to handle the maximum capacity on your highest-demand days. For Amazon EKS Anywhere, or other on premises Kubernetes clusters, you are responsible for managing the infrastructure used in your Kubernetes deployments, but you can still rely on Amazon to help you keep Kubernetes up to date.
-
Control plane management — Amazon EKS manages the security and availability of the Amazon-hosted Kubernetes control plane, which is responsible for scheduling containers, managing the availability of applications, and other key tasks, so you can focus on your application workloads. If your cluster breaks, Amazon should have the means to restore your cluster to a running state. For Amazon EKS Anywhere, you would manage the control plane yourself.
-
Tested upgrades — When you upgrade your clusters, you can rely on Amazon EKS or Amazon EKS Anywhere to provide tested versions of their Kubernetes distributions.
-
Add-ons — There are hundreds of projects built to extend and work with Kubernetes that you can add to your cluster’s infrastructure or use to aid the running of your workloads. Instead of building and managing those add-ons yourself, Amazon provides Amazon EKS add-ons that you can use with your clusters. Amazon EKS Anywhere provides Curated Packages
that include builds of many popular open source projects. So you don’t have to build the software yourself or manage critical security patches, bug fixes, or upgrades. Likewise, if the defaults meet your needs, it’s typical for very little configuration of those add-ons to be needed. See Extend Clusters for details on extending your cluster with add-ons.
Kubernetes in action
The following diagram shows key activities you would do as a Kubernetes Admin or Application Developer to create and use a Kubernetes cluster. In the process, it illustrates how Kubernetes components interact with each other, using the Amazon cloud as the example of the underlying cloud provider.
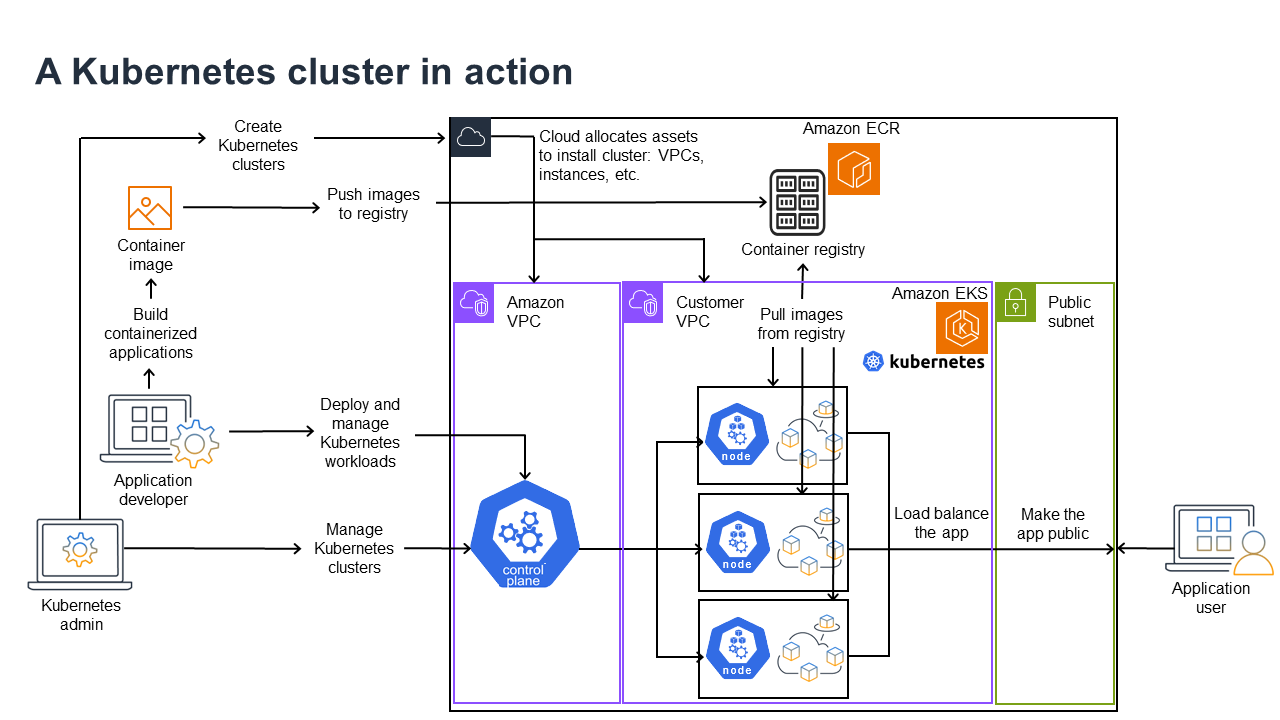
A Kubernetes Admin creates the Kubernetes cluster using a tool specific to the type of provider on which the cluster will be built. This example uses the Amazon cloud as the provider, which offers the managed Kubernetes service called Amazon EKS. The managed service automatically allocates the resources needed to create the cluster, including creating two new Virtual Private Clouds (Amazon VPCs) for the cluster, setting up networking, and mapping Kubernetes permissions directly into the new VPCs for cloud asset management. The managed service also sees that the control plane services have places to run and allocates zero or more Amazon EC2 instances as Kubernetes nodes for running workloads. Amazon manages one Amazon VPC itself for the control plane, while the other Amazon VPC contains the customer nodes that run workloads.
Many of the Kubernetes Admin’s tasks going forward are done using Kubernetes tools such as kubectl. That tool makes requests for services directly to the cluster’s control plane. The ways that queries and changes are made to the cluster are then very similar to the ways you would do them on any Kubernetes cluster.
An application developer wanting to deploy workloads to this cluster can perform several tasks. The developer needs to build the application into one or more container images, then push those images to a container registry that is accessible to the Kubernetes cluster. Amazon offers the Amazon Elastic Container Registry (Amazon ECR) for that purpose.
To run the application, the developer can create YAML-formatted configuration files that tell the cluster how to run the application, including which containers to pull from the registry and how to wrap those containers in Pods. The control plane (scheduler) schedules the containers to one or more nodes and the container runtime on each node actually pulls and runs the needed containers. The developer can also set up an application load balancer to balance traffic to available containers running on each node and expose the application so it is available on a public network to the outside world. With that all done, someone wanting to use the application can connect to the application endpoint to access it.
The following sections go through details of each of these features, from the perspective of Kubernetes Clusters and Workloads.
Clusters
If your job is to start and manage Kubernetes clusters, you should know how Kubernetes clusters are created, enhanced, managed, and deleted. You should also know what the components are that make up a cluster and what you need to do to maintain those components.
Tools for managing clusters handle the overlap between the Kubernetes services and the underlying hardware provider. For that reason, automation of these tasks tends to be done by the Kubernetes provider (such as Amazon EKS or Amazon EKS Anywhere) using tools that are specific to the provider. For example, to start an Amazon EKS cluster you can use eksctl create cluster, while for Amazon EKS Anywhere you can use eksctl anywhere create cluster. Note that while these commands create a Kubernetes cluster, they are specific to the provider and are not part of the Kubernetes project itself.
Cluster creation and management tools
The Kubernetes project offers tools for creating a Kubernetes cluster manually. So if you want to install Kubernetes on a single machine, or run the control plane on a machine and add nodes manually, you can use CLI tools like kind
In Amazon Cloud, you can create Amazon EKS clusters using CLI tools, such as eksctl
-
Managed control plane — Amazon makes sure that the Amazon EKS cluster is available and scalable because it manages the control plane for you and makes it available across Amazon Availability Zones.
-
Node management — Instead of manually adding nodes, you can have Amazon EKS create nodes automatically as needed, using Managed Node Groups (see Simplify node lifecycle with managed node groups) or Karpenter
. Managed Node Groups have integrations with Kubernetes Cluster Autoscaling . Using node management tools, you can take advantage of cost savings, with things like Spot Instances and node consolidation, and availability, using Scheduling features to set how workloads are deployed and nodes are selected. -
Cluster networking — Using CloudFormation templates,
eksctlsets up networking between control plane and data plane (node) components in the Kubernetes cluster. It also sets up endpoints through which internal and external communications can take place. See De-mystifying cluster networking for Amazon EKS worker nodesfor details. Communications between Pods in Amazon EKS is done using Amazon EKS Pod Identities (see Learn how EKS Pod Identity grants pods access to Amazon services), which provides a means of letting Pods tap into Amazon cloud methods of managing credentials and permissions. -
Add-Ons — Amazon EKS saves you from having to build and add software components that are commonly used to support Kubernetes clusters. For example, when you create an Amazon EKS cluster from the Amazon Web Services Management Console, it automatically adds the Amazon EKS kube-proxy (Manage kube-proxy in Amazon EKS clusters), Amazon VPC CNI plugin for Kubernetes (Assign IPs to Pods with the Amazon VPC CNI), and CoreDNS (Manage CoreDNS for DNS in Amazon EKS clusters) add-ons. See Amazon EKS add-ons for more on these add-ons, including a list of which are available.
To run your clusters on your own on-premises computers and networks, Amazon offers Amazon EKS Anywhere
Amazon EKS Anywhere is based on the same Amazon EKS Distroetcd later in this document).
Cluster components
Kubernetes cluster components are divided into two major areas: control plane and worker nodes. Control Plane Components
Control plane
The control plane consists of a set of services that manage the cluster. These services may all be running on a single computer or may be spread across multiple computers. Internally, these are referred to as Control Plane Instances (CPIs). How CPIs are run depends on the size of the cluster and requirements for high availability. As demand increases in the cluster, a control plane service can scale to provide more instances of that service, with requests being load balanced between the instances.
Tasks that components of the Kubernetes control plane perform include:
-
Communicating with cluster components (API server) — The API server (kube-apiserver
) exposes the Kubernetes API so requests to the cluster can be made from both inside and outside of the cluster. In other words, requests to add or change a cluster’s objects (Pods, Services, Nodes, and so on) can come from outside commands, such as requests from kubectlto run a Pod. Likewise, requests can be made from the API server to components within the cluster, such as a query to thekubeletservice for the status of a Pod. -
Store data about the cluster (
etcdkey value store) — Theetcdservice provides the critical role of keeping track of the current state of the cluster. If theetcdservice became inaccessible, you would be unable to update or query the status of the cluster, though workloads would continue to run for a while. For that reason, critical clusters typically have multiple, load-balanced instances of theetcdservice running at a time and do periodic backups of theetcdkey value store in case of data loss or corruption. Keep in mind that, in Amazon EKS, this is all handled for you automatically by default. Amazon EKS Anywhere provides instruction for etcd backup and restore. See the etcd Data Model to learn how etcdmanages data. -
Schedule Pods to nodes (Scheduler) — Requests to start or stop a Pod in Kubernetes are directed to the Kubernetes Scheduler
(kube-scheduler ). Because a cluster could have multiple nodes that are capable of running the Pod, it is up to the Scheduler to choose which node (or nodes, in the case of replicas) the Pod should run on. If there is not enough available capacity to run the requested Pod on an existing node, the request will fail, unless you have made other provisions. Those provisions could include enabling services such as Managed Node Groups (Simplify node lifecycle with managed node groups) or Karpenter that can automatically start up new nodes to handle the workloads. -
Keep components in desired state (Controller Manager) — The Kubernetes Controller Manager runs as a daemon process (kube-controller-manager
) to watch the state of the cluster and make changes to the cluster to reestablish the expected states. In particular, there are several controllers that watch over different Kubernetes objects, which includes a statefulset-controller,endpoint-controller,cronjob-controller,node-controller, and others. -
Manage cloud resources (Cloud Controller Manager) — Interactions between Kubernetes and the cloud provider that carries out requests for the underlying data center resources are handled by the Cloud Controller Manager
(cloud-controller-manager ). Controllers managed by the Cloud Controller Manager can include a route controller (for setting up cloud network routes), service controller (for using cloud load balancing services), and node lifecycle controller (to keep nodes in sync with Kubernetes throughout their lifecycles).
Worker Nodes (data plane)
For a single-node Kubernetes cluster, workloads run on the same machine as the control plane. However, a more standard configuration is to have one or more separate computer systems (Nodes
When you first create a Kubernetes cluster, some cluster creation tools allow you to configure a certain number nodes to be added to the cluster (either by identifying existing computer systems or by having the provider create new ones). Before any workloads are added to those systems, services are added to each node to implement these features:
-
Manage each node (
kubelet) — The API server communicates with the kubeletservice running on each node to make sure that the node is properly registered and Pods requested by the Scheduler are running. The kubelet can read the Pod manifests and set up storage volumes or other features needed by the Pods on the local system. It can also check on the health of the locally running containers. -
Run containers on a node (container runtime) — The Container Runtime
on each node manages the containers requested for each Pod assigned to the node. That means that it can pull container images from the appropriate registry, run the container, stop it, and respond to queries about the container. The default container runtime is containerd . As of Kubernetes 1.24, the special integration of Docker ( dockershim) that could be used as the container runtime was dropped from Kubernetes. While you can still use Docker to test and run containers on your local system, to use Docker with Kubernetes you would now have to Install Docker Engineon each node to use it with Kubernetes. -
Manage networking between containers (
kube-proxy) — To be able to support communication between Pods, Kubernetes uses a feature referred to as a Serviceto set up Pod networks that track IP addresses and ports associated with those Pods. The kube-proxy service runs on every node to allow that communication between Pods to take place.
Extend Clusters
There are some services you can add to Kubernetes to support the cluster, but are not run in the control plane. These services often run directly on nodes in the kube-system namespace or in its own namespace (as is often done with third-party service providers). A common example is the CoreDNS service, which provides DNS services to the cluster. Refer to Discovering builtin services
There are different types of add-ons you can consider adding to your clusters. To keep your clusters healthy, you can add observability features (see Monitor your cluster performance and view logs) that allow you to do things like logging, auditing, and metrics. With this information, you can troubleshoot problems that occur, often through the same observability interfaces. Examples of these types of services include Amazon GuardDuty, CloudWatch (see Monitor cluster data with Amazon CloudWatch), Amazon Distro for OpenTelemetry
For a more complete list of available Amazon EKS add-ons, see Amazon EKS add-ons.
Workloads
Kubernetes defines a Workload
Containers
The most basic element of an application workload that you deploy and manage in Kubernetes is a
Pod
Because the Pod is the smallest deployable unit, it typically holds a single container. However, multiple containers can be in a Pod in cases where the containers are tightly coupled. For example, a web server container might be packaged in a Pod with a sidecar
Pod specifications (PodSpec
While a Pod is the smallest unit you deploy, a container is the smallest unit that you build and manage.
Building Containers
The Pod is really just a structure around one or more containers, with each container itself holding the file system, executables, configuration files, libraries, and other components to actually run the application. Because a company called Docker Inc. first popularized containers, some people refer to containers as Docker Containers. However, the Open Container Initiative
When you build a container, you typically start with a Dockerfile (literally named that). Inside that Dockerfile, you identify:
-
A base image — A base container image is a container that is typically built from either a minimal version of an operating system’s file system (such as Red Hat Enterprise Linux
or Ubuntu ) or a minimal system that is enhanced to provide software to run specific types of applications (such as a nodejs or python apps). -
Application software — You can add your application software to your container in much the same way you would add it to a Linux system. For example, in your Dockerfile you can run
npmandyarnto install a Java application oryumanddnfto install RPM packages. In other words, using a RUN command in a Dockerfile, you can run any command that is available in the file system of your base image to install software or configure software inside of the resulting container image. -
Instructions — The Dockerfile reference
describes the instructions you can add to a Dockerfile when you configure it. These include instructions used to build what is in the container itself ( ADDorCOPYfiles from the local system), identify commands to execute when the container is run (CMDorENTRYPOINT), and connect the container to the system it runs on (by identifying theUSERto run as, a localVOLUMEto mount, or the ports toEXPOSE).
While the docker command and service have traditionally been used to build containers (docker build), other tools that are available to build container images include podman
Storing Containers
Once you’ve built your container image, you can store it in a container distribution registry
To store container images in a more public manner, you can push them to a public container registry. Public container registries provide a central location for storing and distributing container images. Examples of public container registries include the Amazon Elastic Container Registry
When running containerized workloads on Amazon Elastic Kubernetes Service (Amazon EKS) we recommend pulling copies of Docker Official Images that are stored in Amazon Elastic Container Registry. Amazon ECR has been storing these images since 2021. You can search for popular container images in the Amazon ECR Public Gallery
Running containers
Because containers are built in a standard format, a container can run on any machine that can run a container runtime (such as Docker) and whose contents match the local machine’s architecture (such as x86_64 or arm). To test a container or just run it on your local desktop, you can use docker run or podman run commands to start up a container on the localhost. For Kubernetes, however, each worker node has a container runtime deployed and it is up to Kubernetes to request that a node run a container.
Once a container has been assigned to run on a node, the node looks to see if the requested version of the container image already exists on the node. If it doesn’t, Kubernetes tells the container runtime to pull that container from the appropriate container registry, then run that container locally. Keep in mind that a container image refers to the software package that is moved around between your laptop, the container registry, and Kubernetes nodes. A container refers to a running instance of that image.
Pods
Once your containers are ready, working with Pods includes configuring, deploying, and making the Pods accessible.
Configuring Pods
When you define a Pod, you assign a set of attributes to it. Those attributes must include at least the Pod name and the container image to run. However, there are many other things you want to configure with your Pod definitions as well (see the PodSpec
-
Storage — When a running container is stopped and deleted, data storage in that container will disappear, unless you set up more permanent storage. Kubernetes supports many different storage types and abstracts them under the umbrella of Volumes
. Storage types include CephFS , NFS , iSCSI , and others. You can even use a local block device from the local computer. With one of those storage types available from your cluster, you can mount the storage volume to a selected mount point in your container’s file system. A Persistent Volume is one that continues to exist after the Pod is deleted, while an Ephemeral Volume is deleted when the Pod is deleted. If your cluster administrator created different storage classes for your cluster, you might have the option for choosing the attributes of the storage you use, such as whether the volume is deleted or reclaimed after use, whether it will expand if more space is needed, and even whether it meets certain performance requirements. -
Secrets — By making Secrets
available to containers in Pod specs, you can provide the permissions those containers need to access file systems, databases, or other protected assets. Keys, passwords, and tokens are among the items that can be stored as secrets. Using secrets makes it so you don’t have to store this information in container images, but need only make the secrets available to running containers. Similar to Secrets are ConfigMaps . A ConfigMaptends to hold less critical information, such as key-value pairs for configuring a service. -
Container resources — Objects for further configuring containers can take the form of resource configuration. For each container, you can request the amount of memory and CPU that it can use, as well as place limits of the total amount of those resources that the container can use. See Resource Management for Pods and Containers
for examples. -
Disruptions — Pods can be disrupted involuntarily (a node goes down) or voluntarily (an upgrade is desired). By configuring a Pod disruption budget
, you can exert some control over how available your application remains when disruptions occur. See Specifying a Disruption Budget for your application for examples. -
Namespaces — Kubernetes provides different ways to isolate Kubernetes components and workloads from each other. Running all the Pods for a particular application in the same Namespace
is a common way to secure and manage those Pods together. You can create your own namespaces to use or choose to not indicate a namespace (which causes Kubernetes to use the defaultnamespace). Kubernetes control plane components typically run in the kube-systemnamespace.
The configuration just described is typically gathered together in a YAML file to be applied to the Kubernetes cluster. For personal Kubernetes clusters, you might just store these YAML files on your local system. However, with more critical clusters and workloads, GitOps
The objects used to gather together and deploy Pod information is defined by one of the following deployment methods.
Deploying Pods
The method you would choose for deploying Pods depends on the type of application you plan to run with those Pods. Here are some of your choices:
-
Stateless applications — A stateless application doesn’t save a client’s session data, so another session doesn’t need to refer back to what happened to a previous session. This makes it easier to just replace Pods with new ones if they become unhealthy or move them around without saving state. If you are running a stateless application (such as a web server), you can use a Deployment
to deploy Pods and ReplicaSets . A ReplicaSet defines how many instances of a Pod that you want running concurrently. Although you can run a ReplicaSet directly, it is common to run replicas directly within a Deployment, to define how many replicas of a Pod should be running at a time. -
Stateful applications — A stateful application is one where the identity of the Pod and the order in which Pods are launched are important. These applications need persistent storage that is stable and need to be deployed and scaled in a consistent manner. To deploy a stateful application in Kubernetes, you can use StatefulSets
. An example of an application that is typically run as a StatefulSet is a database. Within a StatefulSet, you could define replicas, the Pod and its containers, storage volumes to mount, and locations in the container where data are stored. See Run a Replicated Stateful Application for an example of a database being deployed as a ReplicaSet. -
Per-node applications — There are times when you want to run an application on every node in your Kubernetes cluster. For example, your data center might require that every computer run a monitoring application or a particular remote access service. For Kubernetes, you can use a DaemonSet
to ensure that the selected application runs on every node in your cluster. -
Applications run to completion — There are some applications you want to run to complete a particular task. This could include one that runs monthly status reports or cleans out old data. A Job
object can be used to set up an application to start up and run, then exit when the task is done. A CronJob object lets you set up an application to run at a specific hour, minute, day of the month, month, or day of the week, using a structure defined by the Linux crontab format.
Making applications accessible from the network
With applications often deployed as a set of microservices that move around to different places, Kubernetes needed a way for those microservices to be able to find each other. Also, for others to access an application outside of the Kubernetes cluster, Kubernetes needed a way to expose that application on outside addresses and ports. These networking-related features are done with Service and Ingress objects, respectively:
-
Services — Because a Pod can move around to different nodes and addresses, another Pod that needs to communicate with the first Pod could find it difficult to locate where it is. To solve this problem, Kubernetes lets you represent an application as a Service
. With a Service, you can identify a Pod or set of Pods with a particular name, then indicate what port exposes that application’s service from the Pod and what ports another application could use to contact that service. Another Pod within a cluster can simply request a Service by name and Kubernetes will direct that request to the proper port for an instance of the Pod running that service. -
Ingress — Ingress
is what can make applications represented by Kubernetes Services available to clients that are outside of the cluster. Basic features of Ingress include a load balancer (managed by Ingress), the Ingress controller, and rules for routing requests from the controller to the Service. There are several Ingress Controllers that you can choose from with Kubernetes.
Next steps
Understanding basic Kubernetes concepts and how they relate to Amazon EKS will help you navigate both the Amazon EKS documentation and Kubernetes documentation