How job configurations work
You use the rollout and abort configurations when you're deploying a job, and the timeout and retry configurations for job execution. The following sections show more information about how these configurations work.
Topics
Job rollout, scheduling, and abort configurations
You can use the job rollout, scheduling, and abort configurations to define how many devices receive the job document, schedule a job rollout, and determine the criteria for canceling a job.
You can specify how quickly targets are notified of a pending job execution. You can also create a staged rollout to manage updates, reboots, and other operations. To specify how your targets are notified, use job rollout rates.
Job rollout rates
You can create a rollout configuration by using either a constant rollout rate or an exponential rollout rate. To specify the maximum number of job targets to inform per minute, use a constant rollout rate.
Amazon IoT jobs can be deployed using exponential rollout rates as various
criteria and thresholds are met. If the number of failed jobs matches a
set of criteria that you specify, then you can cancel the job rollout.
You set the job rollout rate criteria when you create a job by using the
JobExecutionsRolloutConfig object. You
also set the job abort criteria at job creation by using the AbortConfig object.
The following example shows how rollout rates work. For example, a job rollout with a base rate of 50 per minute, increment factor of 2, and number of notified and succeeded devices each as 1,000, would work as follows: The job will start at a rate of 50 job executions per minute and continue at that rate until either 1,000 things have received job execution notifications, or 1,000 successful job executions have occurred.
The following table illustrates how the rollout would proceed over the first four increments.
|
Rollout rate per minute |
50 |
100 |
200 |
400 |
|
Number of notified devices or successful job executions to satisfy a rate increase |
1,000 |
2,000 |
3,000 |
4,000 |
Note
If you're at your max concurrent limit of 500 Jobs
(isConcurrent = True), then all active jobs will
remain with a status of IN-PROGRESS and not roll out
any new job executions until the number of concurrent jobs is 499 or
less (isConcurrent = False). This applies to snapshot
and continuous jobs.
If isConcurrent = True, the job is currently rolling
out job executions to all devices in your target group. If
isConcurrent = False, the job has completed the
rollout of all job executions to all devices in your target group.
It will update its status state once all devices in your target
group reach a terminal state, or a threshold percentage of your
target group if you selected a job abort configuration. The Job
level status states for isConcurrent = True and
isConcurrent = False are both
IN_PROGRESS.
For more information about active and concurrent job limits, see Active and concurrent job limits.
Job rollout rates for continuous jobs using dynamic thing groups
When you use a continuous job to roll out remote operations on your fleet, Amazon IoT Jobs rolls out job executions for devices in your target thing group. For new devices that are added to the dynamic thing group, these job executions continue to roll out to those devices even after the job has been created.
The rollout configuration can control the rollout rates only for devices that are added to the group until job creation. After a job has been created, for any new devices, the job executions are created in near real time as soon as the devices join the target group.
You can schedule a continuous or snapshot job up to a year in advance using a pre-determined start time, end time, and end behavior for what will happen to each job execution upon reaching the end time. Additionally, you can create an optional recurring maintenance window with a flexible frequency, start time, and duration for continuous jobs to roll out a job document to all devices within the target group.
Job scheduling configurations
Start time
The start time of a scheduled job is the future date and time that job
will begin rollout of the job document to all devices in the target
group. Start time for a scheduled job applies to continuous jobs and
snapshot jobs. When a scheduled job is initially created, it maintains a
status state of SCHEDULED. Upon arriving at the
startTime that you selected, it updates to
IN_PROGRESS and begins the job document rollout. The
startTime must be less than or equal to one year from
the initial date and time that you created the scheduled job.
For more information on the syntax for startTime when
using an API command or the Amazon CLI, see Timestamp.
For a job with the optional scheduling configuration that takes place during a recurring maintenance window in a location observing daylight savings time (DST), the time will change by one hour when switching from DST to standard time and from standard time to DST.
Note
The time zone displayed in the Amazon Web Services Management Console is your current system time zone. However, these time zones will be converted into UTC in the system.
End time
The end time of a scheduled job is the future date and time that the
job will stop rollout of the job document to any remaining devices in
the target group. End time for a scheduled job applies to continuous
jobs and snapshot jobs. After a scheduled job arrives at the selected
endTime, and all job executions have reached a terminal
state, it updates its status state from IN_PROGRESS to
COMPLETED. The endTime must be less than
or equal to two years from the initial date and time that you created
the scheduled job. The minimum duration between startTime
and endTime is 30 minutes. Job execution retry attempts
will occur until the job reaches the endTime, then the
endBehavior will dictate how to proceed.
For more information on the syntax for endTime when using
an API command or the Amazon CLI, see Timestamp.
For a job with the optional scheduling configuration that takes place during a recurring maintenance window in a location observing daylight savings time (DST), the time will change by one hour when switching from DST to standard time and from standard time to DST.
Note
The time zone displayed in the Amazon Web Services Management Console is your current system time zone. However, these time zones will be converted into UTC in the system.
End behavior
The end behavior of a scheduled job determines what happens to the job
and all unfinished job executions when the job reaches the selected
endTime.
The following lists the end behaviors that you can select from when creating the job or job template:
-
STOP_ROLLOUT-
STOP_ROLLOUTstops the rollout of the job document to all remaining devices in the target group for the job. Additionally, allQUEUEDandIN_PROGRESSjob executions will continue until they reach a terminal state. This is the default end behavior unless you selectCANCELorFORCE_CANCEL.
-
-
CANCEL-
CANCELstops the rollout of the job document to all remaining devices in the target group for the job. Additionally, allQUEUEDjob executions will be cancelled while allIN_PROGRESSjob executions will continue until they reach a terminal state.
-
-
FORCE_CANCEL-
FORCE_CANCELstops the rollout of the job document to all remaining devices in the target group for the job. Additionally, allQUEUEDandIN_PROGRESSjob executions will be cancelled.
-
Note
To select an endbehavior, you must select an endtime
Max duration
The max duration of a scheduled job must be less than or equal to two
years regardless of the startTime and endTime.
The following table lists common duration scenarios of a scheduled job:
| Scheduled Job example number | startTime | endTime | Max duration |
|---|---|---|---|
|
1 |
Immediately after initial job creation. |
One year after initial job creation. |
One year |
|
2 |
One month after initial job creation. |
13 months after initial job creation. |
One year |
|
3 |
One year after initial job creation. |
Two years after initial job creation. |
One year |
|
4 |
Immediately after initial job creation. |
Two years after initial job creation. |
Two years |
Recurring maintenance window
The maintenance window is an optional configuration within the
scheduling
configuration of the Amazon Web Services Management Console and
SchedulingConfig within the CreateJob and
CreateJobTemplate APIs. You can set up a recurring
maintenance window with a predetermined start time, duration, and
frequency (daily, weekly, or monthly) that the maintenance window
occurs. Maintenance windows only apply to continuous jobs. The maximum
duration of a recurring maintenance window is 23 hours, 50
minutes.
The following diagram illustrates the job status states for various scheduled job scenarios with an optional maintenance window:
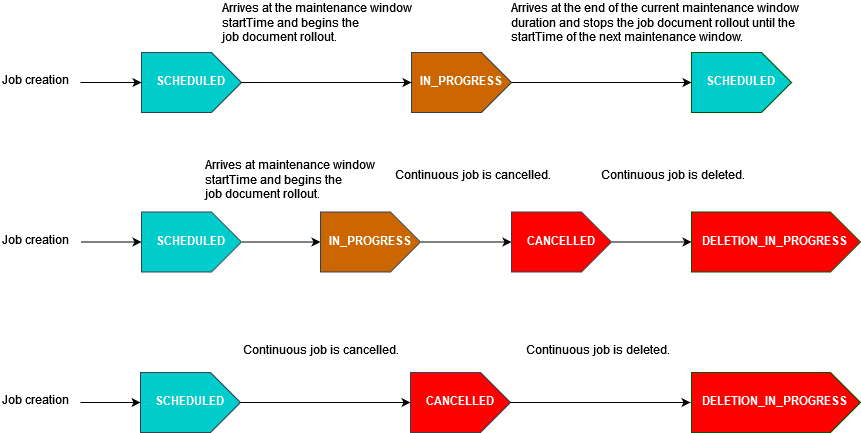
For more information about job status states, see Jobs and job execution states.
Note
If a job arrives at the endTime during a maintenance
window, it will update from IN_PROGRESS to
COMPLETED. Additionally, any remaining job
executions will follow the endBehavior for the
job.
Cron expressions
For scheduled jobs rolling out the job document during a maintenance window with a custom frequency, the custom frequency is entered using a cron expression. A cron expression has six required fields, which are separated by white space.
Syntax
cron(fields)
| Field | Values | Wildcards |
|---|---|---|
|
Minutes |
0-59 |
, - * / |
|
Hours |
0-23 |
, - * / |
|
Day-of-month |
1-31 |
, - * ? / L W |
|
Month |
1-12 or JAN-DEC |
, - * / |
|
Day-of-week |
1-7 or SUN-SAT |
, - * ? L # |
|
Year |
1970-2199 |
, - * / |
Wildcards
-
The , (comma) wildcard includes additional values. In the Month field, JAN,FEB,MAR would include January, February, and March.
-
The - (dash) wildcard specifies ranges. In the Day field, 1-15 would include days 1 through 15 of the specified month.
-
The * (asterisk) wildcard includes all values in the field. In the Hours field, * would include every hour. You can't use * in both the Day-of-month and Day-of-week fields. If you use it in one, you must use ? in the other.
-
The / (forward slash) wildcard specifies increments. In the Minutes field, you could enter 1/10 to specify every tenth minute, starting from the first minute of the hour (for example, the 11th, 21st, and 31st minute, and so on).
-
The ? (question mark) wildcard specifies one or another. In the Day-of-month field, you could enter 7 and if you didn't care what day of the week the 7th was, you could enter ? in the Day-of-week field.
-
The L wildcard in the Day-of-month or Day-of-week fields specifies the last day of the month or week.
-
The
Wwildcard in the Day-of-month field specifies a weekday. In the Day-of-month field,3Wspecifies the weekday closest to the third day of the month. -
The # wildcard in the Day-of-week field specifies a certain instance of the specified day of the week within a month. For example, 3#2 would be the second Tuesday of the month: the 3 refers to Tuesday because it is the third day of each week, and the 2 refers to the second day of that type within the month.
Note
If you use a '#' character, you can define only one expression in the day-of-week field. For example,
"3#1,6#3"isn't valid because it's interpreted as two expressions.
Restrictions
-
You can't specify the Day-of-month and Day-of-week fields in the same cron expression. If you specify a value (or a *) in one of the fields, you must use a ?in the other.
Examples
Refer to the following sample cron strings when using a cron
expression for the startTime of a recurring maintenance
window.
| Minutes | Hours | Day of month | Month | Day of week | Year | Meaning |
|---|---|---|---|---|---|---|
| 0 | 10 | * | * | ? | * |
Run at 10:00 am (UTC) every day |
| 15 | 12 | * | * | ? | * |
Run at 12:15 pm (UTC) every day |
| 0 | 18 | ? | * | MON-FRI | * |
Run at 6:00 pm (UTC) every Monday through Friday |
| 0 | 8 | 1 | * | ? | * |
Run at 8:00 am (UTC) every first day of the month |
Recurring maintenance window duration end logic
When a job rollout during a maintenance window reaches the end of the current maintenance window occurrence duration, the following actions will occur:
-
The Job will cease all rollouts of the job document to any remaining devices in your target group. It will resume at the
startTimeof the next maintenance window. -
All job executions with a status of
QUEUEDwill remain inQUEUEDuntil thestartTimeof the next maintenance window occurrence. In the next window, they can switch toIN_PROGRESSwhen the device is ready to begin performing the actions specified in the job document. -
All job executions with a status of
IN_PROGRESSwill continue performing the actions specified in the job document until they reach a terminal state. Any retry attempts as specified inJobExecutionsRetryConfigwill take place at thestartTimeof the next maintenance window.
Use this configuration to create a criteria to cancel a job when a threshold percentage of devices meet that criteria. For example, you can use this configuration to cancel a job in the following cases:
-
When a threshold percentage of devices don't receive the job execution notifications, such as when your device is incompatible for an Over-The-Air (OTA) update. In this case, your device can report a
REJECTEDstatus. -
When a threshold percentage of devices report failure for their job executions, such as when your device encounters a disconnection when attempting to download the job document from an Amazon S3 URL. In such cases, your device must be programmed to report the
FAILUREstatus to Amazon IoT. -
When a
TIMED_OUTstatus is reported because the job execution times out for a threshold percentage of devices after the job executions have started. -
When there are multiple retry failures. When you add a retry configuration, each retry attempt can incur additional charges to your Amazon Web Services account. In such cases, canceling the job can cancel queued job executions and avoid retry attempts for these executions. For more information about the retry configuration and using it with the abort configuration, see Job execution timeout and retry configurations.
You can set up a job abort condition by using the Amazon IoT console or the Amazon IoT Jobs API.
Job execution timeout and retry configurations
Use the job execution timeout configuration to send you Jobs notifications when a job execution has been in progress for longer than the set duration. Use the job execution retry configuration to retry the execution when the job fails or times out.
Use the job execution timeout configuration to notify you whenever a job
execution gets stuck in the IN_PROGRESS state for an
unexpectedly long period of time. When the job is IN_PROGRESS,
you can monitor the progress of your job execution.
Timers for job timeouts
There are two types of timers: in-progress timers and step timers.
In-progress timers
When you create a job or a job template, you can specify a value
for the in-progress timer that's between 1 minute and 7 days. You
can update the value of this timer until the start of your job
execution. After your timer starts, it can't be updated, and the
timer value applies to all job executions for the job. Whenever a
job execution remains in the IN_PROGRESS status for
longer than this interval, the job execution fails and switches to
the terminal TIMED_OUT status. Amazon IoT also publishes an
MQTT notification.
Step timer
You can also set a step timer that applies to only the job
execution that you want to update. This timer has no effect on the
in-progress timer. Each time you update a job execution, you can set
a new value for the step timer. You can also create a new step timer
when starting the next pending job execution for a thing. If the job
execution remains in the IN_PROGRESS status for longer
than the step timer interval, it fails and switches to the terminal
TIMED_OUT status.
Note
You can set the in-progress timer by using the Amazon IoT console or the Amazon IoT Jobs API. To specify the step timer, use the API.
How timers work for job timeouts
The following illustrates the ways in which in-progress timeouts and step timeouts interact with each other in a 20-minute timeout period.
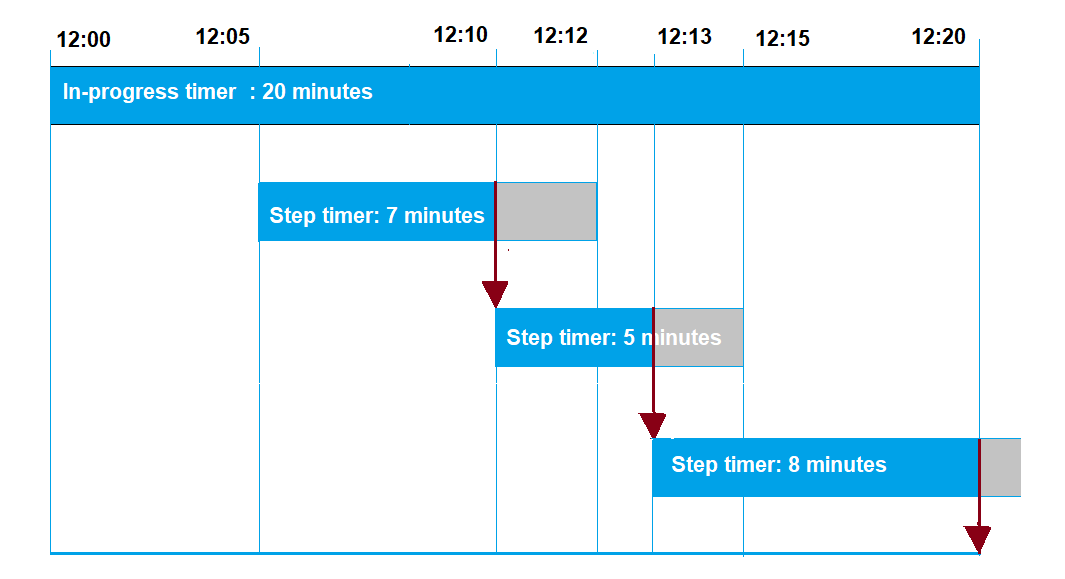
The following shows the different steps:
-
12:00
A new job is created and an in-progress timer for twenty minutes is started when creating a job. The in-progress timer starts to run and the job execution switches to
IN_PROGRESSstatus. -
12:05 PM
A new step timer with a value of 7 minutes is created. The job execution will now time out at 12:12 PM.
-
12:10 PM
A new step timer with a value of 5 minutes is created. When a new step timer is created, the previous step timer is discarded, and the job execution will now time out at 12:15 PM.
-
12:13 PM
A new step timer with a value of 9 minutes is created. The previous step timer is discarded and the job execution will now time out at 12:20 PM because the in-progress timer times out at 12:20 PM. The step timer can't exceed the in-progress timer's absolute bound.
You can use the retry configuration to retry the job execution when a certain set of criteria is met. A retry can be attempted when a job times out or when the device fails. To retry execution because of a timeout failure, you must enable the timeout configuration.
How to use the retry configuration
Use the following steps to retry the configuration:
-
Determine whether to use the retry configuration for
FAILED,TIMED_OUT, or both failure criteria. For theTIMED_OUT -
For the
FAILEDstatus, check whether your job execution failure can be retried. If it's retryable, program your device to report aFAILUREstatus to Amazon IoT. The following section describes more about retryable and non-retryable failures. -
Specify the number of retries to use for each failure type by using the preceding information. For a single device, you can specify up to 10 retries for both failure types combined. The retry attempts stop automatically when an execution succeeds or when it reaches the specified number of attempts.
-
Add an abort configuration to cancel the job if there are repeated retry failures to avoid additional charges from being incurred with a large number of retry attempts.
Note
When a job reaches the end of a recurring maintenance window occurrence, all
IN_PROGRESS job executions will continue performing
actions identified in the job document until they reach a terminal
state. If a job execution reaches a terminal state of
FAILED or TIMED_OUT outside of a
maintenance window, a retry attempt will occur in the next window if the
attempts aren't exhausted. At the startTime of the next
maintenance window occurrence, a new job execution will be created and
enter a status state of QUEUED until the device is ready to
begin.
Retry and abort configuration
Each retry attempt incurs additional charges to your Amazon Web Services account. To
avoid incurring additional charges from repeated retry failures, we
recommend adding an abort configuration. For more information about
pricing, see Amazon IoT Device Management
pricing
You might encounter multiple retry failures when a high threshold percentage of your devices either time out or report failure. In this case, you can use the abort configuration to cancel the job and avoid any queued job executions or further retry attempts.
Note
When the abort criteria is met for canceling a job execution, only
QUEUED job executions are canceled. Any queued retries
for the device will not be attempted. However, current job executions
that have an IN_PROGRESS status will not be
canceled.
Before retrying a failed job execution, we also recommend that you check whether your job execution failure is retryable, as described in the following section.
Retry for failure type of FAILED
To attempt retries for failure type of FAILED, your
devices must be programmed to report the FAILURE status for
a failed job execution to Amazon IoT. Set the retry configuration with the
criteria to retry FAILED job executions and specify the
number of retries to be performed. When Amazon IoT Jobs detects the
FAILURE status, it will then automatically attempt to
retry the job execution for the device. The retries continue until the
job execution succeeds or when it reaches the maximum number of retry
attempts.
You can track each retry attempt and the job that's running on these devices. By tracking the execution status, after the specified number of retries have been attempted, you can use your device to report failures and initiate another retry attempt.
Retryable and non-retryable failures
Your job execution failure can be retryable or non-retryable. Each
retry attempt can incur charges to your Amazon Web Services account. To avoid
incurring additional charges from multiple retry attempts, first
consider checking whether your job execution failure is retryable. An
example of retryable failure includes a connection error that your
device encounters while attempting to download the job document from an
Amazon S3 URL. If your job execution failure is retryable,
program your device to report a FAILURE status in case the
job execution fails. Then, set the retry configuration to retry
FAILED executions.
If the execution can't be retried, to avoid retrying and potentially
incurring additional charges to your account, we recommend that you program
the device to report a REJECTED status to Amazon IoT. Examples of
non-retryable failure include when your device is
incompatible
of receiving a job update, or when it experiences a memory error while
executing a job. In these cases, Amazon IoT Jobs will not retry the job execution
because it retries the job execution only when it detects a
FAILED or TIMED_OUT status.
After you've determined that a job execution failure is retryable, if a retry attempt still fails, consider checking the device logs.
Note
When a job with the optional scheduling configuration reaches its
endTime, the selected endBehavior will
stop the rollout of the job document to all remaining devices in the
target group and dictate how to proceed with the remaining job
executions. The attempts are retried if selected via the retry
configuration.
Retry for failure type of TIMEOUT
If you enable timeout when creating a job, then Amazon IoT Jobs will
attempt to retry the job execution for the device when the status
changes from IN_PROGRESS to TIMED_OUT. This
status change can occur when the in-progress timer times out, or when a
step timer that you specify is in IN_PROGRESS and then
times out. The retries continue until the job execution succeeds, or
when it reaches the maximum number of retry attempts for this failure
type.
Continuous jobs and thing group membership updates
For continuous jobs that have a job status as
IN_PROGRESS, the number of retry attempts is reset to zero
when there are updates to a thing's group membership. For example,
consider that you specified five retry attempts and three retries have
already been performed. If a thing is now removed from the thing group
and then rejoins the group, such as with dynamic thing groups, the
number of retry attempts is reset to zero. You can now perform five
retry attempts for your thing group instead of the two attempts that
were remaining. In addition, when a thing is removed from the thing
group, additional retry attempts are canceled.