Monitoring OpenSearch cluster metrics with Amazon CloudWatch
Amazon OpenSearch Service publishes data from your domains to Amazon CloudWatch. CloudWatch lets you retrieve statistics
about those data points as an ordered set of time-series data, known as metrics. OpenSearch Service sends most metrics to CloudWatch in 60-second
intervals. If you use General Purpose or Magnetic EBS volumes, the EBS volume metrics update
only every five minutes. All cumulative metrics (e.g. ThreadpoolWriteRejected,
ThreadpoolSearchRejected) are in-memory and will lose state. Metrics will
reset during a node drop, node bounce, node replacement, and blue/green deployment. For more
information about Amazon CloudWatch, see the Amazon CloudWatch User Guide.
The OpenSearch Service console displays a series of charts based on the raw data from CloudWatch. Depending on
your needs, you might prefer to view cluster data in CloudWatch instead of the graphs in the
console. The service archives metrics for two weeks before discarding them. The metrics are
provided at no extra charge, but CloudWatch still charges for creating dashboards and alarms. For
more information, see Amazon CloudWatch
pricing
OpenSearch Service publishes the following metrics to CloudWatch:
Viewing metrics in CloudWatch
CloudWatch metrics are grouped first by the service namespace, and then by the various dimension combinations within each namespace.
To view metrics using the CloudWatch console
-
Open the CloudWatch console at https://console.aws.amazon.com/cloudwatch/
. -
In the left navigation pane, find Metrics and choose All metrics. Select the ES namespace.
-
Choose a dimension to view the corresponding metrics. Metrics for individual nodes are in the
ClientId, DomainName, NodeIddimension. Cluster metrics are in thePer-Domain, Per-Client Metricsdimension. Some node metrics are aggregated at the cluster level and thus included in both dimensions. Shard metrics are in theClientId, DomainName, NodeId, ShardRoledimension.
To view a list of metrics using the Amazon CLI
Run the following command:
aws cloudwatch list-metrics --namespace "AWS/ES"
Interpreting health charts in OpenSearch Service
To view metrics in OpenSearch Service, use the Cluster health and Instance health tabs. The Instance health tab uses box charts to provide at-a-glance visibility into the health of each OpenSearch node:
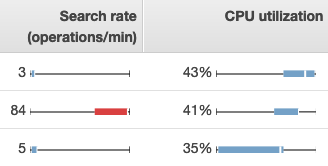
-
Each colored box shows the range of values for the node over the specified time period.
-
Blue boxes represent values that are consistent with other nodes. Red boxes represent outliers.
-
The white line within each box shows the node's current value.
-
The “whiskers” on either side of each box show the minimum and maximum values for all nodes over the time period.
If you make configuration changes to your domain, the list of individual instances in the Cluster health and Instance health tabs often double in size for a brief period before returning to the correct number. For an explanation of this behavior, see Making configuration changes in Amazon OpenSearch Service.
Cluster metrics
Amazon OpenSearch Service provides the following metrics for clusters.
| Metric | Description |
|---|---|
ClusterStatus.green |
A value of 1 indicates that all index shards are allocated to nodes in the cluster. Relevant statistics: Maximum |
ClusterStatus.yellow |
A value of 1 indicates that the primary shards for all indexes are
allocated to nodes in the cluster, but replica shards for at least one
index are not. For more information, see Yellow cluster status. Relevant statistics: Maximum |
ClusterStatus.red |
A value of 1 indicates that the primary and replica shards for at least one index are not allocated to nodes in the cluster. For more information, see Red cluster status. Relevant statistics: Maximum |
Shards.active |
The total number of active primary and replica shards. Relevant statistics: Maximum, Sum |
Shards.unassigned |
The number of shards that are not allocated to nodes in the cluster. Relevant statistics: Maximum, Sum |
Shards.delayedUnassigned |
The number of shards whose node allocation has been delayed by the timeout settings. Relevant statistics: Maximum, Sum |
Shards.activePrimary |
The number of active primary shards. Relevant statistics: Maximum, Sum |
Shards.initializing |
The number of shards that are under initialization. Relevant statistics: Sum |
Shards.relocating |
The number of shards that are under relocation. Relevant statistics: Sum |
Nodes |
The number of nodes in the OpenSearch Service cluster, including dedicated master nodes and Warm nodes. For more information, see Making configuration changes in Amazon OpenSearch Service. Relevant statistics: Maximum |
SearchableDocuments |
The total number of searchable documents across all data nodes in the cluster. Relevant statistics: Minimum, Maximum, Average |
DeletedDocuments |
The total number of documents marked for deletion across all data nodes in the cluster. These documents no longer appear in search results, but OpenSearch only removes deleted documents from disk during segment merges. This metric increases after delete requests and decreases after segment merges. Relevant statistics: Minimum, Maximum, Average |
CPUUtilization |
The percentage of CPU usage for data nodes in the cluster. Maximum shows the node with the highest CPU usage. Average represents all nodes in the cluster. This metric is also available for individual nodes. Relevant statistics: Maximum, Average |
FreeStorageSpace |
The free space for data nodes in the cluster. The OpenSearch Service console displays this value in GiB. The Amazon CloudWatch console displays it in MiB. Note
Relevant statistics: Minimum, Maximum, Average, Sum |
ClusterUsedSpace |
The total used space for the cluster. You must leave the period at one minute to get an accurate value. The OpenSearch Service console displays this value in GiB. The Amazon CloudWatch console displays it in MiB. Relevant statistics: Minimum, Maximum |
ClusterIndexWritesBlocked |
Indicates whether your cluster is accepting or blocking incoming write requests. A value of 0 means that the cluster is accepting requests. A value of 1 means that it is blocking requests. Some common factors include the following:
Relevant statistics: Maximum |
JVMMemoryPressure |
The maximum percentage of the Java heap used for all data nodes in the cluster. OpenSearch Service uses half of an instance's RAM for the Java heap, up to a heap size of 32 GiB. You can scale instances vertically up to 64 GiB of RAM, at which point you can scale horizontally by adding instances. See Recommended CloudWatch alarms for Amazon OpenSearch Service. Relevant statistics: Maximum NoteThe logic for this metric changed in service software R20220323. For more information, see the release notes. |
OldGenJVMMemoryPressure |
The maximum percentage of the Java heap used for the "old generation" on all data nodes in the cluster. This metric is also available at the node level. Relevant statistics: Maximum |
AutomatedSnapshotFailure |
The number of failed automated snapshots for the cluster. A value
of Relevant statistics: Minimum, Maximum |
CPUCreditBalance |
The remaining CPU credits available for data nodes in the cluster. A CPU credit provides the performance of a full CPU core for one minute. For more information, see CPU credits in the Amazon EC2 Developer Guide. This metric is available only for the T2 instance types. Relevant statistics: Minimum |
OpenSearchDashboardsHealthyNodes |
A health check for OpenSearch Dashboards. If the minimum, maximum, and average are all equal to 1, Dashboards is behaving normally. If you have 10 nodes with a maximum of 1, minimum of 0, and average of 0.7, this means 7 nodes (70%) are healthy and 3 nodes (30%) are unhealthy. Relevant statistics: Minimum, Maximum, Average |
OpensearchDashboardsReportingFailedRequestSysErrCount |
The number of requests to generate OpenSearch Dashboards reports that failed due to server problems or feature limitations. Relevant statistics: Sum |
OpensearchDashboardsReportingFailedRequestUserErrCount |
The number of requests to generate OpenSearch Dashboards reports that failed due to client issues. Relevant statistics: Sum |
OpensearchDashboardsReportingRequestCount |
The total number of requests to generate OpenSearch Dashboards reports. Relevant statistics: Sum |
OpensearchDashboardsReportingSuccessCount |
The number of successful requests to generate OpenSearch Dashboards reports. Relevant statistics: Sum |
KMSKeyError |
A value of 1 indicates that the Amazon KMS key used to encrypt data at rest has been disabled. To restore the domain to normal operations, re-enable the key. The console displays this metric only for domains that encrypt data at rest. Relevant statistics: Minimum, Maximum |
KMSKeyInaccessible |
A value of 1 indicates that the Amazon KMS key used to encrypt data at rest has been deleted or revoked its grants to OpenSearch Service. You can't recover domains that are in this state. If you have a manual snapshot, though, you can use it to migrate the domain's data to a new domain. The console displays this metric only for domains that encrypt data at rest. Relevant statistics: Minimum, Maximum |
InvalidHostHeaderRequests |
The number of HTTP requests made to the OpenSearch cluster that included an invalid (or missing) host header. Valid requests include the domain hostname as the host header value. OpenSearch Service rejects invalid requests for public access domains that don't have a restrictive access policy. We recommend applying a restrictive access policy to all domains. If you see large values for this metric, confirm that your OpenSearch clients include the domain hostname (and not, for example, its IP address) in their requests. Relevant statistics: Sum |
OpenSearchRequests (previously
ElasticsearchRequests) |
The number of requests made to the OpenSearch cluster. Relevant statistics: Sum |
TLSNegotiationError |
The number of failed TLS handshake attempts between clients and the domain endpoint. This metric increments when a client attempts to connect using an unsupported TLS version or cipher suite. Relevant statistics: Sum |
2xx, 3xx, 4xx, 5xx |
The number of requests to the domain that resulted in the given HTTP response code (2xx, 3xx, 4xx, 5xx). Relevant statistics: Sum |
ThroughputThrottle |
Indicates whether or not disks have been throttled. Throttling
occurs when the combined throughput of
For information on instance throughput, see Amazon EBS–optimized
instances. For information on volume throughput, see
Amazon EBS volume
types Relevant statistics: Minimum, Maximum |
IopsThrottle |
Indicates whether or not the number of input/output operations per second (IOPS) on the domain have been throttled. Throttling occurs when IOPS of the data node breach the maximum allowed limit of the EBS volume or the EC2 instance of the data node. For information on instance IOPS, see Amazon EBS–optimized
instances. For information on volume IOPS, see Amazon EBS volume
types Relevant statistics: Minimum, Maximum |
HighSwapUsage |
A value of 1 indicates that swapping due to page faults has potentially caused spikes in underlying disk usage during a specific time period. Relevant statistics: Maximum |
Dedicated master node metrics
Amazon OpenSearch Service provides the following metrics for dedicated master nodes.
| Metric | Description |
|---|---|
MasterCPUUtilization |
The maximum percentage of CPU resources used by the dedicated master nodes. We recommend increasing the size of the instance type when this metric reaches 60 percent. Relevant statistics: Maximum |
MasterFreeStorageSpace |
This metric is not relevant and can be ignored. The service does not use master nodes as data nodes. |
MasterJVMMemoryPressure |
The maximum percentage of the Java heap used for all dedicated master nodes in the cluster. We recommend moving to a larger instance type when this metric reaches 85 percent. Relevant statistics: Maximum NoteThe logic for this metric changed in service software R20220323. For more information, see the release notes. |
MasterOldGenJVMMemoryPressure |
The maximum percentage of the Java heap used for the "old generation" per master node. Relevant statistics: Maximum |
MasterCPUCreditBalance |
The remaining CPU credits available for dedicated master nodes in the cluster. A CPU credit provides the performance of a full CPU core for one minute. For more information, see CPU credits in the Amazon EC2 Developer Guide. This metric is available only for the T2 instance types. Relevant statistics: Minimum |
MasterReachableFromNode |
A health check for Failures mean that the master node is unreachable from the source node. They're usually the result of a network connectivity issue or an Amazon dependency problem. Relevant statistics: Maximum |
MasterSysMemoryUtilization |
The percentage of the master node's memory that is in use. Relevant statistics: Maximum |
Dedicated coordinator node metrics
Amazon OpenSearch Service provides the following metrics for Dedicated coordinator nodes.
| Metric | Description |
|---|---|
CoordinatorCPUUtilization |
The maximum percentage of CPU resources used by the dedicated coordinator nodes. We recommend increasing the size of the instance type when this metric reaches 80 percent. Relevant statistics: Maximum |
CoordinatorJVMMemoryPressure |
The maximum percentage of the Java heap used for all dedicated coordinator nodes in the cluster. We recommend moving to a larger instance type when this metric reaches 85 percent. Relevant statistics: Maximum |
CoordinatorOldGenJVMMemoryPressure |
The maximum percentage of the Java heap used for the "old generation" per master node. Relevant statistics: Maximum |
CoordinatorSysMemoryUtilization |
The percentage of the coordinator node's memory that is in use. Relevant statistics: Maximum |
CoordinatorFreeStorageSpace |
This metric indicates that the service does not use coordinator nodes as data nodes. |
EBS volume metrics
Amazon OpenSearch Service provides the following metrics for EBS volumes.
| Metric | Description |
|---|---|
ReadLatency |
The latency, in seconds, for read operations on EBS volumes. This metric is also available for individual nodes. Relevant statistics: Minimum, Maximum, Average |
WriteLatency |
The latency, in seconds, for write operations on EBS volumes. This metric is also available for individual nodes. Relevant statistics: Minimum, Maximum, Average |
ReadThroughput |
The throughput, in bytes per second, for read operations on EBS volumes. This metric is also available for individual nodes. Relevant statistics: Minimum, Maximum, Average |
ReadThroughputMicroBursting |
The throughput, in bytes per second, for read operations on EBS
volumes when micro-bursting Relevant statistics: Minimum, Maximum, Average |
WriteThroughput |
The throughput, in bytes per second, for write operations on EBS volumes. This metric is also available for individual nodes. Relevant statistics: Minimum, Maximum, Average |
WriteThroughputMicroBursting |
The throughput, in bytes per second, for write operations on EBS
volumes when micro-bursting Relevant statistics: Minimum, Maximum, Average |
DiskQueueDepth |
The number of pending input and output (I/O) requests for an EBS volume. Relevant statistics: Minimum, Maximum, Average |
ReadIOPS |
The number of input and output (I/O) operations per second for read operations on EBS volumes. This metric is also available for individual nodes. Relevant statistics: Minimum, Maximum, Average |
ReadIOPSMicroBursting |
The number of input and output (I/O) operations per second for
read operations on EBS volumes when micro-bursting Relevant statistics: Minimum, Maximum, Average |
WriteIOPS |
The number of input and output (I/O) operations per second for write operations on EBS volumes. This metric is also available for individual nodes. Relevant statistics: Minimum, Maximum, Average |
WriteIOPSMicroBursting |
The number of input and output (I/O) operations per second for
write operations on EBS volumes when micro-bursting Relevant statistics: Minimum, Maximum, Average |
BurstBalance |
The percentage of input and output (I/O) credits remaining in the burst bucket for an EBS volume. A value of 100 means that the volume has accumulated the maximum number of credits. If this percentage falls below 70%, see Low EBS burst balance. The burst balance stays at 0 for domains with gp3 volumes types, and domains with gp2 volumes that have a volume size above 1000 GiB. Relevant statistics: Minimum, Maximum, Average |
VolumeStalledIOcheck |
The status of your EBS volumes to determine when they are
impaired. The metrics is a binary value that returns a 0 (pass) or a
1 (fail) status based on whether the EBS volume can complete input
and output operations. Relevant statistics: Minimum, Maximum, Average |
Instance metrics
Amazon OpenSearch Service provides the following metrics for each instance in a domain. OpenSearch Service also aggregates these instance metrics to provide insight into overall cluster health. You can verify this behavior using the Sample Count statistic in the console. Note that each metric in the following table has relevant statistics for the node and the cluster.
Important
Different versions of Elasticsearch use different thread pools to process calls to
the _index API. Elasticsearch 1.5 and 2.3 use the index thread pool.
Elasticsearch 5.x, 6.0, and 6.2 use the bulk
thread pool. OpenSearch and Elasticsearch 6.3 and later use the write thread pool.
Currently, the OpenSearch Service console doesn't include a graph for the bulk thread
pool.
Use GET _cluster/settings?include_defaults=true to check thread pool
and queue sizes for your cluster.
| Metric | Description |
|---|---|
FetchLatency |
The difference in total time, in milliseconds, taken by all shard fetch operations in a node between minute N and minute (N - 1). Relevant node statistics: Average Relevant cluster statistics: Average, Maximum |
FetchRate |
The total number of shard fetch operations per minute for all shards on a data node. Relevant node statistics: Average Relevant cluster statistics: Average, Maximum, Sum |
ScrollTotal |
The total number of shard scroll operations per minute for all shards on a data node. Relevant node statistics: Average, Maximum Relevant cluster statistics: Average, Maximum, Sum |
ScrollCurrent |
The number of shard scroll operations that are currently running. Relevant node statistics: Average, Maximum Relevant cluster statistics: Average, Maximum, Sum |
OpenContexts |
The number of open search contexts. Relevant node statistics: Average, Maximum Relevant cluster statistics: Average, Maximum, Sum |
ThreadCount |
The total number of threads currently being utilized by the OpenSearch process. Relevant node statistics: Average, Maximum Relevant cluster statistics: Average, Maximum, Sum |
ShardReactivateCount |
The total number of times that all shards have been activated from an idle state. Relevant node statistics: Sum, Maximum Relevant cluster statistics: Sum, Maximum |
ConcurrentSearchRate |
The total number of search requests using concurrent segment
search per minute for all shards on a data node. A single call to
the Relevant node statistics: Average Relevant cluster statistics: Average, Maximum, Sum |
ConcurrentSearchLatency |
The difference in total time, in milliseconds, taken by all searches using concurrent segment search in a node between minute N and minute (N-1). Relevant node statistics: Average Relevant cluster statistics: Average, Maximum |
IndexingLatency |
The difference in total time, in milliseconds, taken by all indexing operations in a node between minute N and minute (N-1). Relevant node statistics: Average Relevant cluster statistics: Average, Maximum |
IndexingRate |
The number of indexing operations per minute. A single call to the
Relevant node statistics: Average Relevant cluster statistics: Average, Maximum, Sum |
SearchLatency |
The difference in total time, in milliseconds, taken by all searches in a node between minute N and minute (N-1). Relevant node statistics: Average Relevant cluster statistics: Average, Maximum |
SearchRate |
The total number of search requests per minute for all shards on a
data node. A single call to the Relevant node statistics: Average Relevant cluster statistics: Average, Maximum, Sum |
SegmentCount |
The number of segments on a data node. The more segments you have, the longer each search takes. OpenSearch occasionally merges smaller segments into a larger one. Relevant node statistics: Maximum, Average Relevant cluster statistics: Sum, Maximum, Average |
SysMemoryUtilization |
The percentage of the instance's memory that is in use. High
values for this metric are normal and usually do not represent a
problem with your cluster. For a better indicator of potential
performance and stability issues, see the
Relevant node statistics: Minimum, Maximum, Average Relevant cluster statistics: Minimum, Maximum, Average |
JVMGCYoungCollectionCount |
The number of times that "young generation" garbage collection has run. A large, ever-growing number of runs is a normal part of cluster operations. Relevant node statistics: Maximum Relevant cluster statistics: Sum, Maximum, Average |
JVMGCYoungCollectionTime |
The amount of time, in milliseconds, that the cluster has spent performing "young generation" garbage collection. Relevant node statistics: Maximum Relevant cluster statistics: Sum, Maximum, Average |
JVMGCOldCollectionCount |
The number of times that "old generation" garbage collection has run. In a cluster with sufficient resources, this number should remain small and grow infrequently. Relevant node statistics: Maximum Relevant cluster statistics: Sum, Maximum, Average |
JVMGCOldCollectionTime |
The amount of time, in milliseconds, that the cluster has spent performing "old generation" garbage collection. Relevant node statistics: Maximum Relevant cluster statistics: Sum, Maximum, Average |
OpenSearchDashboardsConcurrentConnections |
The number of active concurrent connections to OpenSearch Dashboards. If this number is consistently high, consider scaling your cluster. Relevant node statistics: Maximum Relevant cluster statistics: Sum, Maximum, Average |
OpenSearchDashboardsHealthyNode |
A health check for the individual OpenSearch Dashboards node. A value of 1 indicates normal behavior. A value of 0 indicates that Dashboards is inaccessible. Relevant node statistics: Minimum Relevant cluster statistics: Minimum, Maximum, Average |
OpenSearchDashboardsHeapTotal |
The amount of heap memory allocated to OpenSearch Dashboards in MiB. Different EC2 instance types can impact the exact memory allocation. Relevant node statistics: Maximum Relevant cluster statistics: Sum, Maximum, Average |
OpenSearchDashboardsHeapUsed |
The absolute amount of heap memory used by OpenSearch Dashboards in MiB. Relevant node statistics: Maximum Relevant cluster statistics: Sum, Maximum, Average |
OpenSearchDashboardsHeapUtilization |
The maximum percentage of available heap memory used by OpenSearch Dashboards. If this value increases above 80%, consider scaling your cluster. Relevant node statistics: Maximum Relevant cluster statistics: Minimum, Maximum, Average |
OpenSearchDashboardsOS1MinuteLoad |
The one-minute CPU load average for OpenSearch Dashboards. The CPU load should ideally stay below 1.00. While temporary spikes are fine, we recommend increasing the size of the instance type if this metric is consistently above 1.00. Relevant node statistics: Average Relevant cluster statistics: Average, Maximum |
OpenSearchDashboardsRequestTotal |
The total count of HTTP requests made to OpenSearch Dashboards. If your system is slow or you see high numbers of Dashboards requests, consider increasing the size of the instance type. Relevant node statistics: Sum Relevant cluster statistics: Sum |
OpenSearchDashboardsResponseTimesMaxInMillis |
The maximum amount of time, in milliseconds, that it takes for OpenSearch Dashboards to respond to a request. If requests consistently take a long time to return results, consider increasing the size of the instance type. Relevant node statistics: Maximum Relevant cluster statistics: Maximum, Average |
SearchTaskCancelled |
The number of coordinator node cancellations. Relevant node statistics: Sum Relevant cluster statistics: Sum |
SearchShardTaskCancelled |
The number of data node cancellations. Relevant node statistics: Sum Relevant cluster statistics: Sum, |
ThreadpoolForce_mergeQueue |
The number of queued tasks in the force merge thread pool. If the queue size is consistently high, consider scaling your cluster. Relevant node statistics: Maximum Relevant cluster statistics: Sum, Maximum, Average |
ThreadpoolForce_mergeRejected |
The number of rejected tasks in the force merge thread pool. If this number continually grows, consider scaling your cluster. Relevant node statistics: Maximum Relevant cluster statistics: Sum |
ThreadpoolForce_mergeThreads |
The size of the force merge thread pool. Relevant node statistics: Maximum Relevant cluster statistics: Average, Sum |
ThreadpoolIndexQueue |
The number of queued tasks in the index thread pool. If the queue size is consistently high, consider scaling your cluster. The maximum index queue size is 200. Relevant node statistics: Maximum Relevant cluster statistics: Sum, Maximum, Average |
ThreadpoolIndexRejected |
The number of rejected tasks in the index thread pool. If this number continually grows, consider scaling your cluster. Relevant node statistics: Maximum Relevant cluster statistics: Sum |
ThreadpoolIndexThreads |
The size of the index thread pool. Relevant node statistics: Maximum Relevant cluster statistics: Average, Sum |
ThreadpoolSearchQueue |
The number of queued tasks in the search thread pool. If the queue size is consistently high, consider scaling your cluster. The maximum search queue size is 1,000. Relevant node statistics: Maximum Relevant cluster statistics: Sum, Maximum, Average |
ThreadpoolSearchRejected |
The number of rejected tasks in the search thread pool. If this number continually grows, consider scaling your cluster. Relevant node statistics: Maximum Relevant cluster statistics: Sum |
ThreadpoolSearchThreads |
The size of the search thread pool. Relevant node statistics: Maximum Relevant cluster statistics: Average, Sum |
Threadpoolsql-workerQueue |
The number of queued tasks in the SQL search thread pool. If the queue size is consistently high, consider scaling your cluster. Relevant node statistics: Maximum Relevant cluster statistics: Sum, Maximum, Average |
Threadpoolsql-workerRejected |
The number of rejected tasks in the SQL search thread pool. If this number continually grows, consider scaling your cluster. Relevant node statistics: Maximum Relevant cluster statistics: Sum |
Threadpoolsql-workerThreads |
The size of the SQL search thread pool. Relevant node statistics: Maximum Relevant cluster statistics: Average, Sum |
ThreadpoolBulkQueue |
The number of queued tasks in the bulk thread pool. If the queue size is consistently high, consider scaling your cluster. Relevant node statistics: Maximum Relevant cluster statistics: Sum, Maximum, Average |
ThreadpoolBulkRejected |
The number of rejected tasks in the bulk thread pool. If this number continually grows, consider scaling your cluster. Relevant node statistics: Maximum Relevant cluster statistics: Sum |
ThreadpoolBulkThreads |
The size of the bulk thread pool. Relevant node statistics: Maximum Relevant cluster statistics: Average, Sum |
ThreadpoolIndexSearcherQueue |
The number of queued tasks in the index searcher thread pool. Relevant node statistics: Maximum Relevant cluster statistics: Sum, Maximum, Average |
ThreadpoolIndexSearcherRejected |
The number of rejected tasks in the index searcher thread pool. Relevant node statistics: Maximum Relevant cluster statistics: Sum |
ThreadpoolIndexSearcherThreads |
The size of the index searcher thread pool. Relevant node statistics: Maximum Relevant cluster statistics: Average, Sum |
ThreadpoolWriteThreads |
The size of the write thread pool. Relevant node statistics: Maximum Relevant cluster statistics: Average, Sum |
ThreadpoolWriteQueue |
The number of queued tasks in the write thread pool. Relevant node statistics: Maximum Relevant cluster statistics: Average, Sum |
ThreadpoolWriteRejected |
The number of rejected tasks in the write thread pool. Relevant node statistics: Maximum Relevant cluster statistics: Average, Sum NoteBecause the default write queue size was increased from 200 to
10000 in version 7.1, this metric is no longer the only
indicator of rejections from OpenSearch Service. Use the
|
CoordinatingWriteRejected |
The total number of rejections happened on the coordinating node due to indexing pressure since the last OpenSearch Service process startup. Relevant node statistics: Maximum Relevant cluster statistics: Average, Sum This metric is available in version 7.1 and above. |
PrimaryWriteRejected |
The total number of rejections happened on the primary shards due to indexing pressure since the last OpenSearch Service process startup. Relevant node statistics: Maximum Relevant cluster statistics: Average, Sum This metric is available in version 7.1 and above. |
ReplicaWriteRejected |
The total number of rejections happened on the replica shards due to indexing pressure since the last OpenSearch Service process startup. Relevant node statistics: Maximum Relevant cluster statistics: Average, Sum This metric is available in version 7.1 and above. |
WorkloadManagementEnabled |
Indicates whether the workload management feature is enabled. A
value of 1 means it is enabled, and a value of 0 means its
Relevant node statistics: Maximum, Minimum Relevant cluster statistics: Average, Sum This metric is available in version 7.1 and above. |
SoftQueryGroupCount |
Number of query groups under soft mode in the domain. Relevant node statistics: Average, Maximum Relevant cluster statistics: Average, Maximum, Sum This metric is available in version 7.1 and above. |
EnforcedQueryGroupCount |
Number of query groups under enforced mode in the domain. Relevant node statistics: Average, Maximum Relevant cluster statistics: Average, Maximum, Sum This metric is available in version 7.1 and above. |
Warm metrics
Amazon OpenSearch Service provides the following metrics for Multi-tier storage architecture and UltraWarm
Note
Warm indexing related metrics are only applicable for Multi-tier storage architecture
| Metric | Description |
|---|---|
WarmIndexingLatency
|
The difference in total time, in milliseconds, taken by all indexing operations in a warm node between minute N and minute (N-1). Relevant node statistics: Average Relevant cluster statistics: Average, Maximum |
WarmIndexingRate
|
The number of indexing operations on warm per minute. A single call to the
Relevant node statistics: Average Relevant cluster statistics: Average, Maximum, Sum |
WarmThreadpoolIndexingQueue
|
The number of queued tasks in the index thread pool. If the queue size is consistently high, consider scaling your cluster. The maximum index queue size is 200. Relevant node statistics: Maximum Relevant cluster statistics: Average, Maximum, Sum |
WarmThreadpoolIndexingRejected
|
The number of rejected tasks in the index thread pool. If this number continually grows, consider scaling your cluster. Relevant node statistics: Maximum Relevant cluster statistics: Sum |
WarmThreadpoolIndexingThreads
|
The size of the index thread pool. Relevant node statistics: Maximum Relevant cluster statistics: Average, Sum |
WarmCPUUtilization |
The percentage of CPU usage for Warm nodes in the cluster. Maximum shows the node with the highest CPU usage. Average represents all Warm nodes in the cluster. This metric is also available for individual Warm nodes. Relevant statistics: Maximum, Average |
WarmFreeStorageSpace |
The amount of free warm storage space in MiB. Because Warm
uses Amazon S3 rather than attached disks, Relevant statistics: Sum |
WarmSearchableDocuments |
The total number of searchable documents across all warm indexes in the cluster. You must leave the period at one minute to get an accurate value. Relevant statistics: Sum |
WarmSearchLatency
|
The difference in total time, in milliseconds, taken by all searches in an Warm between minute N and minute (N-1). Relevant node statistics: Average Relevant cluster statistics: Average, Maximum |
WarmSearchRate
|
The total number of search requests per minute for all shards on
an Warm node. A single call to the Relevant node statistics: Average Relevant cluster statistics: Average, Maximum, Sum |
WarmStorageSpaceUtilization |
The total amount of warm storage space, in MiB, that the cluster is using. Relevant statistics: Maximum |
HotStorageSpaceUtilization
|
The total amount of hot storage space that the cluster is using. Relevant statistics: Maximum |
WarmSysMemoryUtilization |
The percentage of the warm node's memory that is in use. Relevant statistics: Maximum |
HotToWarmMigrationQueueSize
|
The number of indexes currently waiting to migrate from hot to warm storage. Relevant statistics: Maximum |
WarmToHotMigrationQueueSize
|
The number of indexes currently waiting to migrate from warm to hot storage. Relevant statistics: Maximum |
HotToWarmMigrationFailureCount
|
The total number of failed hot to warm migrations. This metric is available only for UltraWarm nodes. Relevant statistics: Sum |
HotToWarmMigrationForceMergeLatency
|
The average latency of the force merge stage of the migration
process. If this stage consistently takes too long, consider
increasing. This metric is available only for UltraWarm nodes.
Relevant statistics: Average |
HotToWarmMigrationSnapshotLatency
|
The average latency of the snapshot stage of the migration process. If this stage consistently takes too long, ensure that your shards are appropriately sized and distributed throughout the cluster. This metric is available only for UltraWarm nodes. Relevant statistics: Average |
HotToWarmMigrationProcessingLatency
|
The average latency of successful hot to warm migrations, not including time spent in the queue. This value is the sum of the amount of time it takes to complete the force merge, snapshot, and shard relocation stages of the migration process. This metric is available only for UltraWarm nodes. Relevant statistics: Average |
HotToWarmMigrationSuccessCount
|
The total number of successful hot to warm migrations. Relevant statistics: Sum |
HotToWarmMigrationSuccessLatency
|
The average latency of successful hot to warm migrations, including time spent in the queue. Relevant statistics: Average |
WarmThreadpoolSearchThreads |
The size of the Warm search thread pool. Relevant node statistics: Maximum Relevant cluster statistics: Average, Sum |
WarmThreadpoolSearchRejected |
The number of rejected tasks in the Warm search thread pool. If this number continually grows, consider adding more Warm nodes. Relevant node statistics: Maximum Relevant cluster statistics: Sum |
WarmThreadpoolSearchQueue |
The number of queued tasks in the Warm search thread pool. If
the queue size is consistently high, consider adding more Warm
nodes. Relevant node statistics: Maximum Relevant cluster statistics: Sum, Maximum, Average |
WarmJVMMemoryPressure |
The maximum percentage of the Java heap used for the Warm nodes. Relevant statistics: Maximum NoteThe logic for this metric changed in service software R20220323. For more information, see the release notes. |
WarmOldGenJVMMemoryPressure |
The maximum percentage of the Java heap used for the "old generation" per Warm node. Relevant statistics: Maximum |
WarmJVMGCYoungCollectionCount |
The number of times that "young generation" garbage collection has run on Warm nodes. A large, ever-growing number of runs is a normal part of cluster operations. Relevant node statistics: Maximum Relevant cluster statistics: Sum, Maximum, Average |
WarmJVMGCYoungCollectionTime |
The amount of time, in milliseconds, that the cluster has spent performing "young generation" garbage collection on Warm nodes. Relevant node statistics: Maximum Relevant cluster statistics: Sum, Maximum, Average |
WarmJVMGCOldCollectionCount |
The number of times that "old generation" garbage collection has run on Warm nodes. In a cluster with sufficient resources, this number should remain small and grow infrequently. Relevant node statistics: Maximum Relevant cluster statistics: Sum, Maximum, Average |
WarmConcurrentSearchRate |
The total number of search requests using concurrent segment
search per minute for all shards on a Warm node. A single call
to the Relevant node statistics: Average Relevant cluster statistics: Sum, Maximum, Average |
WarmConcurrentSearchLatency |
The difference in total time, in milliseconds, taken by all searches using concurrent segment search in a Warm node between minute N and minute (N-1). Relevant node statistics: Average Relevant cluster statistics: Maximum, Average |
WarmThreadpoolIndexSearcherQueue |
The number of queued tasks in the Warm index searcher thread pool. Relevant node statistics: Maximum Relevant cluster statistics: Sum, Maximum, Average |
WarmThreadpoolIndexSearcherRejected |
The number of rejected tasks in the Warm index searcher thread pool. Relevant node statistics: Maximum Relevant cluster statistics: Sum |
WarmThreadpoolIndexSearcherThreads |
The size of the Warm index searcher thread pool. Relevant node statistics: Maximum Relevant cluster statistics: Sum, Average |
Cold storage metrics
Amazon OpenSearch Service provides the following metrics for cold storage.
| Metric | Description |
|---|---|
ColdStorageSpaceUtilization
|
The total amount of cold storage space, in MiB, that the cluster is using. Relevant statistics: Max |
ColdToWarmMigrationFailureCount |
The total number of failed cold to warm migrations. Relevant statistics: Sum |
ColdToWarmMigrationLatency |
The amount of time for successful cold to warm migrations to complete. Relevant statistics: Average |
ColdToWarmMigrationQueueSize |
The number of indexes currently waiting to migrate from cold to warm storage. Relevant statistics: Maximum |
ColdToWarmMigrationSuccessCount
|
The total number of successful cold to warm migrations. Relevant statistics: Sum |
WarmToColdMigrationFailureCount
|
The total number of failed warm to cold migrations. Relevant statistics: Sum |
WarmToColdMigrationLatency |
The amount of time for successful warm to cold migrations to complete. Relevant statistics: Average |
WarmToColdMigrationQueueSize |
The number of indexes currently waiting to migrate from warm to cold storage. Relevant statistics: Maximum |
WarmToColdMigrationSuccessCount |
The total number of successful warm to cold migrations. Relevant statistics: Sum |
OpenSearch Optimized Instances (OR1) metrics
Amazon OpenSearch Service provides the following metrics for OR1 instances.
| Metric | Description |
|---|---|
RemoteStorageUsedSpace
|
The total amount of Amazon S3 space, in MiB, that the cluster is using. Relevant statistics: Sum |
RemoteStorageWriteRejected |
The total number of requests rejected on primary shards due to remote storage and replication pressure. This is calculated starting from the last OpenSearch Service process startup. Relevant statistics: Sum |
ReplicationLagMaxTime |
The amount of time, in milliseconds, that replica shards are behind the primary shards. Relevant statistics: Maximum |
Alerting metrics
Amazon OpenSearch Service provides the following metrics for alerting.
| Metric | Description |
|---|---|
AlertingDegraded |
A value of 1 means that either the alerting index is red or one or more nodes is not on schedule. A value of 0 indicates normal behavior. Relevant statistics: Maximum |
AlertingIndexExists |
A value of 1 means the Relevant statistics: Maximum |
AlertingIndexStatus.green |
The health of the index. A value of 1 means green. A value of 0 means that the index either doesn't exist or isn't green. Relevant statistics: Maximum |
AlertingIndexStatus.red |
The health of the index. A value of 1 means red. A value of 0 means that the index either doesn't exist or isn't red. Relevant statistics: Maximum |
AlertingIndexStatus.yellow |
The health of the index. A value of 1 means yellow. A value of 0 means that the index either doesn't exist or isn't yellow. Relevant statistics: Maximum |
AlertingNodesNotOnSchedule |
A value of 1 means some jobs are not running on schedule. A value
of 0 means that all alerting jobs are running on schedule (or that
no alerting jobs exist). Check the OpenSearch Service console or make a
Relevant statistics: Maximum |
AlertingNodesOnSchedule |
A value of 1 means that all alerting jobs are running on schedule (or that no alerting jobs exist). A value of 0 means some jobs are not running on schedule. Relevant statistics: Maximum |
AlertingScheduledJobEnabled |
A value of 1 means that the
Relevant statistics: Maximum |
Anomaly detection metrics
Amazon OpenSearch Service provides the following metrics for anomaly detection.
| Metric | Description |
|---|---|
ADPluginUnhealthy |
A value of 1 means that the anomaly detection plugin is not functioning properly, either because of a high number of failures or because one of the indexes that it uses is red. A value of 0 indicates the plugin is working as expected. Relevant statistics: Maximum |
ADExecuteRequestCount |
The number of requests to detect anomalies. Relevant statistics: Sum |
ADExecuteFailureCount
|
The number of failed requests to detect anomalies. Relevant statistics: Sum |
ADHCExecuteFailureCount |
The number of failed requests to detect anomalies for high cardinality detectors. Relevant statistics: Sum |
ADHCExecuteRequestCount |
The number of requests to detect anomalies for high cardinality detectors. Relevant statistics: Sum |
ADAnomalyResultsIndexStatusIndexExists |
A value of 1 means the index that the
Relevant statistics: Maximum |
ADAnomalyResultsIndexStatus.red |
A value of 1 means the index that the
Relevant statistics: Maximum |
ADAnomalyDetectorsIndexStatusIndexExists |
A value of 1 means that the
Relevant statistics: Maximum |
ADAnomalyDetectorsIndexStatus.red |
A value of 1 means that the
Relevant statistics: Maximum |
ADModelsCheckpointIndexStatusIndexExists |
A value of 1 means that the
Relevant statistics: Maximum |
ADModelsCheckpointIndexStatus.red |
A value of 1 means that the
Relevant statistics: Maximum |
Asynchronous search metrics
Amazon OpenSearch Service provides the following metrics for asynchronous search.
Asynchronous search coordinator node statistics (per coordinator node)
| Metric | Description |
|---|---|
AsynchronousSearchSubmissionRate |
The number of asynchronous searches submitted in the last minute. |
AsynchronousSearchInitializedRate |
The number of asynchronous searches initialized in the last minute. |
AsynchronousSearchRunningCurrent |
The number of asynchronous searches currently running. |
AsynchronousSearchCompletionRate |
The number of asynchronous searches successfully completed in the last minute. |
AsynchronousSearchFailureRate |
The number of asynchronous searches that completed and failed in the last minute. |
AsynchronousSearchPersistRate |
The number of asynchronous searches that persisted in the last minute. |
AsynchronousSearchPersistFailedRate |
The number of asynchronous searches that failed to persist in the last minute. |
AsynchronousSearchRejected |
The total number of asynchronous searches rejected since the node up time. |
AsynchronousSearchCancelled |
The total number of asynchronous searches cancelled since the node up time. |
AsynchronousSearchMaxRunningTime |
The duration of longest running asynchronous search on a node in the last minute. |
Asynchronous search cluster statistics
| Metric | Description |
|---|---|
AsynchronousSearchStoreHealth |
The health of the store in the persisted index (RED/non-RED) in the last minute. |
AsynchronousSearchStoreSize |
The size of the system index across all shards in the last minute. |
AsynchronousSearchStoredResponseCount |
The numbers of stored responses in the system index in the last minute. |
Auto-Tune metrics
Amazon OpenSearch Service provides the following metrics for Auto-Tune.
| Metric | Description |
|---|---|
AutoTuneChangesHistoryHeapSize |
The change history in MiB for heap size tuning values. |
AutoTuneChangesHistoryJVMYoungGenArgs |
The change history for JVM YongGen arguments. |
AutoTuneFailed |
A boolean that indicates if the Auto-Tune change failed. |
AutoTuneSucceeded |
A boolean that indicates if the Auto-Tune change succeeded. |
AutoTuneValue |
The queue change history (count) and cache tunings change history (in MiB) for non-disruptive changes. |
Multi-AZ with Standby metrics
Amazon OpenSearch Service provides the following metrics for Multi-AZ with Standby.
Node-level metrics for data nodes in active Availability Zones
| Metric | Description |
|---|---|
CPUUtilization |
The percentage of CPU usage for data nodes in the cluster. Maximum shows the node with the highest CPU usage. Average represents all nodes in the cluster. This metric is also available for individual nodes. |
FreeStorageSpace |
The free space for data nodes in the cluster. The OpenSearch Service console displays this value in GiB. The Amazon CloudWatch console displays it in MiB. |
JVMMemoryPressure |
The maximum percentage of the Java heap used for all data nodes in the cluster. OpenSearch Service uses half of an instance's RAM for the Java heap, up to a heap size of 32 GiB. You can scale instances vertically up to 64 GiB of RAM, at which point you can scale horizontally by adding instances. See Recommended CloudWatch alarms for Amazon OpenSearch Service. |
SysMemoryUtilization |
The percentage of the instance's memory that is in use. High
values for this metric are normal and usually do not represent a problem
with your cluster. For a better indicator of potential performance and
stability issues, see the JVMMemoryPressure metric. |
IndexingLatency |
The difference in total time, in milliseconds, taken by all indexing operations in a node between minute N and minute (N-1). |
IndexingRate |
The number of indexing operations per minute. |
SearchLatency |
The difference in total time, in milliseconds, taken by all searches in a node between minute N and minute (N-1). |
SearchRate |
The total number of search requests per minute for all shards on a data node. |
ThreadpoolSearchQueue |
The number of queued tasks in the search thread pool. If the queue size is consistently high, consider scaling your cluster. The maximum search queue size is 1,000. |
ThreadpoolWriteQueue |
The number of queued tasks in the write thread pool. |
ThreadpoolSearchRejected |
The number of rejected tasks in the search thread pool. If this number continually grows, consider scaling your cluster. |
ThreadpoolWriteRejected |
The number of rejected tasks in the write thread pool. |
Cluster-level metrics for clusters in active Availability Zones
| Metric | Description |
|---|---|
DataNodes |
The total number of active and standby shards. |
DataNodesShards.active |
The total number of active primary and replica shards. |
DataNodesShards.unassigned |
The number of shards that are not allocated to nodes in the cluster. |
DataNodesShards.initializing |
The number of shards that are under initialization. |
DataNodesShards.relocating |
The number of shards that are under relocation. |
Availability Zone rotation metrics
If ActiveReads., then the
zone is active. If Availability-Zone = 1ActiveReads., then the zone is in standby.Availability-Zone =
0
Point in time metrics
Amazon OpenSearch Service provides the following metrics for point in time (PIT) searches.
PIT coordinator node statistics (per coordinator node)
| Metric | Description |
|---|---|
CurrentPointInTime |
The number of active PIT search contexts in the node. |
TotalPointInTime |
The number of expired PIT search contexts since the node up time. |
AvgPointInTimeAliveTime |
The average keep alive of PIT search contexts since the node up time. |
HasActivePointInTime |
A value of 1 indicates that there are active PIT contexts on nodes since the node up time. A value of 0 means there are not. |
HasUsedPointInTime |
A value of 1 indicates that there are expired PIT contexts on nodes since the node up time. A value of 0 means there are not. |
SQL metrics
Amazon OpenSearch Service provides the following metrics for SQL support.
| Metric | Description |
|---|---|
SQLFailedRequestCountByCusErr |
The number of requests to the Relevant statistics: Sum |
SQLFailedRequestCountBySysErr |
The number of requests to the Relevant statistics: Sum |
SQLRequestCount |
The number of requests to the Relevant statistics: Sum |
SQLDefaultCursorRequestCount |
Similar to Relevant statistics: Sum |
SQLUnhealthy |
A value of 1 indicates that, in response to certain requests, the SQL plugin is returning 5xx response codes or passing invalid query DSL to OpenSearch. Other requests should continue to succeed. A value of 0 indicates no recent failures. If you see a sustained value of 1, troubleshoot the requests your clients are making to the plugin. Relevant statistics: Maximum |
k-NN metrics
Amazon OpenSearch Service includes the following metrics for the k-nearest neighbor (k-NN) plugin.
| Metric | Description |
|---|---|
KNNCacheCapacityReached |
Per-node metric for whether cache capacity has been reached. This metric is only relevant to approximate k-NN search. Relevant statistics: Maximum |
KNNCircuitBreakerTriggered |
Per-cluster metric for whether the circuit breaker is triggered.
If any nodes return a value of 1 for
Relevant statistics: Maximum |
KNNEvictionCount |
Per-node metric for the number of graphs that have been evicted from the cache due to memory constraints or idle time. Explicit evictions that occur because of index deletion are not counted. This metric is only relevant to approximate k-NN search. Relevant statistics: Sum |
KNNGraphIndexErrors |
Per-node metric for the number of requests to add the
Relevant statistics: Sum |
KNNGraphIndexRequests |
Per-node metric for the number of requests to add the
Relevant statistics: Sum |
KNNGraphMemoryUsage |
Per-node metric for the current cache size (total size of all graphs in memory) in kilobytes. This metric is only relevant to approximate k-NN search. Relevant statistics: Average |
KNNGraphQueryErrors |
Per-node metric for the number of graph queries that produced an error. Relevant statistics: Sum |
KNNGraphQueryRequests |
Per-node metric for the number of graph queries. Relevant statistics: Sum |
KNNHitCount |
Per-node metric for the number of cache hits. A cache hit occurs when a user queries a graph that is already loaded into memory. This metric is only relevant to approximate k-NN search. Relevant statistics: Sum |
KNNLoadExceptionCount |
Per-node metric for the number of times an exception occurred while trying to load a graph into the cache. This metric is only relevant to approximate k-NN search. Relevant statistics: Sum |
KNNLoadSuccessCount |
Per-node metric for the number of times the plugin successfully loaded a graph into the cache. This metric is only relevant to approximate k-NN search. Relevant statistics: Sum |
KNNMissCount |
Per-node metric for the number of cache misses. A cache miss occurs when a user queries a graph that is not yet loaded into memory. This metric is only relevant to approximate k-NN search. Relevant statistics: Sum |
KNNQueryRequests |
Per-node metric for the number of query requests the k-NN plugin received. Relevant statistics: Sum |
KNNRemoteBuildEnabled |
Binary value that specifies whether the feature is enabled. Relevant statistics: Binary |
KNNRemoteIndexBuildFailureCount |
Total number of build failures. Relevant statistics: Sum |
KNNRemoteIndexBuildSuccessCount |
Total number of successful builds. Relevant statistics: Sum |
KNNScriptCompilationErrors |
Per-node metric for the number of errors during script compilation. This statistic is only relevant to k-NN score script search. Relevant statistics: Sum |
KNNScriptCompilations |
Per-node metric for the number of times the k-NN script has been compiled. This value should usually be 1 or 0, but if the cache containing the compiled scripts is filled, the k-NN script might be recompiled. This statistic is only relevant to k-NN score script search. Relevant statistics: Sum |
KNNScriptQueryErrors |
Per-node metric for the number of errors during script queries. This statistic is only relevant to k-NN score script search. Relevant statistics: Sum |
KNNScriptQueryRequests |
Per-node metric for the total number of script queries. This statistic is only relevant to k-NN score script search. Relevant statistics: Sum |
KNNTotalLoadTime |
The time in nanoseconds that k-NN has taken to load graphs into the cache. This metric is only relevant to approximate k-NN search. Relevant statistics: Sum |
VectorIndexBuildAccelerationOCU |
The number of OpenSearch Compute Units (OCUs) used to accelerate vector indexing. Relevant statistics: Sum |
Cross-cluster search metrics
Amazon OpenSearch Service provides the following metrics for cross-cluster search.
Source domain metrics
| Metric | Dimension | Description |
|---|---|---|
CrossClusterOutboundConnections |
|
Number of connected nodes. If your response includes one or more skipped domains, use this metric to trace any unhealthy connections. If this number drops to 0, then the connection is unhealthy. |
CrossClusterOutboundRequests |
|
Number of search requests sent to the destination domain. Use to check if the load of cross-cluster search requests are overwhelming your domain, correlate any spike in this metric with any JVM/CPU spike. |
Destination domain metric
| Metric | Dimension | Description |
|---|---|---|
CrossClusterInboundRequests |
|
Number of incoming connection requests received from the source domain. |
Add a CloudWatch alarm in the event that you lose a connection unexpectedly. For steps to create an alarm, see Create a CloudWatch Alarm Based on a Static Threshold.
Cross-cluster replication metrics
Amazon OpenSearch Service provides the following metrics for cross-cluster replication.
| Metric | Description |
|---|---|
ReplicationRate |
The average rate of replication operations per second. This metric
is similar to the |
LeaderCheckPoint |
For a specific connection, the sum of leader checkpoint values across all replicating indexes. You can use this metric to measure replication latency. |
FollowerCheckPoint |
For a specific connection, the sum of follower checkpoint values across all replicating indexes. You can use this metric to measure replication latency. |
ReplicationNumSyncingIndices |
The number of indexes that have a replication status of
|
ReplicationNumBootstrappingIndices |
The number of indexes that have a replication status of
|
ReplicationNumPausedIndices |
The number of indexes that have a replication status of
|
ReplicationNumFailedIndices |
The number of indexes that have a replication status of
|
|
|
The number of replication transport requests on the follower domain. Transport requests are internal and occur each time a replication API operation is called. They also occur when the follower domain polls changes from the leader domain. |
|
|
The number of replication transport requests on the leader domain. Transport requests are internal and occur each time a replication API operation is called. |
AutoFollowNumSuccessStartReplication |
The number of follower indexes that have been successfully created by a replication rule for a specific connection. |
AutoFollowNumFailedStartReplication |
The number of follower indexes that failed to be created by a replication rule when there was a matching pattern. This problem might arise due to a network issue on the remote cluster, or a security issue (i.e. the associated role doesn't have permission to start replication). |
AutoFollowLeaderCallFailure |
Whether there have been any failed queries from the follower index
to the leader index to pull new data. A value of |
Learning to Rank metrics
Amazon OpenSearch Service provides the following metrics for Learning to Rank.
| Metric | Description |
|---|---|
LTRRequestTotalCount |
Total count of ranking requests. |
LTRRequestErrorCount |
Total count of unsuccessful requests. |
LTRStatus.red |
Tracks if one of the indexes needed to run the plugin is red. |
LTRMemoryUsage |
Total memory used by the plugin. |
LTRFeatureMemoryUsageInBytes |
The amount of memory, in bytes, used by Learning to Rank feature fields. |
LTRFeaturesetMemoryUsageInBytes |
The amount of memory, in bytes, used by all Learning to Rank feature sets. |
LTRModelMemoryUsageInBytes |
The amount of memory, in bytes, used by all Learning to Rank models. |
Piped Processing Language metrics
Amazon OpenSearch Service provides the following metrics for Piped Processing Language.
| Metric | Description |
|---|---|
PPLFailedRequestCountByCusErr |
The number of requests to the |
PPLFailedRequestCountBySysErr |
The number of requests to the |
PPLRequestCount |
The number of requests to the |