本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
适用于 Lustre 的 Amazon FSx 性能
本章提供适用于 Lustre 的 Amazon FSx 性能主题,包括一些重要的提示和建议,以最大限度地提高文件系统的性能。
概述
适用于 Lustre 的 Amazon FSx 基于热门高性能文件系统 Lustre 构建,可提供随文件系统大小线性增加的横向扩展性能。Lustre 文件系统可跨多个文件服务器和磁盘横向扩展。这种扩展让每个客户端可以直接访问存储在每个磁盘上的数据,从而消除传统文件系统中存在的诸多瓶颈。适用于 Lustre 的 Amazon FSx 建立在 Lustre 的可扩展架构之上,可支持大量客户端获得高水平性能。
FSx for Lustre 文件系统的工作原理
每个 FSx for Lustre 文件系统都由与客户机通信的文件服务器和一组连接到每个存储数据的文件服务器的磁盘组成。每台文件服务器都使用快速内存缓存来增强最常访问数据的性能。根据存储类别,可为文件服务器预置可选的 SSD 读取缓存。当客户端访问存储在内存缓存或 SSD 缓存中的数据时,文件服务器无需从磁盘读取数据,这样便可降低延迟并增加您可以驱动的总吞吐量。下图阐明了写入操作、从磁盘提供的读取操作以及从内存缓存或 SSD 缓存提供的读取操作的路径。
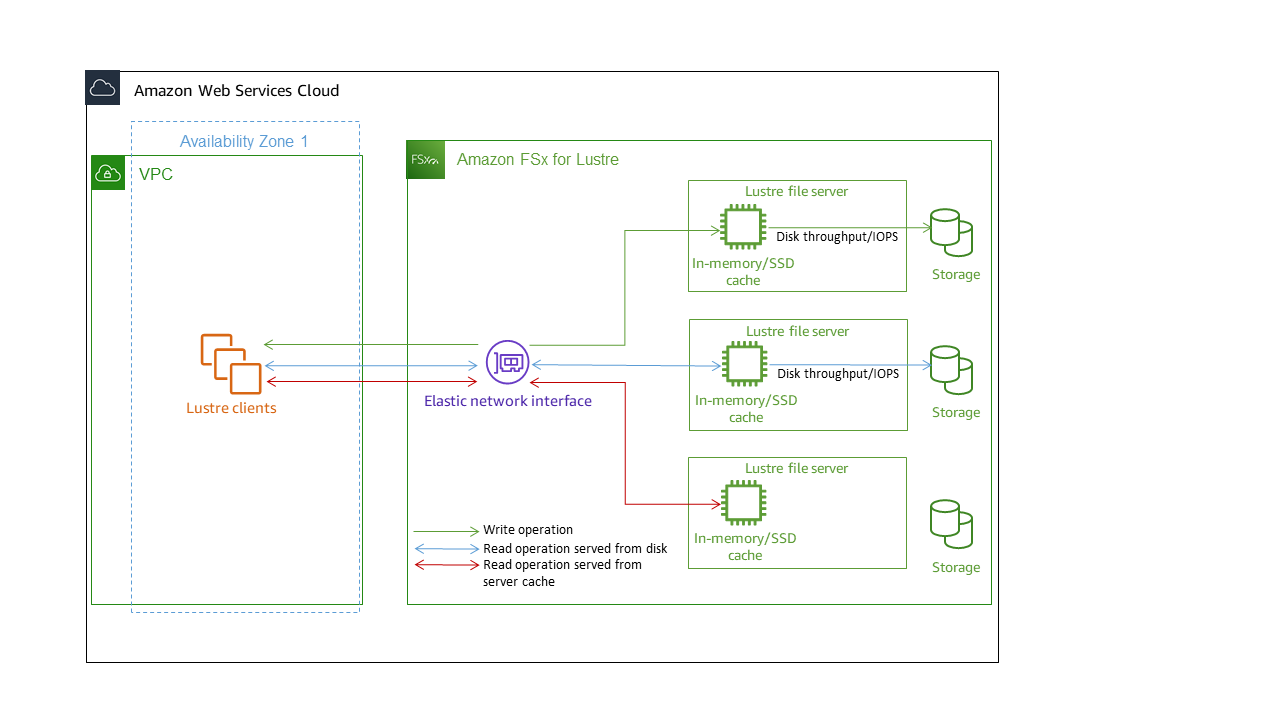
当读取存储在文件服务器的内存缓存或 SSD 缓存中的数据时,文件系统的性能取决于网络吞吐量。当将数据写入文件系统或读取未存储在内存缓存中的数据时,文件系统的性能取决于网络吞吐量和磁盘吞吐量中的较低者。
要详细了解网络吞吐量、磁盘吞吐量以及 SSD 和 HDD 存储类别的 IOPS 特性,请参阅 SSD 和 HDD 存储类别的性能特点 和 。
文件系统存储布局
Lustre 中的所有文件数据都存储在名为对象存储目标(OST)的存储卷上。所有文件元数据(包括文件名、时间戳、权限等)都存储在名为元数据目标(MDT)的存储卷上。适用于 Lustre 的 Amazon FSx 文件系统由一个或多个 MDT 以及多个 OST 组成。适用于 Lustre 的 Amazon FSx 将您的文件数据分散到构成文件系统的 OST 中,以平衡存储容量与吞吐量和 IOPS 负载。
要查看组成文件系统的 MDT 和 OST 的存储使用情况,请在挂载文件系统的客户端上运行以下命令。
lfs df -hmount/path
此命令的输出如下所示。
例
UUID bytes Used Available Use% Mounted onmountname-MDT0000_UUID 68.7G 5.4M 68.7G 0% /fsx[MDT:0]mountname-OST0000_UUID 1.1T 4.5M 1.1T 0% /fsx[OST:0]mountname-OST0001_UUID 1.1T 4.5M 1.1T 0% /fsx[OST:1] filesystem_summary: 2.2T 9.0M 2.2T 0% /fsx
对文件系统中的数据进行条带化
您可以利用文件条带化来优化文件系统的吞吐量性能。适用于 Lustre 的 Amazon FSx 会自动将文件分散到 OST 中,确保所有存储服务器都能提供数据。您可以通过配置文件在多个 OST 间的条带化方式,在文件级别应用相同的概念。
条带化意味着可以将文件分成多个块,然后存储在不同的 OST 中。当文件跨多个 OST 进行条带化处理时,对该文件的读取或写入请求会分散到这些 OST 中,从而增加应用程序可以驱动的聚合吞吐量或 IOPS。
以下是适用于 Lustre 的 Amazon FSx 文件系统的默认布局。
对于 2020 年 12 月 18 日之前创建的文件系统,默认布局将条带计数指定为 1。这意味着,除非指定不同的布局,否则使用标准 Linux 工具在适用于 Lustre 的 Amazon FSx 中创建的每个文件都存储在单个磁盘上。
对于 2020 年 12 月 18 日之后创建的文件系统,默认布局为渐进式文件布局,在这种布局中,大小低于 1GiB 的文件存储在一个条带中,而更大的文件则会分配条带计数 5。
对于 2023 年 8 月 25 日之后创建的文件系统,默认布局为 4 个组件的渐进式文件布局,如 渐进式文件布局 中所述。
对于所有文件系统,无论其创建日期如何,从 Amazon S3 导入的文件都不使用默认布局,而是使用文件系统
ImportedFileChunkSize参数中的布局。 S3-imported 大于的文件ImportedFileChunkSize将存储在多个 OST 上,条带计数(FileSize / ImportedFileChunksize) + 1为。ImportedFileChunkSize的默认值为 1GiB。
您可以使用 lfs getstripe 命令查看文件或目录的布局配置。
lfs getstripepath/to/filename
此命令会报告文件的条带计数、条带大小和条带偏移量。条带计数是文件在多少个 OST 上被条带化。条带大小是一个 OST 上存储的连续数据量。条带偏移量是文件被条带化的第一个 OST 的索引。
修改条带化配置
文件的布局参数是在首次创建文件时设置的。使用 lfs setstripe 命令创建新的空文件,并指定布局。
lfs setstripefilename--stripe-countnumber_of_OSTs
lfs setstripe 命令仅影响新文件的布局。您可以在创建文件前,用它来指定文件的布局。您也可以定义目录的布局。在目录上进行设置后,该布局将应用于添加到该目录的每个新文件,但不适用于现有文件。您创建的任何新子目录也会继承新布局,然后应用于您在该子目录中创建的任何新文件或目录。
要修改现有文件的布局,请使用 lfs migrate 命令。此命令按需复制文件,以便根据您在命令中指定的布局分发其内容。例如,追加的文件或大小增加的文件不会更改条带计数,因此您必须迁移这类文件才能更改文件布局。或者,您可以使用 lfs setstripe 命令创建新文件以指定其布局,将原始内容复制到新文件中,然后重命名新文件以替换原始文件。
在某些情况下,默认布局配置可能不是您工作负载的最优选择。例如,对于具有数十个 OST 和大量数 GB 文件的文件系统,如果将文件分成超过默认条带计数值(五个 OST)的条带,则性能可能会更高。创建条带数量少的大文件可能会导致 I/O 性能瓶颈,还可能导致 OST 被填满。在这种情况下,您可以为这些文件创建一个条带计数更大的目录。
为大型文件(尤其是大于 1 GB 的文件)设置条带化布局非常重要,原因如下:
通过允许多个 OST 及其关联服务器在读取和写入大型文件时提供 IOPS、网络带宽和 CPU 资源,提高吞吐量。
降低一小部分 OST 成为限制整体工作负载性能的热点的可能性。
防止单个大文件填满 OST,从而导致磁盘已满错误。
没有适合所有使用案例的最优布局配置。有关文件布局的详细指导,请参阅 Lustre.org 文档中的管理文件布局(分条)和可用空间
条带化布局对大型文件最为重要,特别是对于文件大小通常为数百兆字节或以上的使用案例。因此,新文件系统的默认布局会为大小超过 1GiB 的文件分配的条带计数为 5。
条带计数是您应针对支持大型文件的系统进行调整的布局参数。条带计数指定了将存放条带化文件块的 OST 卷的数量。例如,如果条带计数为 2,条带大小为 1MiB,Lustre 会将一个文件的 1MiB 备用块写入两个 OST。
有效条带计数是 OST 卷的实际数量和您指定条带计数值中的较小者。您可以使用特殊条带计数值
-1来表示应在所有 OST 卷上放置条带。为小文件设置较大的条带计数并不是理想做法,因为对于某些操作,Lustre 需要网络往返布局中的每个 OST,即使文件非常小,无法占用所有 OST 卷上的空间。
您可以设置渐进式文件布局(PFL),允许文件布局随大小变化。PFL 配置可以简化对具有大文件和小文件的文件系统的管理,而无需为每个文件明确设置配置。有关更多信息,请参阅 渐进式文件布局。
默认情况下,条带大小为 1MiB。在特殊情况下,设置条带偏移量可能很有用,但一般而言,最好不指定条带偏移量并使用默认值。
渐进式文件布局
您可以为目录指定渐进式文件布局(PFL)配置,以便在填充目录前为小文件和大文件指定不同的条带配置。例如,您可以在将任何数据写入新文件系统前,在顶级目录上设置 PFL。
要指定 PFL 配置,请使用 lfs setstripe 命令和 -E 选项为不同大小的文件指定布局组件,例如以下命令:
lfs setstripe -E 100M -c 1 -E 10G -c 8 -E 100G -c 16 -E -1 -c 32/mountname/directory
此命令设置了四个布局组件:
第一个组件(
-E 100M -c 1)表示大小不超过 100MiB 的文件的条带计数值为 1。第二个组件(
-E 10G -c 8)表示大小不超过 10GiB 的文件的条带计数为 8。第三个组件(
-E 100G -c 16)表示大小不超过 100GiB 的文件的条带计数为 16。第四个组件(
-E -1 -c 32)表示大于 100GiB 的文件的条带计数为 32。
重要
向使用 PFL 布局创建的文件追加数据会填充其所有布局组件。例如,使用上述 4 组件命令,如果创建一个 1MiB 文件,然后在文件末尾添加数据,则该文件的布局将扩展,条带计数为 -1,即系统中的所有 OST。这并不意味着数据会被写入每个 OST,但是读取文件长度之类的操作会并行向每个 OST 发送请求,从而给文件系统增加巨大的网络负载。
因此,对于任何随后可能追加数据的任何中小长度文件,请注意限制其条带计数。由于日志文件通常通过追加新记录增长,因此适用于 Lustre 的 Amazon FSx 会为在追加模式下创建的任何文件分配默认条带计数 1,无论其父目录指定的默认条带配置如何。
2023 年 8 月 25 日后创建的适用于 Lustre 的 Amazon FSx 文件系统的默认 PFL 配置使用以下命令设置:
lfs setstripe -E 100M -c 1 -E 10G -c 8 -E 100G -c 16 -E -1 -c 32/mountname
如果客户的工作负载对中型和大型文件进行高度并发访问,则采用以下布局客户可能会获益:小文件设置较多条带,而最大的文件跨所有 OST 进行条带化,如上述四组件示例布局所示。
监控性能和使用情况
每分钟,Amazon FSx for Lustre 都会向亚马逊发布每个磁盘(MDT 和 OST)的使用率指标。 CloudWatch
要查看聚合文件系统使用情况的详细信息,可以查看每个指标的 Sum 统计数据。例如,DataReadBytes 统计数据的 Sum 会报告文件系统中所有 OST 的总读取吞吐量。同样,FreeDataStorageCapacity 统计数据 Sum 会报告文件系统中文件数据的总可用存储容量。
有关监控文件系统性能的更多信息,请参阅监控 Amazon FSx for Lustre 文件系统。