本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
导出支持的 Amazon Web Services 云 目标的配置
用户定义的 Greengrass 组件在流管理器 SDK 中使用 StreamManagerClient 与流管理器交互。当组件创建流或更新流时,它会传递一个表示流属性的 MessageStreamDefinition 对象,包括导出定义。ExportDefinition 对象包含为流定义的导出配置。流管理器使用这些导出配置来确定将流导出到何处以及如何导出。
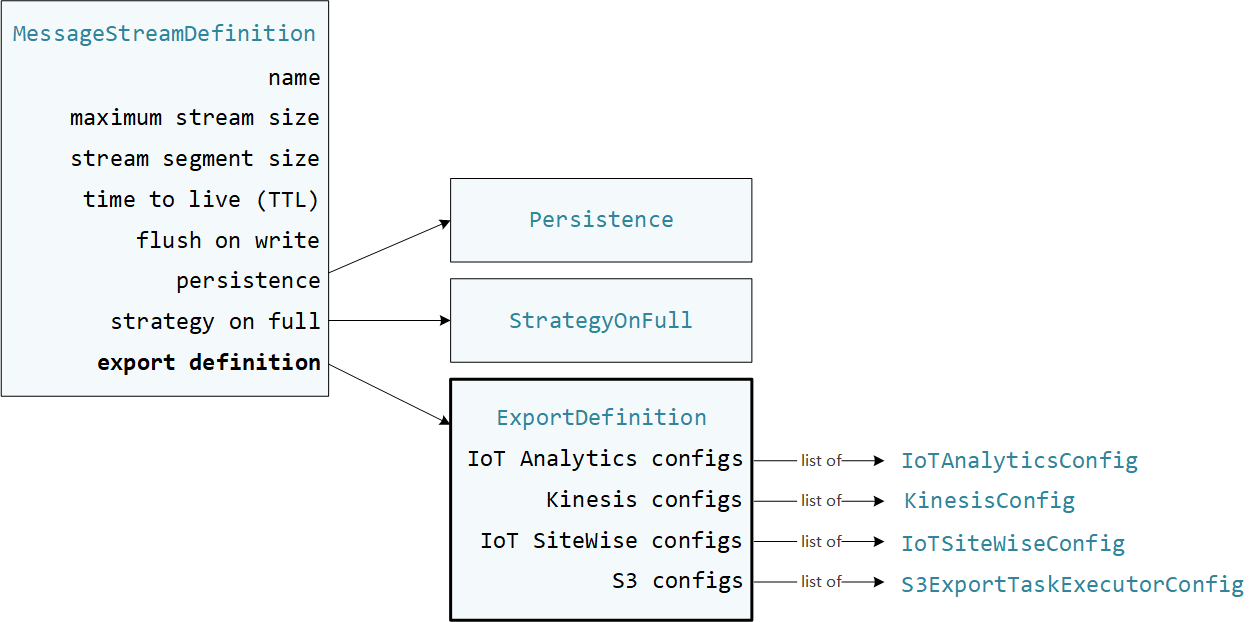
您可以为一个流定义零个或多个导出配置,包括针对单个目标类型的多个导出配置。例如,您可以将一个流导出到两个 Amazon IoT Analytics 通道和一个 Kinesis 数据流。
对于失败的导出尝试,流管理器会持续重试将数据导出到,间隔不超过五分钟。 Amazon Web Services 云 重试次数没有最大限制。
注意
StreamManagerClient 还提供了一个可用于将流导出到 HTTP 服务器的目标。此目标仅用于测试目的。其不稳定,或不支持在生产环境中使用。
支持的 Amazon Web Services 云 目的地
您有责任维护这些 Amazon Web Services 云 资源。
Amazon IoT Analytics 频道
直播管理器支持自动导出到 Amazon IoT Analytics。 Amazon IoT Analytics 允许您对数据进行高级分析,以帮助做出业务决策和改进机器学习模型。有关更多信息,请参阅什么是 Amazon IoT Analytics? 在《Amazon IoT Analytics 用户指南》中。
在流管理器 SDK 中,您的 Greengrass 组件使用 IoTAnalyticsConfig 来定义此目标类型的导出配置。有关更多信息,请参阅目标语言的开发工具包参考:
-
Python SDK 中的 Io TAnalytics Config
-
Java SDK 中的 Io TAnalytics Config
-
Node.js SDK 中的 Io TAnalytics Config
要求
此导出目的地具有以下要求:
-
中的目标频道 Amazon IoT Analytics 必须与 Greengrass 核心设备相同 Amazon Web Services 账户 。 Amazon Web Services 区域
-
授权核心设备与 Amazon 服务交互 必须允许对目标通道的
iotanalytics:BatchPutMessage权限。例如:您可以授予对资源的具体或条件访问权限(例如,通过使用通配符
*命名方案)。有关更多信息,请参阅 IAM 用户指南中的添加和删除 IAM policy。
导出到 Amazon IoT Analytics
要创建导出到的流 Amazon IoT Analytics,Greengrass 组件会创建一个包含一个或多个对象的导出定义的流。IoTAnalyticsConfig此对象定义导出设置,例如目标频道、批次大小、批次间隔和优先级。
当您的 Greengrass 组件从设备接收数据时,它们会将包含大量数据的消息附加到目标流。
然后,流管理器根据流的导出配置中定义的批处理设置和优先级导出数据。
Amazon Kinesis data streams
流管理器支持自动导出到 Amazon Kinesis Data Streams。Kinesis Data Streams 通常用于聚合大量数据并将其加载到数据仓库 MapReduce 或集群中。有关更多信息,请参阅 Amazon Kinesis 开发人员指南中的什么是 Amazon Kinesis Data Streams?。
在流管理器 SDK 中,您的 Greengrass 组件使用 KinesisConfig 来定义此目标类型的导出配置。有关更多信息,请参阅目标语言的开发工具包参考:
-
KinesisConfig
在 Python 软件开发工具包中 -
KinesisConfig
在 Java 开发工具包中 -
KinesisConfig
在 Node.js SDK 中
要求
此导出目的地具有以下要求:
-
Kinesis Data Streams 中的目标流必须与 Greengrass 核心设备 Amazon Web Services 账户 相同 Amazon Web Services 区域 。
-
(推荐)流管理器 v2.2.1 提高了将流导出至 Kinesis Data Streams 目的地的性能。要使用该最新版本中的改进之处,请将流管理器组件升级至 v2.2.1,然后使用 Greengrass 令牌交换角色中的
kinesis:ListShards策略。 -
授权核心设备与 Amazon 服务交互 必须允许对数据流的
kinesis:PutRecords权限。例如:您可以授予对资源的具体或条件访问权限(例如,通过使用通配符
*命名方案)。有关更多信息,请参阅 IAM 用户指南中的添加和删除 IAM policy。
导出到 Kinesis Data Streams
为创建导出到 Kinesis Data Streams 的流,您的 Greengrass 组件会使用包含一个或多个 KinesisConfig 对象的导出定义创建流。此对象定义导出设置,例如目标数据流、批次大小、批次间隔和优先级。
当您的 Greengrass 组件从设备接收数据时,它们会将包含大量数据的消息附加到目标流。然后,流管理器根据流的导出配置中定义的批处理设置和优先级导出数据。
流管理器会为上传到 Amazon Kinesis 的每条记录生成一个唯一的随机 UUID 作为分区键。
Amazon IoT SiteWise 资产属性
直播管理器支持自动导出到 Amazon IoT SiteWise。 Amazon IoT SiteWise 允许您大规模收集、组织和分析来自工业设备的数据。有关更多信息,请参阅什么是 Amazon IoT SiteWise? 在《Amazon IoT SiteWise 用户指南》中。
在流管理器 SDK 中,您的 Greengrass 组件使用 IoTSiteWiseConfig 来定义此目标类型的导出配置。有关更多信息,请参阅目标语言的开发工具包参考:
注意
Amazon 还提供了 Amazon IoT SiteWise 组件,这些组件提供了一个预先构建的解决方案,可用于流式传输来自 OPC-UA 来源的数据。有关更多信息,请参阅 物联网 SiteWise OPC UA 采集器。
要求
此导出目的地具有以下要求:
-
中的目标资产属性 Amazon IoT SiteWise 必须与 Greengrass 核心设备相同 Amazon Web Services 账户 。 Amazon Web Services 区域
注意
有关 Amazon IoT SiteWise 支持的列表,请参阅《 Amazon Web Services 区域Amazon 一般参考》中的Amazon IoT SiteWise 终端节点和配额。
-
授权核心设备与 Amazon 服务交互 必须允许对目标资产属性的
iotsitewise:BatchPutAssetPropertyValue权限。以下示例策略使用iotsitewise:assetHierarchyPath条件键来授予对目标根资产及其子项的访问权限。您可以Condition从策略中删除,以允许访问您的所有 Amazon IoT SiteWise 资产或指定单个 ARNs 资产。您可以授予对资源的具体或条件访问权限(例如,通过使用通配符
*命名方案)。有关更多信息,请参阅 IAM 用户指南中的添加和删除 IAM policy。有关重要的安全信息,请参阅《Amazon IoT SiteWise 用户指南》中的 BatchPutAssetPropertyValue 授权。
导出到 Amazon IoT SiteWise
要创建导出到的流 Amazon IoT SiteWise,Greengrass 组件会创建一个包含一个或多个对象的导出定义的流。IoTSiteWiseConfig此对象定义导出设置,例如批次大小、批次间隔和优先级。
当您的 Greengrass 组件从设备接收资产属性数据时,它们会将包含数据的消息附加到目标流。消息是 JSON 序列化的 PutAssetPropertyValueEntry 对象,其中包含一个或多个资产属性的属性值。有关更多信息,请参阅为 Amazon IoT SiteWise
导出目标追加消息。
注意
当您向发送数据时 Amazon IoT SiteWise,您的数据必须满足BatchPutAssetPropertyValue操作的要求。有关更多信息,请参阅《Amazon IoT SiteWise API Reference》中的 BatchPutAssetPropertyValue。
然后,流管理器根据流的导出配置中定义的批处理设置和优先级导出数据。
您可以调整流管理器设置和 Greengrass 组件逻辑来设计您的导出策略。例如:
-
对于近乎实时的导出,请设置较低的批量大小和间隔设置,并在收到数据时将数据追加到流中。
-
为了优化批处理、缓解带宽限制或最大限度地降低成本,Greengrass 组件可以在 timestamp-quality-value将数据追加到流之前,为单个资产属性汇集接收到的 (TQV) 数据点。一种策略是在一条消息中批量输入多达 10 种不同的财产资产组合或属性别名,而不是为同一个属性发送多个条目。这有助于流管理器保持在Amazon IoT SiteWise 配额范围内。
Amazon S3 对象
流管理器支持自动导出到 Amazon S3。您可以使用 Amazon S3 存储和检索大量的数据。有关更多信息,请参阅 Amazon Simple Storage Service 开发人员指南中的什么是 Amazon S3?。
在流管理器 SDK 中,您的 Greengrass 组件使用 S3ExportTaskExecutorConfig 来定义此目标类型的导出配置。有关更多信息,请参阅目标语言的开发工具包参考:
要求
此导出目的地具有以下要求:
-
目标 Amazon S3 存储桶必须与 Greengrass 核心设备 Amazon Web Services 账户 相同。
-
如果在 Greengrass 容器模式下运行的 Lambda 函数将输入文件写入输入文件目录,您必须将该目录作为卷挂载到具有写入权限的容器中。这样可以确保将文件写入根文件系统,并对容器外部运行的流管理器组件可见。
-
如果 Docker 容器组件将输入文件写入输入文件目录,您必须将该目录作为卷挂载到具有写入权限的容器中。这样可以确保将文件写入根文件系统,并对容器外部运行的流管理器组件可见。
-
授权核心设备与 Amazon 服务交互 必须允许对目标存储桶具有以下权限。例如:
您可以授予对资源的具体或条件访问权限(例如,通过使用通配符
*命名方案)。有关更多信息,请参阅 IAM 用户指南中的添加和删除 IAM policy。
导出到 Amazon S3
为创建导出到 Amazon S3 的流,您的 Greengrass 组件使用 S3ExportTaskExecutorConfig 对象来配置导出策略。该策略定义了导出设置,例如分段上传阈值和优先级。对于 Amazon S3 导出,流管理器会上传它从核心设备上的本地文件中读取的数据。要启动上传,您的 Greengrass 组件会将导出任务附加到目标流。导出任务包含有关输入文件和目标 Amazon S3 对象的信息。流管理器按照任务附加到流中的顺序运行任务。
注意
目标存储桶必须已经存在于您的中 Amazon Web Services 账户。如果指定密钥的对象不存在,则流管理器会为您创建该对象。
Stream Manager 使用分段上传阈值属性、最小分段大小设置和输入文件的大小来确定如何上传数据。分段上传阈值必须大于或等于最小分段大小。如果要并行上传数据,则可以创建多个流。
指定您的目标 Amazon S3 对象的密钥可以在!{timestamp:占位符中包含有效的 Java DateTimeFormattervalue}my-key/2020/12/31/data.txt 之类的值。
my-key/!{timestamp:YYYY}/!{timestamp:MM}/!{timestamp:dd}/data.txt
注意
如果要监控流的导出状态,请先创建一个状态流,然后将导出流配置为使用该状态流。有关更多信息,请参阅 监控导出任务。
管理输入数据
您可以编写代码,供物联网应用用来管理输入数据的生命周期。以下示例工作流程显示了如何使用 Greengrass 组件来管理这些数据。
-
本地进程从设备或外围设备接收数据,然后将数据写入核心设备上目录中的文件。这些是流管理器的输入文件。
-
Greengrass 组件会扫描该目录,并在创建新文件时将导出任务附加到目标流。该任务是一个 JSON 序列化
S3ExportTaskDefinition对象,用于指定输入文件的 URL、目标 Amazon S3 存储桶和密钥以及可选的用户元数据。 -
流管理器读取输入文件并按照附加任务的顺序将数据导出到 Amazon S3。目标存储桶必须已经存在于您的中 Amazon Web Services 账户。如果指定密钥的对象不存在,则流管理器会为您创建该对象。
-
Greengrass 组件从状态流读取消息以监控导出状态。导出任务完成后,Greengrass 组件可以删除相应的输入文件。有关更多信息,请参阅 监控导出任务。
监控导出任务
您可以编写代码,让物联网应用程序监控您的 Amazon S3 导出状态。您的 Greengrass 组件必须创建状态流,然后配置导出流以将状态更新写入状态流。单个状态流可以接收来自导出到 Amazon S3 的多个流的状态更新。
首先,创建一个流以用作状态流。您可以为流配置大小和保留策略,以控制状态消息的生命周期。例如:
-
如果您不想存储状态消息,请将
Persistence设置为Memory。 -
将
StrategyOnFull设置为OverwriteOldestData,这样新的状态消息就不会丢失。
然后,创建或更新导出流以使用状态流。具体而言,设置流 S3ExportTaskExecutorConfig 导出配置的状态配置属性。此设置会告诉流管理器将有关导出任务的状态消息写入状态流。在 StatusConfig 对象中,指定状态流的名称和详细程度。以下支持的值范围从最低 verbose (ERROR) 到最长 verbose (TRACE) 不等。默认值为 INFO。
-
ERROR -
WARN -
INFO -
DEBUG -
TRACE
以下示例工作流程显示了 Greengrass 组件如何使用状态流来监控导出状态。
-
如前面的工作流程所述,Greengrass 组件将导出任务附加到流,后者配置为将有关导出任务的状态消息写入状态流。附加操作返回一个表示任务 ID 的序列号。
-
Greengrass 组件按顺序读取状态流中的消息,然后根据流名称和任务 ID 或消息上下文中的导出任务属性筛选消息。例如,Greengrass 组件可以按导出任务的输入文件 URL 进行筛选,该文件由消息上下文中的
S3ExportTaskDefinition对象表示。以下状态代码指示导出任务已达到完成状态:
-
Success。上传已成功完成。 -
Failure。流管理器遇到错误,例如,指定的存储桶不存在。解决问题后,您可以再次将导出任务追加到流中。 -
Canceled。 由于流或导出定义已删除,或者任务的 time-to-live (TTL) 期限已过期,该任务已停止。
注意
该任务的状态也可能为
InProgress或Warning。当事件返回不影响任务执行的错误时,流管理器会发出警告。例如,如果无法清理部分上传,则会返回警告。 -
-
导出任务完成后,Greengrass 组件可以删除相应的输入文件。
以下示例显示 Greengrass 组件如何读取和处理状态消息。