经过仔细考虑,我们决定停用适用于 SQL 应用程序的 Amazon Kinesis Data Analytics:
1. 从 2025年9月1日起,我们将不再为适用于SQL应用程序的Amazon Kinesis Data Analytics Data Analytics提供任何错误修复,因为鉴于即将停产,我们对其的支持将有限。
2. 从 2025 年 10 月 15 日起,您将无法为 SQL 应用程序创建新的 Kinesis Data Analytics。
3. 从 2026 年 1 月 27 日起,我们将删除您的应用程序。您将无法启动或操作 Amazon Kinesis Data Analytics for SQL 应用程序。从那时起,将不再提供对 Amazon Kinesis Data Analytics for SQL 的支持。有关更多信息,请参阅 Amazon Kinesis Data Analytics for SQL 应用程序停用。
本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
使用架构编辑器
Amazon Kinesis Data Analytics 应用程序输入流的架构定义了如何为应用程序中的 SQL 查询提供流中的数据。
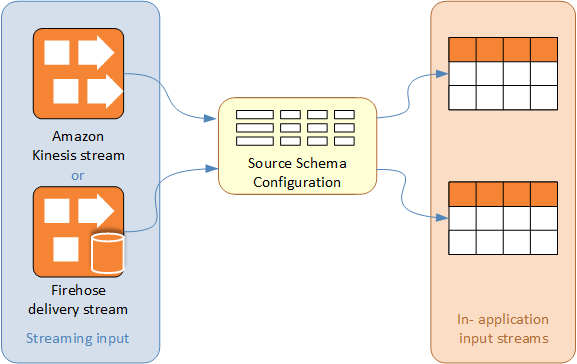
架构包含选择条件,用于确定哪部分流输入将转换为应用程序内部输入流中的数据列。此输入可以是以下项之一:
JSON 输入流的 JSONPath 表达式。JSONPath 是用于查询 JSON 数据的工具。
输入流的列编号 (逗号分隔值 (CSV) 格式)。
列名称和用于在应用程序内数据流中呈现数据的 SQL 数据类型。该数据类型还包含字符或二进制数据的长度。
控制台将尝试使用 DiscoverInputSchema 生成架构。如果架构发现失败或返回了不正确或不完整的架构,您必须使用架构编辑器手动编辑架构。
架构编辑器主屏幕
以下屏幕截图显示了架构编辑器的主屏幕。
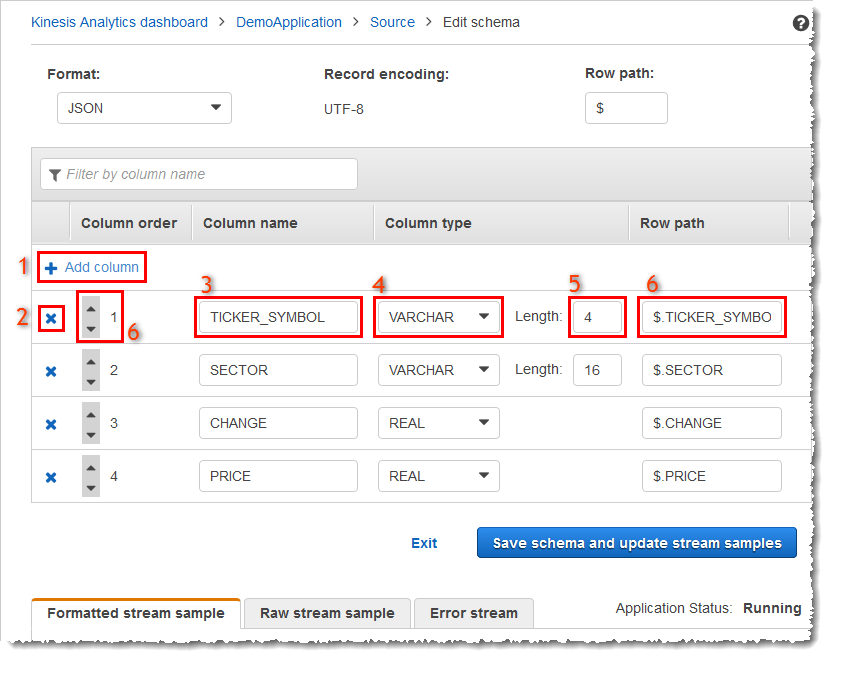
您可以将下列编辑应用于架构:
添加列 (1):如果未自动检测到数据项,您可能需要添加数据列。
删除列 (2):如果您的应用程序不需要源流中的数据,您可以排除该数据。此排除不会影响源流中的数据。排除数据后,数据将不可供应用程序使用。
重命名列 (3)。列名称不能为空,长度必须超过一个字符,并且不得包含保留的 SQL 关键字。该名称还必须符合 SQL 普通标识符的命名标准:名称必须以字母开头,并且只包含字母、下划线字符和数字。
更改列的数据类型 (4) 或长度 (5):您可以为列指定兼容的数据类型。如果您指定了不兼容的数据类型,则将使用 NULL 填充列或完全不填充应用程序内部流。在后一种情况下,错误将写入到错误流。如果您为列指定的长度太小,传入数据将被截断。
更改列的选择条件 (6):您可以编辑用于确定列中数据源的 JSONPath 表达式或 CSV 列顺序。要更改 JSON 架构的选择条件,请为行路径表达式输入新值。CSV 架构将使用列顺序作为选择条件。要更改 CSV 架构的选择条件,请更改列的顺序。
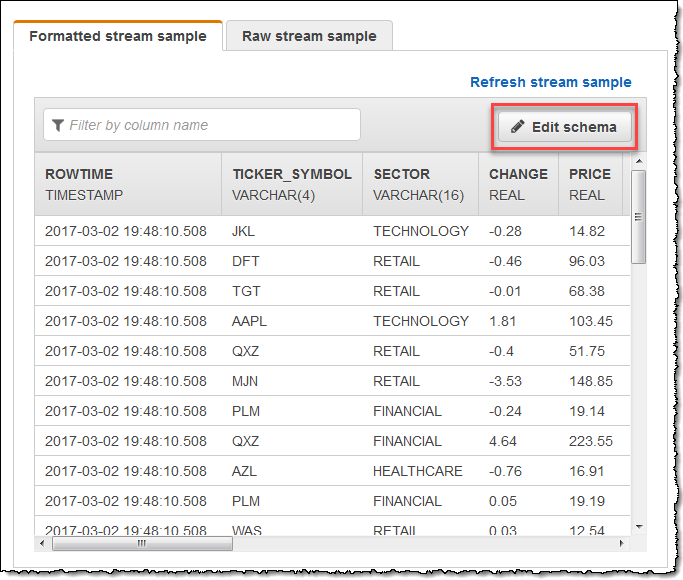
编辑流式传输源的架构
如果您需要编辑流式传输源的架构,请按照以下步骤操作。
编辑流式传输源的架构
在 Source 页上,选择 Edit schema。
在 Edit schema 页上,编辑源架构。
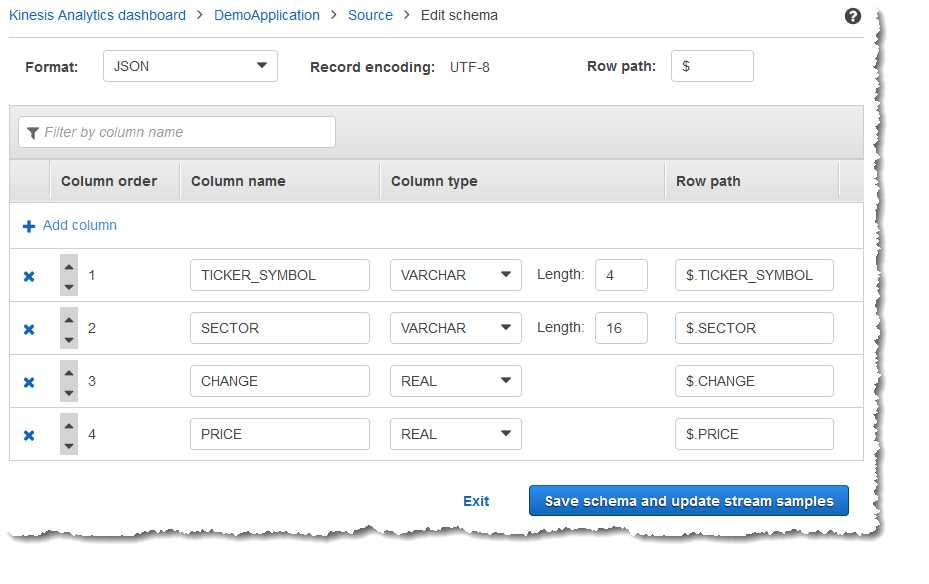
对于 Format,选择 JSON 或 CSV。对于 JSON 或 CSV 格式,支持的编码为 ISO 8859-1。
有关编辑 JSON 或 CSV 格式的架构的更多信息,请参阅后续章节中的过程。
编辑 JSON 架构
您可以通过以下步骤编辑 JSON 架构。
编辑 JSON 架构
在架构编辑器,选择 Add column 以添加列。
新列将显示在第一个列位置。要更改列顺序,请选择列名称旁边的向上和向下箭头。
对于新列,请提供以下信息:
对于 Column name,键入一个名称。
列名称不能为空,长度必须超过一个字符,并且不得包含保留的 SQL 关键字。它还必须符合 SQL 普通标识符的命名标准:必须以字母开头,并且只包含字母、下划线字符和数字。
对于 Column type,键入一个 SQL 数据类型。
列类型可以是任何受支持的 SQL 数据类型。如果新数据类型为 CHAR、VARBINARY 或 VARCHAR,请在 Length (长度) 中指定数据长度。有关更多信息,请参阅数据类型。
对于 Row path,提供一个行路径。行路径是映射到 JSON 元素的有效 JSONPath 表达式。
注意
基础 Row path 值是指向包含要将数据导入到的顶级父项的路径。默认情况下,此值为 $。有关更多信息,请参阅
JSONMappingParameters中的RecordRowPath。
要删除列,请选择列编号旁的 x 图标。
要重命名列,请在 Column name (列名) 中输入新名称。新列名称不能为空,长度必须超过一个字符,并且不得包含保留的 SQL 关键字。它还必须符合 SQL 普通标识符的命名标准:必须以字母开头,并且只包含字母、下划线字符和数字。
-
要更改列的数据类型,请在 列类型 中选择新数据类型。如果新数据类型为
CHAR、VARBINARY或VARCHAR,请在 Length (长度) 中指定数据长度。有关更多信息,请参阅数据类型。 -
选择 Save schema and update stream 以保存您的更改。
修改后的架构将显示在编辑器中,类似于以下内容。
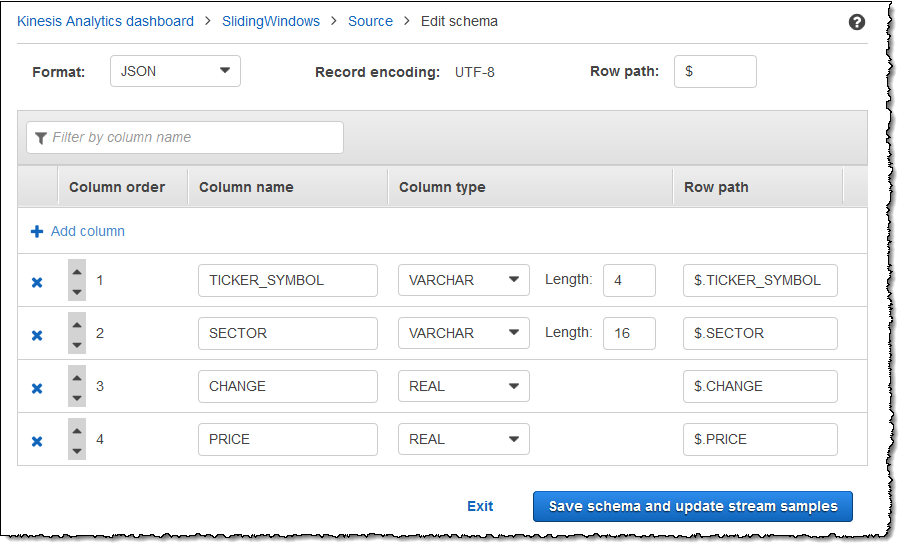
如果您的架构具有许多行,您可使用 Filter by column name 来筛选行。例如,要编辑以 P 开头的列名称 (如 Price 列),请在 PFilter by column name 框中输入 。
编辑 CSV 架构
您可通过以下步骤编辑 CSV 架构。
编辑 CSV 架构
在架构编辑器中,对于 Row delimiter,选择您的传入数据流使用的分隔符。这是您的流中数据记录之间的分隔符 (如换行符)。
对于 Column delimiter,选择您的传入数据流使用的分隔符。这是您的流中数据字段之间的分隔符 (如逗号)。
要添加列,请选择 Add column。
新列将显示在第一个列位置。要更改列顺序,请选择列名称旁边的向上和向下箭头。
对于新列,请提供以下信息:
对于 Column name (列名),输入一个名称。
列名称不能为空,长度必须超过一个字符,并且不得包含保留的 SQL 关键字。它还必须符合 SQL 普通标识符的命名标准:必须以字母开头,并且只包含字母、下划线字符和数字。
对于 Column type (列类型),输入一个 SQL 数据类型。
列类型可以是任何受支持的 SQL 数据类型。如果新数据类型为 CHAR、VARBINARY 或 VARCHAR,请在 Length (长度) 中指定数据长度。有关更多信息,请参阅数据类型。
要删除列,请选择列编号旁的 x 图标。
要重命名列,请在 Column name (列名) 中输入新名称。新列名称不能为空,长度必须超过一个字符,并且不得包含保留的 SQL 关键字。它还必须符合 SQL 普通标识符的命名标准:必须以字母开头,并且只包含字母、下划线字符和数字。
-
要更改列的数据类型,请在 列类型 中选择新数据类型。如果新数据类型为 CHAR、VARBINARY 或 VARCHAR,请在 Length (长度) 中指定数据长度。有关更多信息,请参阅数据类型。
-
选择 Save schema and update stream 以保存您的更改。
修改后的架构将显示在编辑器中,类似于以下内容。
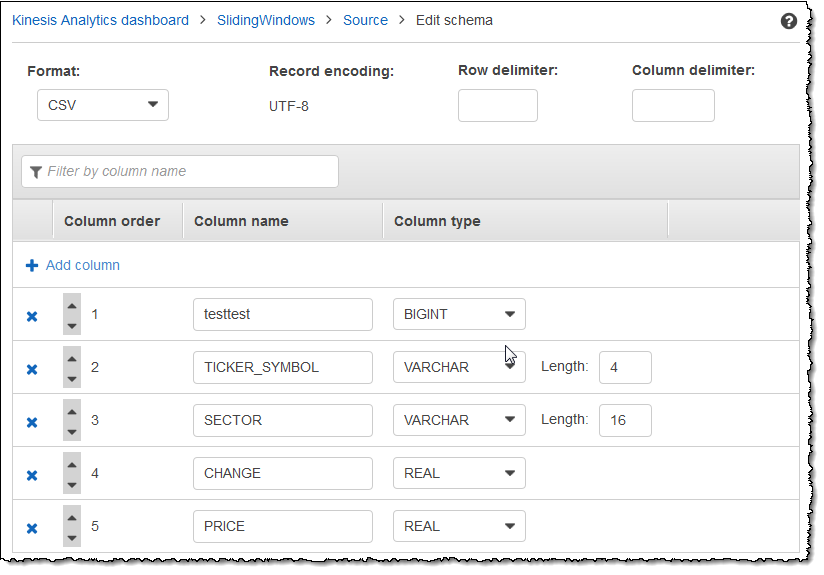
如果您的架构具有许多行,您可使用 Filter by column name 来筛选行。例如,要编辑以 P 开头的列名称 (如 Price 列),请在 PFilter by column name 框中输入 。