经过仔细考虑,我们决定停用适用于 SQL 应用程序的 Amazon Kinesis Data Analytics:
1. 从 2025年9月1日起,我们将不再为适用于SQL应用程序的Amazon Kinesis Data Analytics Data Analytics提供任何错误修复,因为鉴于即将停产,我们对其的支持将有限。
2. 从 2025 年 10 月 15 日起,您将无法为 SQL 应用程序创建新的 Kinesis Data Analytics。
3. 从 2026 年 1 月 27 日起,我们将删除您的应用程序。您将无法启动或操作 Amazon Kinesis Data Analytics for SQL 应用程序。从那时起,将不再提供对 Amazon Kinesis Data Analytics for SQL 的支持。有关更多信息,请参阅 Amazon Kinesis Data Analytics for SQL 应用程序停用。
本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
示例:将字符串拆分到多个字段 (VARIABLE_COLUMN_LOG_PARSE 函数)
此示例使用 VARIABLE_COLUMN_LOG_PARSE 函数在 Kinesis Data Analytics 中处理字符串列。VARIABLE_COLUMN_LOG_PARSE 将输入字符串拆分为多个字段,它们由分隔符或分隔符字符串分隔。有关更多信息,请参阅 Amazon Managed Service for Apache Flink SQL 参考中的 VARIABLE_COLUMN_LOG_PARSE。
在本示例中,您将半结构化记录写入到 Amazon Kinesis Data Stream 中。示例记录如下所示:
{ "Col_A" : "string", "Col_B" : "string", "Col_C" : "string", "Col_D_Unstructured" : "value,value,value,value"} { "Col_A" : "string", "Col_B" : "string", "Col_C" : "string", "Col_D_Unstructured" : "value,value,value,value"}
然后,您在控制台上创建一个 Kinesis Data Analytics 应用程序,并将 Kinesis 流作为流式传输源。发现过程读取流式传输源上的示例记录,并推断出具有四个列的应用程序内部架构,如下所示:
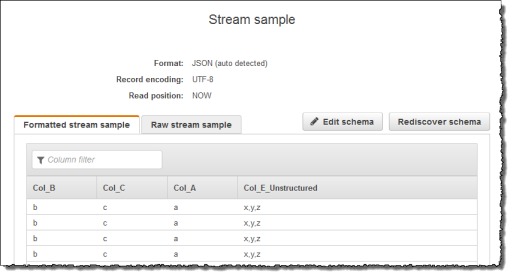
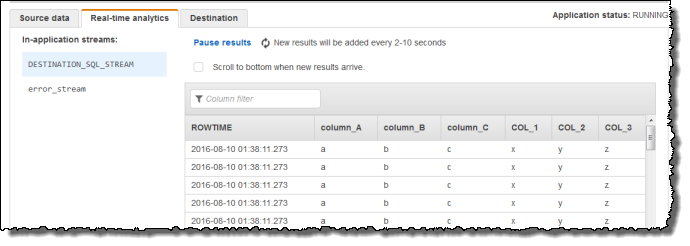
然后,您将使用应用程序代码和 VARIABLE_COLUMN_LOG_PARSE 函数解析逗号分隔的值,将规范化的行插入到其他应用程序内部流,如下所示:
步骤 1:创建 Kinesis 数据流
创建一个 Amazon Kinesis 数据流并填充日志记录,如下所示:
登录 Amazon Web Services 管理控制台 并在 /kinesis 上打开 Kinesis 控制台。https://console.aws.amazon.com
-
在导航窗格中,选择 数据流。
-
选择 创建 Kinesis 流,然后创建带有一个分片的流。有关更多信息,请参阅 Amazon Kinesis Data Streams 开发人员指南中的创建流。
-
运行以下 Python 代码以便填充示例日志记录。这段简单代码不断地将同一日志记录写入到流中。
import json import boto3 STREAM_NAME = "ExampleInputStream" def get_data(): return {"Col_A": "a", "Col_B": "b", "Col_C": "c", "Col_E_Unstructured": "x,y,z"} def generate(stream_name, kinesis_client): while True: data = get_data() print(data) kinesis_client.put_record( StreamName=stream_name, Data=json.dumps(data), PartitionKey="partitionkey" ) if __name__ == "__main__": generate(STREAM_NAME, boto3.client("kinesis"))
步骤 2:创建 Kinesis Data Analytics 应用程序
创建一个 Kinesis Data Analytics 应用程序,如下所示:
在 /kinesisanalytics 上打开适用于 Apache Flink 的托管服务控制台。 https://console.aws.amazon.com
-
选择 创建应用程序,键入应用程序名称,然后选择 创建应用程序。
-
在应用程序详细信息页面上,选择 连接流数据。
-
在 连接到源 页面上,执行以下操作:
-
选择在上一部分中创建的流。
-
选择创建 IAM 角色的选项。
-
选择 发现架构。等待控制台显示推断的架构和为创建的应用程序内部流推断架构所使用的示例记录。请注意推断的架构仅包含一列。
-
选择 保存并继续。
-
-
在应用程序详细信息页面上,选择 转到 SQL编辑器。要启动应用程序,请在显示的对话框中选择 是,启动应用程序。
-
在 SQL 编辑器中,编写应用程序代码并确认结果:
-
复制下面的应用程序代码并将其粘贴到编辑器中:
CREATE OR REPLACE STREAM "DESTINATION_SQL_STREAM"( "column_A" VARCHAR(16), "column_B" VARCHAR(16), "column_C" VARCHAR(16), "COL_1" VARCHAR(16), "COL_2" VARCHAR(16), "COL_3" VARCHAR(16)); CREATE OR REPLACE PUMP "SECOND_STREAM_PUMP" AS INSERT INTO "DESTINATION_SQL_STREAM" SELECT STREAM t."Col_A", t."Col_B", t."Col_C", t.r."COL_1", t.r."COL_2", t.r."COL_3" FROM (SELECT STREAM "Col_A", "Col_B", "Col_C", VARIABLE_COLUMN_LOG_PARSE ("Col_E_Unstructured", 'COL_1 TYPE VARCHAR(16), COL_2 TYPE VARCHAR(16), COL_3 TYPE VARCHAR(16)', ',') AS r FROM "SOURCE_SQL_STREAM_001") as t; -
选择 保存并运行 SQL。在 实时分析 选项卡上,可以查看应用程序已创建的所有应用程序内部流并验证数据。
-