经过仔细考虑,我们决定停用适用于 SQL 应用程序的 Amazon Kinesis Data Analytics:
1. 从 2025年9月1日起,我们将不再为适用于SQL应用程序的Amazon Kinesis Data Analytics Data Analytics提供任何错误修复,因为鉴于即将停产,我们对其的支持将有限。
2. 从 2025 年 10 月 15 日起,您将无法为 SQL 应用程序创建新的 Kinesis Data Analytics。
3. 从 2026 年 1 月 27 日起,我们将删除您的应用程序。您将无法启动或操作 Amazon Kinesis Data Analytics for SQL 应用程序。从那时起,将不再提供对 Amazon Kinesis Data Analytics for SQL 的支持。有关更多信息,请参阅 Amazon Kinesis Data Analytics for SQL 应用程序停用。
本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
交错窗口
使用交错窗口 是一种窗口化方法,适用于分析到达时间不一致的数据组。这种方法非常适合任何时间序列分析使用案例,例如一组相关的销售或日志记录。
例如,VPC 流日志具有一个大约 10 分钟的捕获窗口。但是,如果您在客户端上聚合数据,则最多可以具有 15 分钟的捕获窗口。交错窗口非常适合用于聚合这些日志进行分析。
交错窗口解决了多条相关记录不属于同一时间限制窗口的问题,例如在使用了滚动窗口的情况下。
滚动窗口的部分结果
使用滚动窗口聚合延迟或无序数据具有某些限制。
如果使用滚动窗口来分析与时间相关的多组数据,则个别记录可能属于单独的窗口。因此,必须稍后组合每个窗口的部分结果,以便为每组记录生成完整的结果。
在以下滚动窗口查询中,记录按行时间、事件时间和股票代码分组为若干窗口:
CREATE OR REPLACE STREAM "DESTINATION_SQL_STREAM" ( TICKER_SYMBOL VARCHAR(4), EVENT_TIME timestamp, TICKER_COUNT DOUBLE); CREATE OR REPLACE PUMP "STREAM_PUMP" AS INSERT INTO "DESTINATION_SQL_STREAM" SELECT STREAM TICKER_SYMBOL, FLOOR(EVENT_TIME TO MINUTE), COUNT(TICKER_SYMBOL) AS TICKER_COUNT FROM "SOURCE_SQL_STREAM_001" GROUP BY ticker_symbol, FLOOR(EVENT_TIME TO MINUTE), STEP("SOURCE_SQL_STREAM_001".ROWTIME BY INTERVAL '1' MINUTE);
在下图中,应用程序根据交易发生的时间(事件时间)以一分钟的粒度计算它收到的交易数量。应用程序可以使用滚动窗口根据行时间和事件时间对数据进行分组。该应用程序接收四条记录,所有记录都在彼此的一分钟之内到达。它按行时间、事件时间和股票代码对记录进行分组。因为一些记录在第一个滚动窗口结束后到达,所以记录并非全部位于同一个一分钟的滚动窗口内。
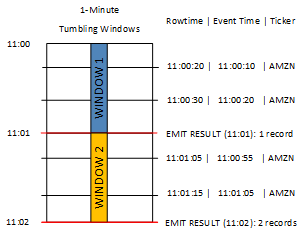
上图包含以下事件。
| ROWTIME | EVENT_TIME | TICKER_SYMBOL |
|---|---|---|
| 11:00:20 | 11:00:10 | AMZN |
| 11:00:30 | 11:00:20 | AMZN |
| 11:01:05 | 11:00:55 | AMZN |
| 11:01:15 | 11:01:05 | AMZN |
滚动窗口应用程序的结果集类似于以下内容。
| ROWTIME | EVENT_TIME | TICKER_SYMBOL | COUNT |
|---|---|---|---|
| 11:01:00 | 11:00:00 | AMZN | 2 |
| 11:02:00 | 11:00:00 | AMZN | 1 |
| 11:02:00 | 11:01:00 | AMZN | 1 |
在前面的结果集中,返回了三个结果:
ROWTIME为 11:01:00 的记录,它聚合前两个记录。11:02:00 的记录,它仅聚合第三条记录。此记录在第二个窗口中有一个
ROWTIME,但在第一个窗口中有一个EVENT_TIME。11:02:00 的记录,它仅聚合第四条记录。
要分析完整的结果集,必须在持久性存储中聚合记录。这给应用程序增加了复杂性和处理要求。
完整结果与交错窗口
为了提高分析与时间相关的数据记录的准确性,Kinesis Data Analytics 提供了一种名为交错窗口的新窗口类型。在此窗口类型中,窗口在与分区键匹配的第一个事件到达时打开,而不是在固定的时间间隔打开。窗口根据指定的期限关闭,期限是从窗口打开的时间开始计算的。
交错窗口是窗口子句中每个键分组的单独时间限制窗口。应用程序将窗口子句的每个结果聚合在其自己的时间窗口内,而不是对所有结果使用单个窗口。
在以下交错窗口查询中,记录按事件时间和股票代码分组为若干窗口:
CREATE OR REPLACE STREAM "DESTINATION_SQL_STREAM" ( ticker_symbol VARCHAR(4), event_time TIMESTAMP, ticker_count DOUBLE); CREATE OR REPLACE PUMP "STREAM_PUMP" AS INSERT INTO "DESTINATION_SQL_STREAM" SELECT STREAM TICKER_SYMBOL, FLOOR(EVENT_TIME TO MINUTE), COUNT(TICKER_SYMBOL) AS ticker_count FROM "SOURCE_SQL_STREAM_001" WINDOWED BY STAGGER ( PARTITION BY FLOOR(EVENT_TIME TO MINUTE), TICKER_SYMBOL RANGE INTERVAL '1' MINUTE);
在下图中,事件按事件时间和股票代码聚合到交错窗口中。
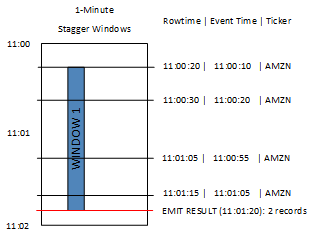
上图包含以下事件,这些事件与分析的滚动窗口应用程序相同:
| ROWTIME | EVENT_TIME | TICKER_SYMBOL |
|---|---|---|
| 11:00:20 | 11:00:10 | AMZN |
| 11:00:30 | 11:00:20 | AMZN |
| 11:01:05 | 11:00:55 | AMZN |
| 11:01:15 | 11:01:05 | AMZN |
交错窗口应用程序的结果集类似于以下内容。
| ROWTIME | EVENT_TIME | TICKER_SYMBOL | 计数 |
|---|---|---|---|
| 11:01:20 | 11:00:00 | AMZN | 3 |
| 11:02:15 | 11:01:00 | AMZN | 1 |
返回的记录聚合了前三条输入记录。记录按一分钟的交错窗口分组。当应用程序收到第一条 AMZN 记录(ROWTIME 为 11:00:20)时,交错窗口开始。当 1 分钟交错窗口到期时 (11:01:20),对于包含位于交错窗口内的结果(基于 ROWTIME 和 EVENT_TIME)的记录,将被写入输出流。使用交错窗口,在一分钟窗口内具有 ROWTIME 和 EVENT_TIME 的所有记录都将在单个结果中发出。
最后一条记录(其 EVENT_TIME 位于一分钟聚合之外)是单独聚合的。这是因为 EVENT_TIME 是用于将记录分成多个结果集的分区键之一,而第一个窗口的 EVENT_TIME 的分区键是 11:00。
交错窗口的语法在特殊子句 WINDOWED BY 中定义。对于流式处理聚合,使用此子句代替 GROUP BY 子句。该子句紧跟在可选的 WHERE 子句之后和 HAVING 子句之前。
交错窗口在 WINDOWED BY 子句中定义,并带有两个参数:分区键和窗口长度。分区键对传入的数据流进行分区,并定义窗口何时打开。当流中出现具有唯一分区键的第一个事件时,将打开一个交错窗口。在经过由窗口长度定义的固定时间段之后,交错窗口关闭。以下代码示例说明了此语法:
... FROM <stream-name> WHERE <... optional statements...> WINDOWED BY STAGGER( PARTITION BY <partition key(s)> RANGE INTERVAL <window length, interval> );