本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
Amazon S3 表格与 Amazon Glue Data Catalog 和的集成 Amazon Lake Formation
Amazon S3 表类数据存储服务提供专门针对分析工作负载进行优化的 S3 存储,可提高查询性能,同时降低成本。S3 表类数据存储服务中的数据存储在新的存储桶类型中:表存储桶,它将表存储为子资源。S3 表内置支持 Apache Iceberg 标准,让您可以使用 Apache Spark 等常用查询引擎轻松查询 Amazon S3 表类数据存储服务存储桶中的表格数据。
您可以 Amazon Glue Data Catalog 使用 IAM 访问控制或 IAM 和 Lake Formation 拨款将 Amazon S3 表格与以下各项集成:
-
IAM 访问控制:使用 IAM 策略来控制对 S3 表和数据目录的访问。在这种访问控制方法中,您需要具有 S3 表资源和数据目录对象的 IAM 权限才能访问资源。
-
Lake Formation 访问控制:除了 Amazon Glue IAM 权限外,还使用 Amazon Lake Formation 授权,通过数据目录控制对 S3 表的访问。在此模式下,委托人需要 IAM 权限才能与数据目录交互,而 Lake Formation 授权决定委托人可以访问哪些目录资源(数据库、表、列、行)。此模式支持粗粒度访问控制(数据库级和表级授权)和精细访问控制(列级和行级安全)。配置注册角色并启用凭证自动售出后,委托人不需要 S3 Tables IAM 权限,因为 Lake Formation 使用注册角色代表委托人出售证书。Lake Formation 访问控制还支持第三方分析引擎的凭证自动售出。
本节提供了在以下场景中配置集成的指导: Amazon Lake Formation
-
方案 A:您使用 IAM 访问控制集成了 S3 表和数据目录,现在计划使用 Amazon Lake Formation。请参阅 更改 S3 表格集成的访问控制,了解更多信息。
-
方案 B:您计划使用 Amazon Lake Formation 集成 S3 表和数据目录,但目前尚未将其集成到您的账户和区域中。从将 Amazon S3 表类数据存储服务目录与 Data Catalog 和 Lake Formation 集成的先决条件本节开始,然后按照启用 Amazon S3 表类数据存储服务集成。
-
方案 C:您使用集成了 S3 表和数据目录 Amazon Lake Formation ,现在计划使用 IAM。请参阅 更改 S3 表格集成的访问控制,了解更多信息。
确保按照将 S3 表与 Amazon 分析服务集成的步骤进行操作,以便您拥有访问 Amazon Glue Data Catalog 和您的表资源以及使用 Amazon 分析服务的相应权限。
主题
Data Catalog 和 Lake Formation 集成的工作原理
当您将 S3 表目录与 Data Catalog 和 Lake Formation 集成时, Amazon Glue 服务会在您的账户中特定于您的 Amazon Web Services 区域的默认数据目录中创建一个名为 s3tablescatalog 的联合目录。该集成按以下方式映射您的账户和联合目录 Amazon Web Services 区域 下的所有 Amazon S3 表存储桶资源:
Amazon S3 表类数据存储服务存储桶成为 Data Catalog 中的多级目录。
-
关联的 Amazon S3 命名空间在 Data Catalog 中注册为数据库。
-
表存储桶中的 Amazon S3 表类数据存储服务成为 Data Catalog 中的表。
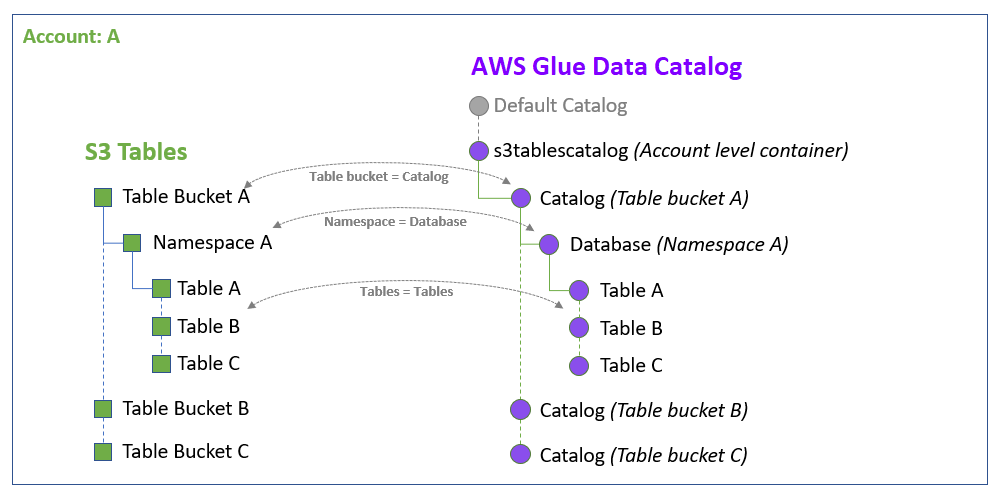
与 Lake Formation 集成后,您可以在表存储桶目录中创建 Apache Iceberg 表,并通过 Amazon Athena Amazon EMR 等集成 Amazon 分析引擎以及第三方分析引擎访问这些表。
当你同时启用带集成功能的 Lake Formation 时,它会通过实现细粒度的访问控制。 Amazon Lake Formation这种安全方法意味着,除了 Amazon Identity and Access Management (IAM) 权限外,您还必须向 IAM 委托人授予对您的表的 Lake Formation 权限,然后才能使用这些表。
Amazon Lake Formation中有两种主要类型的权限:
-
元数据访问权限控制着在数据目录中创建、读取、更新和删除元数据数据库和表的能力。
-
基础数据访问权限控制着对数据目录资源指向的基础 Amazon S3 位置读取和写入数据的能力。
Lake Formation 结合使用自己的权限模型和 IAM 权限模型,来控制对数据目录资源和基础数据的访问权限:
-
为了使访问数据目录资源或基础数据的请求取得成功,请求必须通过由 IAM 和 Lake Formation 进行的权限检查。
-
IAM 权限控制对 Lake Formation Amazon Glue APIs 和资源的访问,而 Lake Formation 权限控制对数据目录资源、Amazon S3 位置和底层数据的访问。
Lake Formation 权限仅适用于授予这些权限的区域,并且主体必须由数据湖管理员或其它具有必要权限的主体授权,才能获得 Lake Formation 权限。