本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
检查点
检查点是 Flink 的机制,用于确保应用程序的状态具有容错性。该机制允许 Flink 在任务失败时恢复运算符的状态,并为应用程序提供与无故障执行相同的语义。使用适用于 Apache Flink 的托管服务,应用程序的状态存储在 RocksDB 中,RocksDB 是一个嵌入式存 key/value 储,可将其工作状态保持在磁盘上。当使用检查点时,状态也会上传到 Amazon S3,因此,即使磁盘丢失,也可以使用该检查点来恢复应用程序状态。
有关更多信息,请参阅状态快照的工作原理?
通过检查点检验阶段
对于 Flink 中的检查点操作员子任务,有 5 个主要阶段:
等待 [开始延迟] — Flink 使用插入到直播中的检查点屏障,因此此阶段的时间是操作员等待检查点屏障到达的时间。
对齐 [对齐持续时间]-在此阶段,子任务已到达一个屏障,但它正在等待来自其他输入流的屏障。
Sync checkpointing [同步持续时间] — 此阶段是子任务实际捕捉操作员的状态并阻止子任务上的所有其他活动的时候。
异步检查点 [异步持续时间] — 此阶段的大部分时间是将状态上传到 Amazon S3 的子任务。在此阶段,子任务不再被阻止,可以处理记录。
确认 — 这通常是一个很短的阶段,只是子任务向发送确认 JobManager 并执行任何提交消息(例如使用 Kafka sinks)。
每个阶段(确认除外)都映射到 Flink WebUI 中提供的检查点的持续时间指标,这可以帮助找出长检查点的原因。
要查看检查点上每个可用指标的确切定义,请转到 “历史记录” 选项卡
正在调查
在调查较长的检查点持续时间时,要确定的最重要因素是检查点的瓶颈,即哪个操作员和子任务到达检查点的时间最长,以及该子任务的哪个阶段需要较长的时间。这可以通过任务检查点任务下的 Flink WebUI 来确定。Flink 的 Web 界面提供了有助于调查检查点问题的数据和信息。有关完整细分,请参阅监控检查点。
首先要看的是 Job 图表中每个操作员的端到端持续时间,以确定哪个操作员需要很长时间才能完成检查点并值得进一步调查。根据 Flink 文档,时长的定义是:
从触发时间戳到最近一次确认(或者 n/a 如果尚未收到确认)的持续时间。完整检查点的端到端持续时间由最后一个确认该检查点的子任务决定。这个时间通常比单个子任务实际检查状态所需的时间还要长。
检查点的其他持续时间也提供了有关时间花在何处的更精细的信息。
如果 “同步持续时间” 较高,则表示快照期间发生了某些事情。在此阶段snapshotState(),将调用实现 SnapshotState 接口的类;这可能是用户代码,因此线程转储可用于对此进行调查。
如果异步持续时间过长,则表明需要花费大量时间将状态上传到 Amazon S3。如果状态很大,或者正在上传的状态文件很多,则可能会发生这种情况。如果是这样的话,那么值得研究一下应用程序是如何使用状态的,并确保尽可能使用 Flink 原生数据结构(使用键控状态
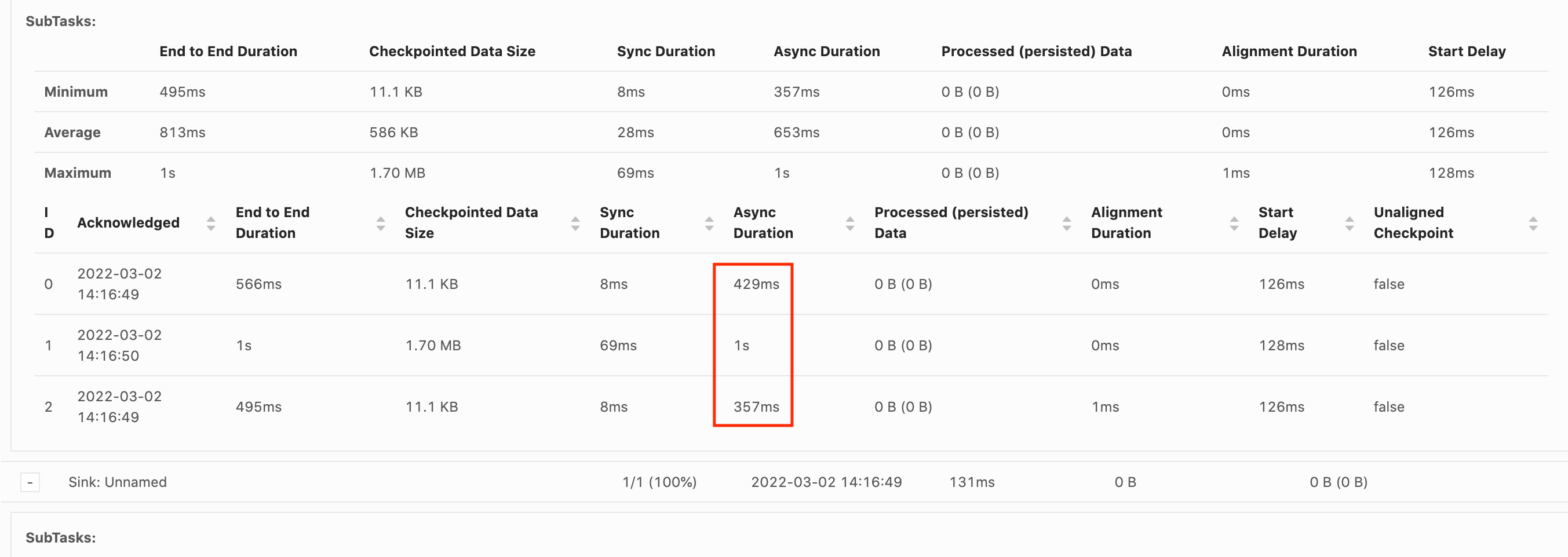
如果启动延迟过高,则表明大部分时间都花在等待检查点屏障到达操作员身上。这表明应用程序需要一段时间来处理记录,这意味着屏障正在缓慢地流过任务图。如果 Job 受到反压或者操作员经常忙碌,通常会出现这种情况。以下是第二个 KeyedProcess 操作员忙碌的示例。 JobGraph
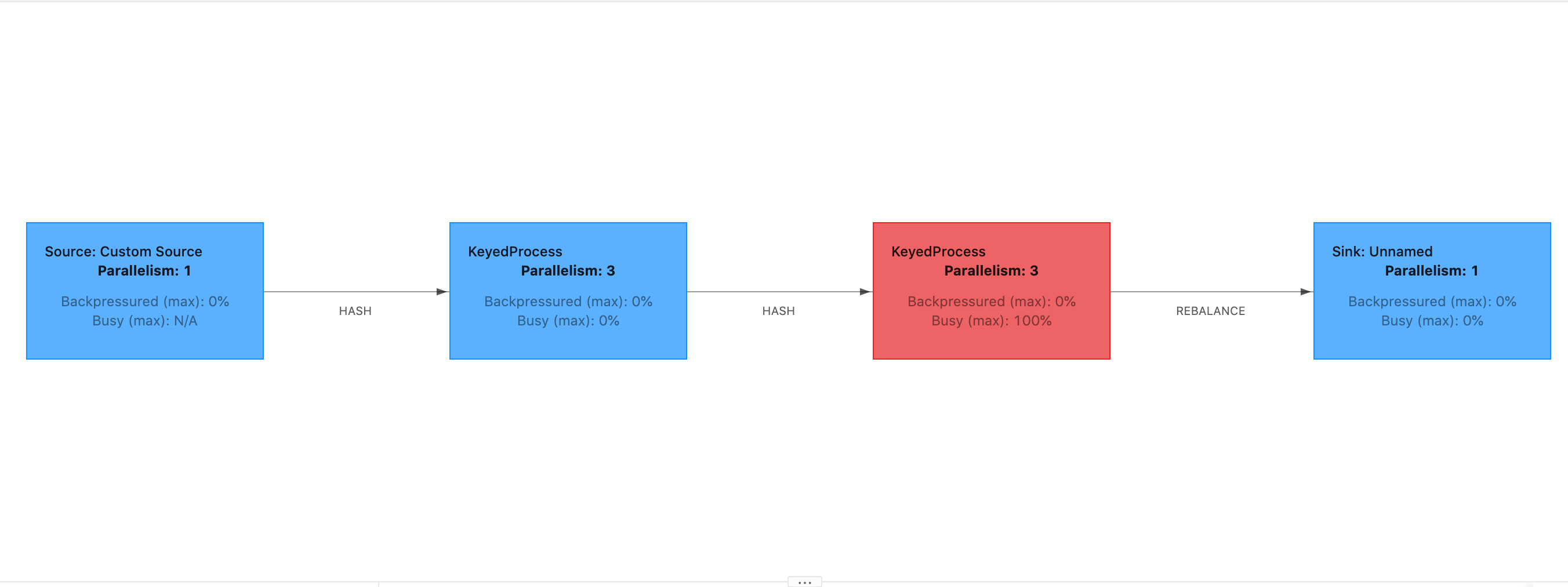
你可以使用 Flink Flame Graphs 或 TaskManager 话题转储来调查花了这么长时间的事情。一旦确定了瓶颈,就可以使用 thread-dumps Flame-graphs 或 thread-dumps 对其进行进一步调查。
线程转储
线程转储是另一种调试工具,其级别略低于火焰图。线程转储输出所有线程在某个时间点的执行状态。Flink 采用 JVM 线程转储,这是 Flink 进程中所有线程的执行状态。线程的状态由线程的堆栈跟踪以及一些其他信息来呈现。火焰图实际上是使用快速连续采集的多个堆栈轨迹来构建的。该图表是由这些轨迹制成的可视化效果,便于识别常见的代码路径。
"KeyedProcess (1/3)#0" prio=5 Id=1423 RUNNABLE at app//scala.collection.immutable.Range.foreach$mVc$sp(Range.scala:154) at $line33.$read$$iw$$iw$ExpensiveFunction.processElement(<console>>19) at $line33.$read$$iw$$iw$ExpensiveFunction.processElement(<console>:14) at app//org.apache.flink.streaming.api.operators.KeyedProcessOperator.processElement(KeyedProcessOperator.java:83) at app//org.apache.flink.streaming.runtime.tasks.OneInputStreamTask$StreamTaskNetworkOutput.emitRecord(OneInputStreamTask.java:205) at app//org.apache.flink.streaming.runtime.io.AbstractStreamTaskNetworkInput.processElement(AbstractStreamTaskNetworkInput.java:134) at app//org.apache.flink.streaming.runtime.io.AbstractStreamTaskNetworkInput.emitNext(AbstractStreamTaskNetworkInput.java:105) at app//org.apache.flink.streaming.runtime.io.StreamOneInputProcessor.processInput(StreamOneInputProcessor.java:66) ...
上面是从 Flink 用户界面中获取的单个线程的线程转储片段。第一行包含有关此线程的一些一般信息,包括:
话题名称 KeyedProcess (1/3) #0
线程的优先级 prio=5
一个唯一的线程Id Id =1423
线程状态可运行
线程的名称通常提供有关线程一般用途的信息。操作员线程可以通过其名称来识别,因为操作员线程与操作员线程具有相同的名称,并且可以指示它与哪个子任务有关,例如,KeyedProcess (1/3) #0 线程来自KeyedProcess运算符,来自第 1 个(共 3 个)子任务。
线程可能处于以下几种状态之一:
新增-线程已创建但尚未处理
RUNNABLE — 线程在 CPU 上执行
BLOCKED — 该线程正在等待另一个线程释放其锁定
等待-线程正在使用
wait()join()、或park()方法等待TIMED_WAITING — 线程正在使用睡眠、等待、加入或暂留方法等待,但等待时间最长。
注意
在 Flink 1.13 中,线程转储中单个堆栈跟踪的最大深度限制为 8。
注意
线程转储应该是调试 Flink 应用程序中性能问题的最后手段,因为线程转储可能难以读取,需要采集多个样本并进行手动分析。如果可能的话,最好使用火焰图。
Flink 中的线程转储了
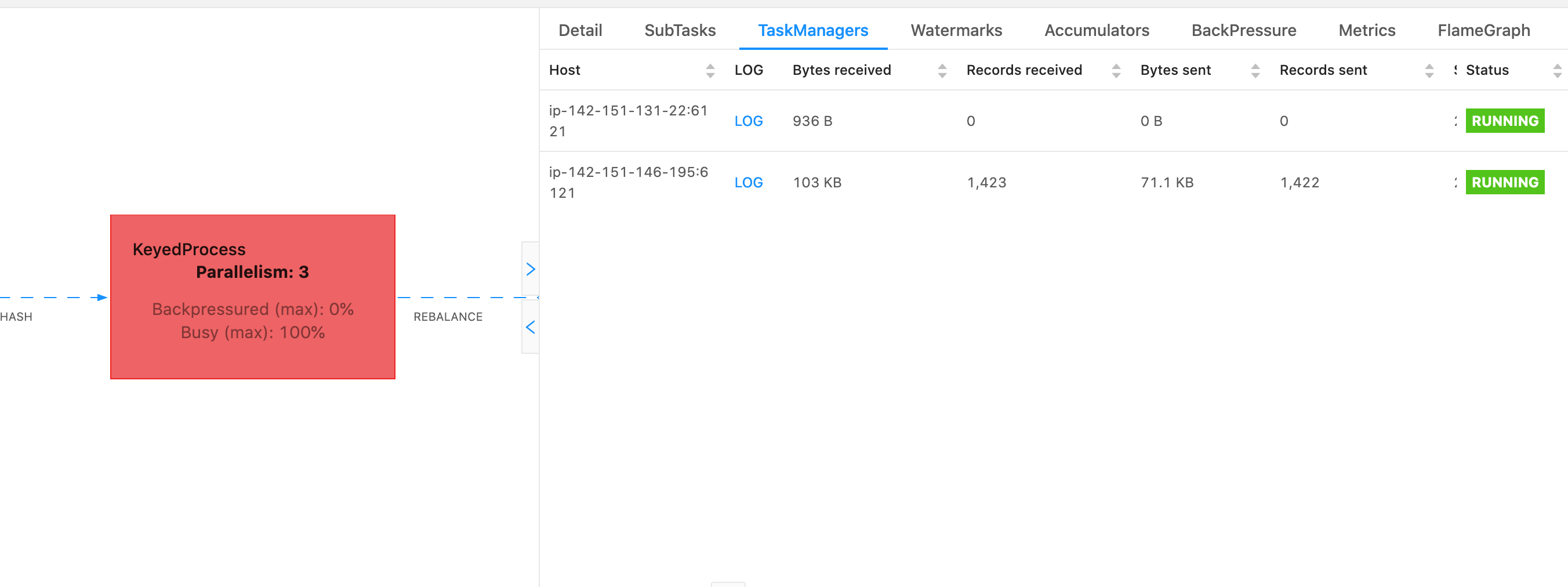
在 Flink 中,可以通过选择 Flink 用户界面左侧导航栏上的 “任务管理器” 选项,选择特定的任务管理器,然后导航到 “线程转储” 选项卡来进行线程转储。线程转储可以下载、复制到你最喜欢的文本编辑器(或线程转储分析器),也可以直接在 Flink Web UI 的文本视图中进行分析(但是,最后一个选项可能有点笨拙。
要确定要使用哪个任务管理器,可以在选择特定的运算符时使用该TaskManagers选项卡的线程转储。这表明操作员正在操作员的不同子任务上运行,并且可以在不同的任务管理器上运行。
转储将由多个堆栈跟踪组成。但是,在调查垃圾场时,与操作员相关的内容是最重要的。这些可以很容易地找到,因为操作员线程与操作员线程具有相同的名称,并且可以指示它与哪个子任务有关。例如,以下堆栈跟踪来自KeyedProcess操作员,并且是第一个子任务。
"KeyedProcess (1/3)#0" prio=5 Id=595 RUNNABLE at app//scala.collection.immutable.Range.foreach$mVc$sp(Range.scala:155) at $line360.$read$$iw$$iw$ExpensiveFunction.processElement(<console>:19) at $line360.$read$$iw$$iw$ExpensiveFunction.processElement(<console>:14) at app//org.apache.flink.streaming.api.operators.KeyedProcessOperator.processElement(KeyedProcessOperator.java:83) at app//org.apache.flink.streaming.runtime.tasks.OneInputStreamTask$StreamTaskNetworkOutput.emitRecord(OneInputStreamTask.java:205) at app//org.apache.flink.streaming.runtime.io.AbstractStreamTaskNetworkInput.processElement(AbstractStreamTaskNetworkInput.java:134) at app//org.apache.flink.streaming.runtime.io.AbstractStreamTaskNetworkInput.emitNext(AbstractStreamTaskNetworkInput.java:105) at app//org.apache.flink.streaming.runtime.io.StreamOneInputProcessor.processInput(StreamOneInputProcessor.java:66) ...
如果有多个同名的运算符,这可能会变得令人困惑,但我们可以命名运算符来解决这个问题。例如:
.... .process(new ExpensiveFunction).name("Expensive function")
火焰图
Flame graphs 是一种有用的调试工具,可以可视化目标代码的堆栈轨迹,从而可以识别最常见的代码路径。它们是通过对堆栈轨迹进行多次采样来创建的。火焰图的 x 轴显示不同的堆栈配置文件,而 y 轴显示堆栈深度以及堆栈跟踪中的调用。火焰图中的单个矩形表示堆栈框架,框架的宽度表示它在堆栈中出现的频率。有关火焰图及其使用方法的更多详细信息,请参阅火焰图
在 Flink 中,可以通过 Web UI 访问操作员的火焰图,方法是选择运算符,然后选择FlameGraph选项卡。收集到足够的样本后,将显示火焰图。以下是 FlameGraph ProcessFunction 检查点花了很多时间的。
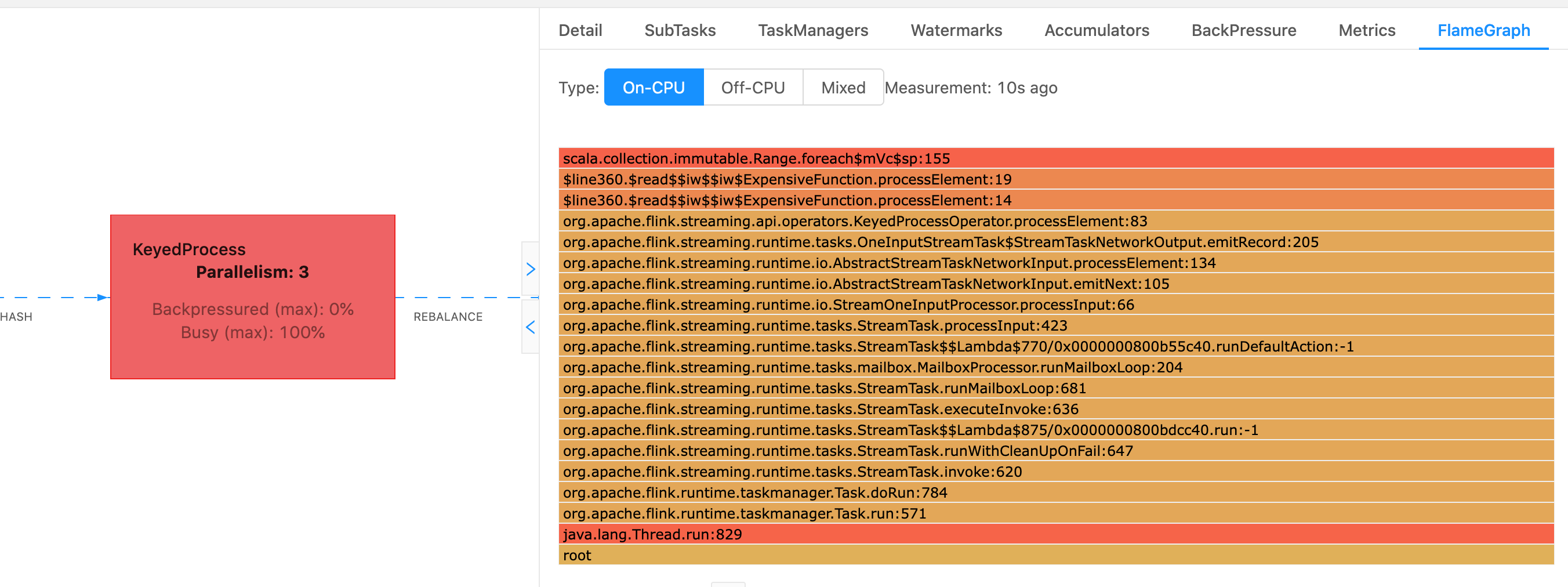
这是一个非常简单的火焰图,显示所有的 CPU 时间都花在 ExpensiveFunction 操作员内部的 foreach processElement 视图中。您还可以获得行号,以帮助确定代码执行的哪个位置。