本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
使用案例
以下是向量搜索使用案例。
检索增强生成(RAG)
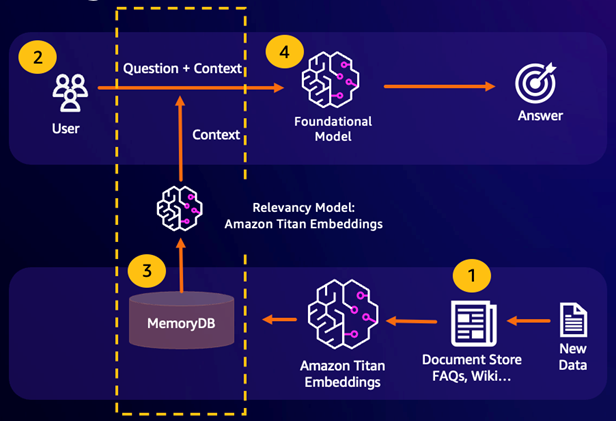
检索增强生成(RAG)利用向量搜索从大型数据语料库中检索相关段落,以增强大型语言模型(LLM)。具体而言,编码器会将输入上下文和搜索查询嵌入向量,然后使用近似的最近邻搜索找到语义相似段落。这些检索到的段落会与原始上下文连接在一起,为 LLM 提供额外相关信息,从而向用户返回更准确的响应。
持久语义缓存
语义缓存是通过存储来自 FM 的先前结果来降低计算成本的过程。通过重复使用先前推断的结果而不是重新计算这些结果,语义缓存减少了通过推理期间所需的计算量。 FMsMemoryDB 支持持久语义缓存,从而避免丢失过往推断的数据。这使您的生成式人工智能应用程序能够在几毫秒内响应,提供先前语义相似问题的答案,同时通过避免不必要的 LLM 推断来降低成本。
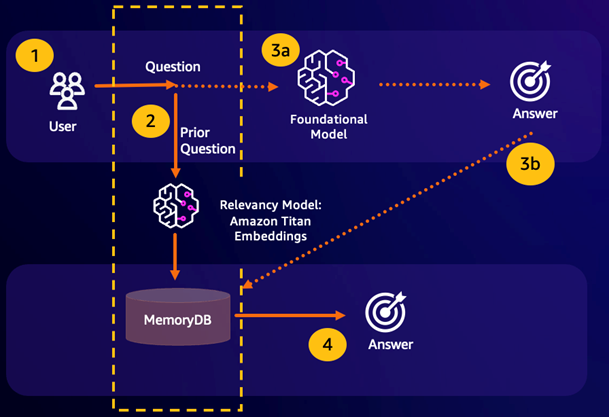
语义搜索命中 – 如果根据定义的相似度分数,客户的查询在语义上与前一个问题相似,FM 缓冲区内存(MemoryDB)会在第 4 步中返回前一个问题的答案,并且不会通过第 3 步调用 FM。这将避免基础模型(FM)延迟和相关成本,为客户提供更快的体验。
语义搜索未命中 – 如果根据定义的相似度分数,客户的查询在语义上与之前的查询不相似,则客户将在第 3a 步中调用 FM 提供对客户的响应。然后,从 FM 生成的响应将作为向量存储到 MemoryDB 中,供将来的查询使用(第 3b 步),以最大限度地降低语义相似问题上的 FM 成本。在此流程中,由于原始查询没有语义上相似的问题,因此不会调用第 4 步。
欺诈侦测
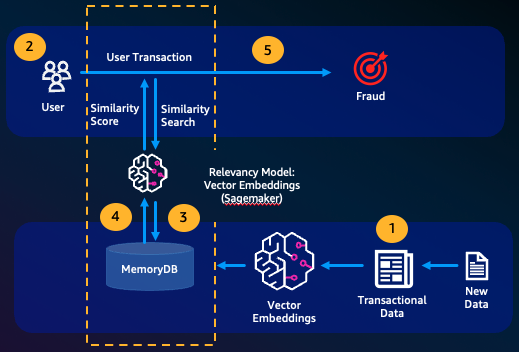
欺诈检测是一种异常检测形式,在它将有效事务表示为向量,并与全新事务的向量表示进行比较。当这些全新事务的向量与表示有效事务数据的向量相似性较低时,就会检测到欺诈。这样就可以通过对正常行为进行建模来检测欺诈,而不必试图预测每一个可能的欺诈实例。通过 MemoryDB,组织能够在高吞吐量时期执行此操作,最大程度减少误报,并保持毫秒级低延迟。
其他使用案例
推荐引擎可以通过将内容表示为向量,来为用户找到相似产品或内容。向量是通过对属性和模式进行分析而创建的。根据用户模式和属性,通过查找与已获得用户正面评价的内容相似度最高的向量,可以向用户推荐之前未看到过的新内容。
文档搜索引擎将文本文档表示为密集数字向量并捕捉语义。在搜索时,引擎会将搜索查询转换为向量,并使用近似近邻搜索来查找与查询向量相似度最高的文档。这种向量相似度方法允许根据语义而不仅仅是根据关键字的匹配来匹配文档。