本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
了解连接器
连接器会持续将数据来源中的流数据复制到您的 Apache Kafka 集群,或者持续将数据从集群复制到数据接收器中,从而将外部系统和 Amazon 服务与 Apache Kafka 集群相集成。连接器还可以执行轻量级逻辑,例如在将数据传送到目标之前进行转换、格式转换或数据筛选。源连接器从数据来源提取数据,并将这些数据推送到集群中,而接收器连接器则从集群中提取数据,并将这些数据推送到数据接收器中。
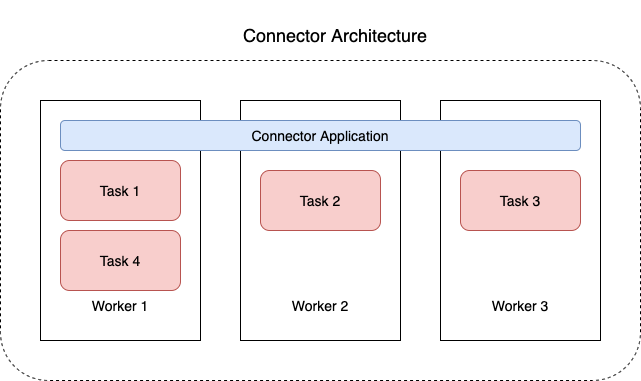
下图显示了连接器的架构。工作程序是运行连接器逻辑的 Java 虚拟机(JVM)进程。每个工作程序都会创建一组任务,这些任务在并行线程中运行并执行复制数据的工作。任务不存储状态,因此可以随时启动、停止或重新启动,以提供弹性且可扩展的数据管道。