本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
Amazon MSK 复制器的工作原理
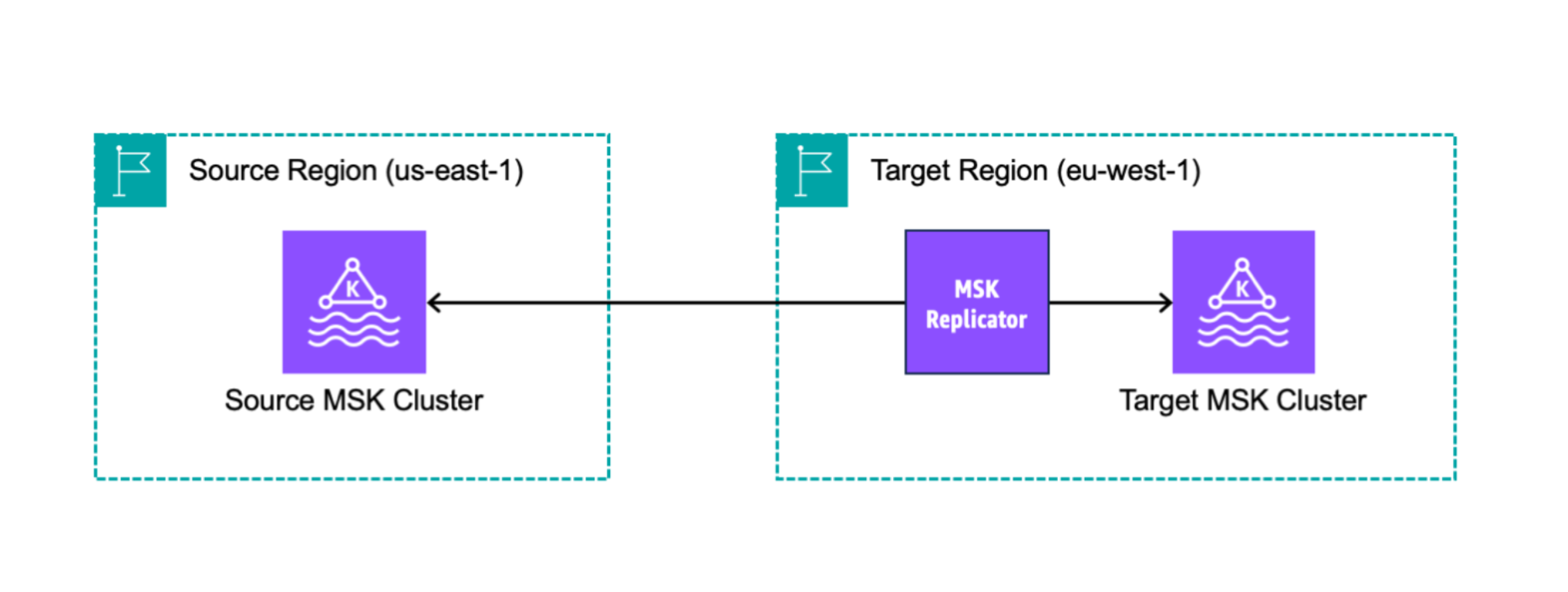
要开始使用 MSK Replicator,你需要在目标集群的区域中创建一个新的复制器。 Amazon MSK Replicator 会自动将主 Amazon 区域中名为源的集群中的所有数据复制到目标区域中名为目标的集群。源集群和目标集群可以位于相同或不同的 Amazon 区域。如果目标集群尚不存在,则需要创建该集群。
当您创建 Replicator 时,MSK Replicator 会在目标集群的 Amazon 区域中部署所有必需的资源,以优化数据复制延迟。复制延迟因许多因素而异,包括 MSK 集群 Amazon 区域之间的网络距离、源集群和目标集群的吞吐容量以及源集群和目标集群上的分区数量。MSK 复制器会自动扩缩底层资源,这样您就可以按需复制数据,而无需监控或扩展容量。
数据复制
默认情况下,MSK 复制器将所有数据从源集群主题分区的最新偏移异步复制到目标集群。如果“检测和复制新的主题”设置已开启,则 MSK 复制器会自动检测新主题或主题分区并将其复制到目标集群。但是,复制器可能需要长达 30 秒的时间才能在目标集群上检测并创建新的主题或主题分区。在目标集群上创建主题之前,向源主题生成的任何消息都不会被复制。或者,如果想将主题上的现有消息复制到目标集群,则可以在创建期间配置复制器,以从源集群主题分区中最早的偏移开始复制。
MSK 复制器不存储您的数据。数据从源集群使用,在内存中缓冲,然后写入目标集群。当数据成功写入或重试失败后,缓冲区会自动清除。MSK 复制器与您的集群之间的所有通信和数据始终在传输过程中加密。所有 MSK Replicator API 调用(例如DescribeClusterV2,CreateTopic,)DescribeTopicDynamicConfiguration都将在中捕获。 Amazon CloudTrail您的 MSK 代理日志也将反映相同的内容。
MSK 复制器在目标集群中创建主题,复制器因子为 3。如果需要,您可以直接在目标集群上修改复制因子。
元数据复制
MSK 复制器还支持将元数据从源集群复制到目标集群。元数据包括主题配置、访问控制列表 (ACLs) 和使用者组偏移量。与数据复制一样,元数据复制也是异步发生的。为了获得更好的性能,MSK 复制器优先进行数据复制而不是元数据复制。
下表是 MSK Replicator 复制的访问控制列表 (ACLs) 的列表。
| 操作 | 研究 | APIs 允许 |
|---|---|---|
|
更改 |
Topic |
CreatePartitions |
|
AlterConfigs |
Topic |
AlterConfigs |
|
Create |
Topic |
CreateTopics,元数据 |
|
删除 |
Topic |
DeleteRecords, DeleteTopics |
|
描述 |
Topic |
ListOffsets、元数据、 OffsetFetch、 OffsetForLeaderEpoch |
|
DescribeConfigs |
Topic |
DescribeConfigs |
|
读取 |
Topic |
获取, OffsetCommit, TxnOffsetCommit |
|
写入(仅拒绝) |
Topic |
生产, AddPartitionsToTxn |
MSK Replicator ACLs 仅为资源类型主题复制文字模式类型。不复制前缀模式类型 ACLs 和其他 ACLs 资源类型。MSK Replicator 也不会在目标集群 ACLs 上删除。如果删除源集群上的 ACL,则还应同时删除目标集群上的 ACL。有关 Kafka ACLs 资源、模式和操作的更多详细信息,请参阅 https://kafka.apache.org/documentation/#security_authz_cli
MSK Replicator 仅复制 Kafka ACLs,而 IAM 访问控制不使用它。如果您的客户使用 IAM 访问控制 read/write 来访问您的 MSK 集群,则还需要在目标集群上配置相关的 IAM 策略以实现无缝故障转移。带前缀和相同主题名称复制配置也是如此。
作为消费者组偏移量同步的一部分,MSK 复制器会针对源集群上的消费者进行优化,这些消费者从更靠近流末端的位置(主题分区的末尾)进行读取。如果您的消费者组在源集群上出现延迟,那么与源相比,您可能会看到目标上的消费者组的延迟更高。这意味着在失效转移到目标集群后,您的消费者将重新处理更多重复消息。为了减少此延迟后,源集群上的消费者需要赶上进度并从流末端(主题分区的末尾)开始消耗。当您的消费者赶上时,MSK 复制器将自动减少延迟。
主题名称配置
MSK 复制器有两种主题名称配置模式:带前缀(默认)或相同主题名称复制。
带前缀主题名称复制
默认情况下,MSK 复制器在目标集群中创建新主题,并在源集群主题名称中添加自动生成的前缀,例如 <sourceKafkaClusterAlias>.topic。这是为了将复制的主题与目标集群中的其他主题区分开来,并避免集群之间循环复制数据。
例如,MSK Replicator 将名为 “主题” 的主题中的数据从源集群复制到目标集群中名为 < Alias>.Topic 的新主题。sourceKafkaCluster您可以使用 DescribeReplicator API 在 “sourceKafkaCluster别名” 字段下找到将添加到目标集群中主题名称的前缀,也可以在 MSK 控制台上的 Replicator 详细信息页面上找到。目标集群中的前缀是 < sourceKafkaCluster Alias>。
为确保您的消费者能够可靠地从备用集群重新启动处理,您需要将消费者配置为使用通配符运算符 .* 从主题中读取数据。例如,您的消费者需要使用消费。 *topic1在两个 Amazon 地区。此示例还将包括 footopic1 之类的主题,因此请根据需要调整通配符运算符。
如果要将复制器数据保存在目标集群的单独主题中(例如主动-主动集群设置),则应使用 MSK 复制器,它会添加前缀。
相同主题名称复制
作为默认设置的替代方案,Amazon MSK 复制器允许您在主题复制设置为相同主题名称复制的情况下创建复制器(控制台中为保留相同的主题名称)。您可以在拥有目标 MSK 集群的 Amazon 区域中创建新的复制器。同名的复制主题可以避免避免重新配置客户端来读取复制的主题。
相同主题名称复制(控制台中为保留相同的主题名称)具有以下优点:
允许您在复制过程中保留相同的主题名称,同时自动避免无限复制循环的风险。
使设置和操作多集群流架构变得更简单,因为您可以避免重新配置客户端来读取复制的主题。
对于主动-被动集群架构,相同主题名称复制功能还简化了失效转移过程,允许应用程序无缝失效转移到备用集群,而无需更改任何主题名称或重新配置客户端。
可用于更轻松地将来自多个 MSK 集群的数据整合到单个集群中,以进行数据聚合或集中分析。这要求您为每个源集群和相同目标集群创建单独的复制器。
通过将数据复制到目标集群中同名主题,可以简化从一个 MSK 集群到另一个 MSK 集群的数据迁移。
Amazon MSK 复制器使用 Kafka 标头自动避免将数据复制回其来源主题,从而消除复制期间无限循环的风险。标头是一个键值对,可以包含每个 Kafka 消息中的键、值和时间戳。MSK 复制器将源集群和主题的标识符嵌入到每个正在复制的记录的头中。MSK 复制器使用标头信息来避免无限复制循环。您应该验证您的客户端是否能够按预期读取复制的数据。