本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
openCypher 数据的加载格式
要使用 openCypher CSV 格式加载 openCypher 数据,必须在单独的文件中指定节点和关系。加载程序可以在单个加载任务中从多个节点文件和关系文件中加载。
对于每个加载命令,要加载的文件集在 Amazon Simple Storage Service 桶中必须具有相同的路径前缀。您可以在源参数中指定该前缀。实际的文件名和扩展名不重要。
在 Amazon Neptune 中,openCypher CSV 格式符合 RFC 4180 CSV 规范。有关更多信息,请参阅互联网工程任务组 (IETFhttps://tools.ietf.org/html/rfc4180) 网站上的 CSV 文件的常用格式和 MIME 类型
注意
这些文件必须按 UTF-8 格式编码。
每个文件都有一个以逗号分隔的标题行,其中包含系统列标题和属性列标题。
openCypher 数据加载文件中的系统列标题
给定的系统列在标题中只能出现一次。所有系统列标题标签均区分大小写。
openCypher 节点加载文件和关系加载文件所需的和允许的系统列标题不同:
节点文件中的系统列标题
-
:ID–(必需)节点的 ID。可以在节点
:ID列标题中添加可选的 ID 空间,例如::ID(。例如,ID Space):ID(movies)。加载连接此文件中节点的关系时,请在关系文件的
:START_IDand/or:END_ID列中使用相同的 ID 空间。可以选择将节点
:ID列存储为采用property name:IDname:ID。在当前和之前加载的所有节点文件中,节点 ID 应是唯一的。如果使用 ID 空间,则在当前和之前的加载中使用相同 ID 空间的所有节点文件中,节点 ID 应是唯一的。
-
:LABEL– 节点的标签。为单个节点使用多个标签值时,每个标签应用分号(
;)分隔。
关系文件中的系统列标题
-
:ID– 关系的 ID。当userProvidedEdgeIds为 true(默认)时,这是必需的,但当userProvidedEdgeIds为false时,则无效。在当前和之前加载的所有关系文件中,关系 ID 应是唯一的。
-
:START_ID–(必需)此关系的起始节点的节点 ID。或者,ID 空间可以与格式为
:START_ID(的起始 ID 列相关联。分配给起始节点 ID 的 ID 空间应与在节点文件中分配给该节点的 ID 空间相匹配。ID Space) -
:END_ID–(必需)此关系的结束节点的节点 ID。或者,ID 空间可以与格式为
:END_ID(的结束 ID 列相关联。分配给结束节点 ID 的 ID 空间应与在其节点文件中分配给该节点的 ID 空间相匹配。ID Space) -
:TYPE– 关系的类型。关系只能有单一类型。
注意
有关批量加载过程如何处理重复的节点 ID 或关系 ID 的信息,请参阅加载 openCypher 数据。
openCypher 数据加载文件中的属性列标题
您可以使用以下格式的属性列标题来指定某一列包含特定属性的值:
propertyname:type
不允许在列标题中使用空格、逗号、回车和换行符,因此属性名称不得包含这些字符。以下是名为 age 且类型为 Int 的属性的列标题示例:
age:Int
然后,age:Int 作为列标题的列必须在每行中包含一个整数或一个空值。
Neptune openCypher 数据加载文件中的数据类型
-
Bool或Boolean– 布尔型字段。支持的值包括true和false。除
true之外的任何值都视为false。 -
Byte– 范围为-128至127的整数。 -
Short– 范围为-32,768至32,767的整数。 -
Int– 范围为-2^31至2^31 - 1的整数。 -
Long– 范围为-2^63至2^63 - 1的整数。 -
Float– 32 位 IEEE 754 浮点数。支持十进制记数法和科学记数法。可全部识别Infinity、-Infinity、和NaN,但不识别INF。位数太多而无法容纳的值将四舍五入到最接近的值(对于位级别的最后一个剩余数字,中间值将舍入为 0)。
-
Double– 64 位 IEEE 754 浮点数。支持十进制记数法和科学记数法。可全部识别Infinity、-Infinity、和NaN,但不识别INF。位数太多而无法容纳的值将四舍五入到最接近的值(对于位级别的最后一个剩余数字,中间值将舍入为 0)。
-
String– 引号是可选的。如果双引号 (") 括起来的字符串中包含逗号字符、换行符和回车符(如"Hello, World"),则将自动对这些字符进行转义。您可以通过连续使用两个引号在带引号的字符串中加入引号,比如
"Hello ""World"""。 -
DateTime— 采用以下 ISO-8601 格式之一的 Java 日期:yyyy-MM-ddyyyy-MM-ddTHH:mmyyyy-MM-ddTHH:mm:ssyyyy-MM-ddTHH:mm:ssZ
Auto-cast Neptune 中的数据类型 OpenCypher 数据加载文件
Auto-cast 提供数据类型是为了加载 Neptune 目前不支持的数据类型。此类列中的数据以字符串形式存储,逐字存储,无需根据其预期格式进行验证。允许使用以下自动转换数据类型:
-
Char–Char字段。存储为字符串。 -
Date、LocalDate和LocalDateTime– 有关date、localdate和localdatetime类型的描述,请参阅 Neo4j 瞬时。这些值作为字符串逐字加载,无需验证。 -
Duration– 请参阅 Neo4j 持续时间格式。这些值作为字符串逐字加载,无需验证。 -
点 – 用于存储空间数据的点字段。请参阅空间瞬时
。这些值作为字符串逐字加载,无需验证。
openCypher 加载格式示例
下图取自 TinkerPop 现代图,显示了两个节点和一个关系的示例:
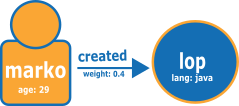
以下是正常的 Neptune openCypher 加载格式的图形。
节点文件:
:ID,name:String,age:Int,lang:String,:LABEL v1,"marko",29,,person v2,"lop",,"java",software
关系文件:
:ID,:START_ID,:END_ID,:TYPE,weight:Double e1,v1,v2,created,0.4
或者,您可以使用 ID 空间和 ID 作为属性,如下所示:
第一个节点文件:
name:ID(person),age:Int,lang:String,:LABEL "marko",29,,person
第二个节点文件:
name:ID(software),age:Int,lang:String,:LABEL "lop",,"java",software
关系文件:
:ID,:START_ID(person),:END_ID(software),:TYPE,weight:Double e1,"marko","lop",created,0.4