本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
将 Gremlin 查询结果导出到 Amazon S3
从引擎版本 1.4.3.0 开始,Amazon Neptune 支持将 Gremlin 查询结果直接导出到 Amazon S3。该功能支持您将大型查询结果导出到 Amazon S3 存储桶,而不是作为查询响应返回,从而更高效地处理海量查询结果。
要将查询结果导出到 Amazon S3,请在 Gremlin 查询的最后一步使用 call() 步骤,并将服务名称设置为 neptune.query.exportToS3。可在 call() 步骤之后添加使用字节码的 Tinkerpop 驱动程序
注意
包含 call() 步骤且该步骤使用 neptune.query.exportToS3 的查询,若未作为最终步骤使用,则会失败。使用字节码的 Gremlin 客户端可以使用终端步骤。有关更多信息,请参阅 Amazon Neptune 文档中的 Gremlin 最佳实践。
g.V() ... .call('neptune.query.exportToS3', [ 'destination': 's3://your-bucket/path/result.json', 'format': 'GraphSONv3', 'kmskeyArn': 'optional-kms-key-arn' ])
Parameters
-
destination:必填 - 结果将写入的 Amazon S3 URI。 -
format: 必填-输出格式,目前仅支持 “Graph SONv3”。 -
keyArn: 可选-用于 Amazon S3 服务器端Amazon KMS加密的密钥的 ARN。
示例
示例查询
g.V(). hasLabel('Comment'). valueMap(). call('neptune.query.exportToS3', [ 'destination': 's3://your-bucket/path/result.json', 'format': 'GraphSONv3', 'keyArn': 'optional-kms-key-arn' ])
查询响应示例
{ "destination":"s3://your-bucket/path/result.json, "exportedResults": 100, "exportedBytes": 102400 }
先决条件
-
您的 Neptune 数据库实例必须能够通过类型网关的 VPC 端点访问 Amazon S3。
-
要在查询中使用自定义Amazon KMS加密,需要接口类型的 VPC 终端节点,以允许 Amazon KMS Neptune 与之通信。Amazon KMS
-
您必须在 Neptune 上启用 IAM 身份验证并拥有相应的 IAM 权限,才能写入目标 Amazon S3 存储桶。否则,会导致 400 错误请求错误:“集群必须启用 IAM 身份验证,才能进行 S3 导出”。
-
目标 Amazon S3 存储桶:
-
目标 Amazon S3 存储桶不得是公有的。必须启用
Block public access。 -
目标 Amazon S3 目标必须为空。
-
目标 Amazon S3 存储桶必须针对
Delete expired object delete markers or incomplete multipart uploads(包含Delete incomplete multipart uploads)启用生命周期规则。有关更多信息,请参阅 Amazon S3 生命周期管理更新 – 支持分段上传和删除标记。 
-
目标 Amazon S3 存储桶必须针对
Delete expired object delete markers or incomplete multipart uploads启用生命周期规则,并将Delete incomplete multipart uploads设置为高于查询评估所需的值(例如 7 天)。这是删除未完成的上传(无法直接看到但会产生费用)所必需的,以防万一 Neptune 无法完成或中止(例如,由于失败)。 instance/engine 有关更多信息,请参阅 Amazon S3 生命周期管理更新 – 支持分段上传和删除标记。 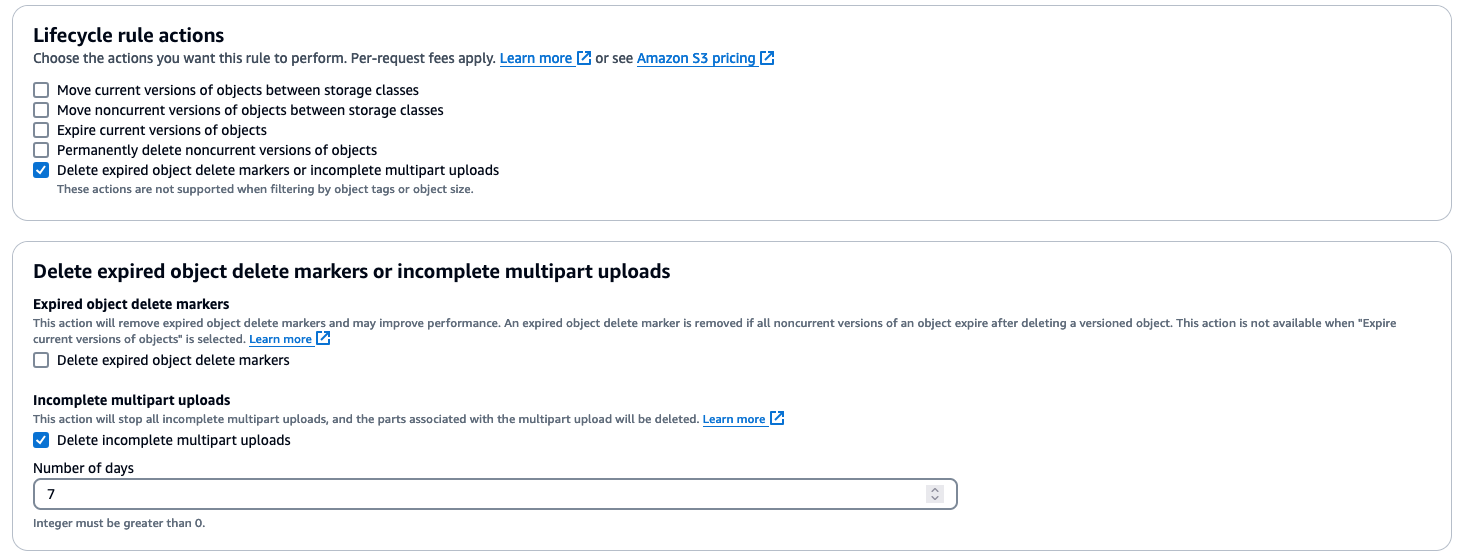
-
重要注意事项
-
导出步骤必须是 Gremlin 查询的最后一步。
-
如果指定的 Amazon S3 位置已存在对象,则查询将失败。
-
导出查询的查询执行时间上限为 11 小时 50 分钟。此功能使用转发访问会话。目前上限为 11 小时 50 分钟,以避免令牌过期问题。
注意
导出查询仍遵循查询超时限制。对于大型导出,应使用适当的查询超时设置。
-
所有上传到 Amazon S3 的新对象都会自动加密。
-
为了避免在出现错误或崩溃时由于分段上传未完成而产生存储费用,建议您在 Amazon S3 存储桶上设置包含
Delete incomplete multipart uploads的生命周期规则。
响应格式
查询不会直接返回查询结果,而是返回有关导出操作的元数据,包括状态和导出详细信息。Amazon S3 中的查询结果将SONv3采用图表
{ "data": { "@type": "g:List", "@value": [ { "@type": "g:Map", "@value": [ "browserUsed", { "@type": "g:List", "@value": [ "Safari" ] }, "length", { "@type": "g:List", "@value": [ { "@type": "g:Int32", "@value": 7 } ] }, "locationIP", { "@type": "g:List", "@value": [ "192.0.2.0/24" ] }, "creationDate", { "@type": "g:List", "@value": [ { "@type": "g:Date", "@value": 1348341961000 } ] }, "content", { "@type": "g:List", "@value": [ "no way!" ] } ] }, { "@type": "g:Map", "@value": [ "browserUsed", { "@type": "g:List", "@value": [ "Firefox" ] }, "length", { "@type": "g:List", "@value": [ { "@type": "g:Int32", "@value": 2 } ] }, "locationIP", { "@type": "g:List", "@value": [ "203.0.113.0/24" ] }, "creationDate", { "@type": "g:List", "@value": [ { "@type": "g:Date", "@value": 1348352960000 } ] }, "content", { "@type": "g:List", "@value": [ "ok" ] } ] }, ... ] } }
安全性
-
传输到 Amazon S3 的所有数据全部使用 SSL 在传输过程中实现加密。
-
您可以为导出数据的服务器端加密指定密Amazon KMS钥。默认情况下,Amazon S3 会对新数据进行加密。如果存储桶配置为使用特定Amazon KMS密钥,则使用该密钥。
-
在开始导出之前,Neptune 会验证目标存储桶是否是公有的。
-
不支持跨账户和跨区域导出。
错误处理
-
目标 Amazon S3 存储桶是公有的。
-
指定对象已经存在。
-
您没有足够的权限写入 Amazon S3 存储桶。
-
查询执行超过了最大时间限制。
最佳实践
-
使用 Amazon S3 存储桶生命周期规则清理未完成的分段上传。
-
使用 Neptune 日志和指标监控导出操作。您可以检查 Gremlin 状态端点以查看查询当前是否正在运行。只要客户端没有收到响应,就会假定查询正在运行。