本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
关于如何使用 Neptune ML 特征的概述
Amazon Neptune 中的 Neptune ML 特征为在图形数据库中利用机器学习模型提供了简化的工作流程。该过程涉及几个关键步骤:将来自 Neptune 的数据导出为 CSV 格式,对数据进行预处理以准备模型训练,使用 Amazon SageMaker AI 训练机器学习模型,创建用于预测的推理端点,然后直接从 Gremlin 查询中查询模型。Neptune 工作台提供便捷的线路和单元魔术命令,以帮助管理和自动执行这些步骤。通过将机器学习功能直接集成到图形数据库中,Neptune ML 使用户能够使用存储在 Neptune 图中的丰富关系数据得出有价值的见解并做出预测。
开始使用 Neptune ML 的工作流程
在 Amazon Neptune 中使用 Neptune ML 特征通常需要从以下五个步骤开始:
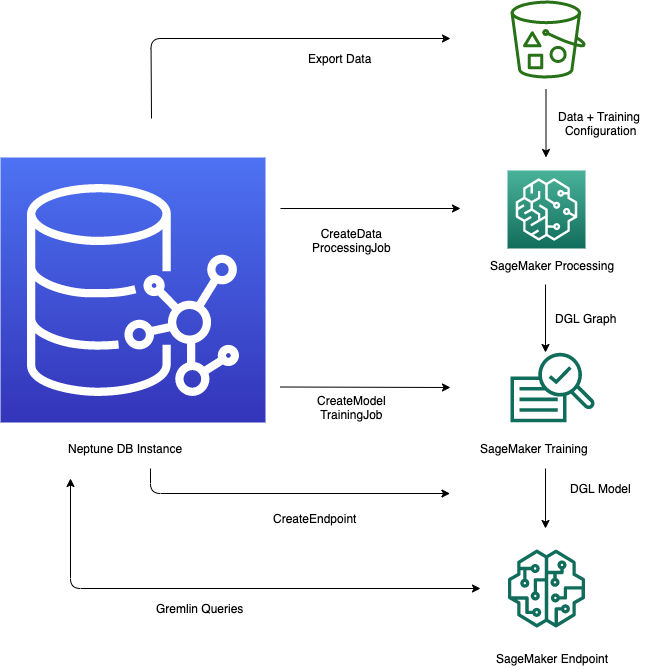
-
数据导出和配置 – 数据导出步骤使用 Neptune-Export 服务或
neptune-export命令行工具,将数据从 Neptune 以 CSV 格式导出到 Amazon Simple Storage Service (Amazon S3)。同时会自动生成一个名为training-data-configuration.json的配置文件,该文件指定如何将导出的数据加载到可训练的图形中。 -
数据预处理 - 在此步骤中,使用标准技术对导出的数据集进行预处理,准备好数据以进行模型训练。可以对数字数据执行特征标准化,也可以使用
word2vec对文本特征进行编码。在此步骤结束时,将根据导出的数据集生成 DGL(深度图表库)图形供模型训练步骤使用。此步骤是使用您账户中的 SageMaker AI 处理任务来实现的,生成的数据存储在您指定的 Amazon S3 位置。
-
模型训练 - 模型训练步骤训练将用于预测的机器学习模型。
模型训练分两个阶段完成:
第一阶段使用 SageMaker AI 处理任务来生成模型训练策略配置集,该配置集指定模型训练将使用哪种类型的模型和模型超参数范围。
然后,第二阶段使用 SageMaker AI 模型调整作业来尝试不同的超参数配置,并选择生成了性能最佳模型的训练作业。调整任务对处理后的数据运行预先指定数量的模型训练任务试验。在此阶段结束时,将使用最佳训练任务的训练模型参数来生成模型构件以进行推理。
-
在 Amazon SageMaker AI 中创建推理端点 – 推理端点是一个 SageMaker AI 端点实例,它使用最佳训练作业生成的模型构件启动。每个模型都绑定到单个端点。端点能够接受来自图形数据库的传入请求,并返回请求中输入的模型预测。创建端点后,它会一直处于活动状态,直到您将其删除。
使用 Gremlin 查询机器学习模型 – 您可以使用 Gremlin 查询语言的扩展来查询来自推理端点的预测。