本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
管理 Neptune DFE 要使用的统计数据
注意
对 openCypher 的支持取决于 Neptune 中的 DFE 查询引擎。
DFE 引擎使用neptune_dfe_query_engine实例的数据库参数组中的实例参数进行控制。
在计划查询执行时,DFE 引擎使用有关 Neptune 图形中数据的信息来进行有效的权衡。这些信息采用统计数据的形式,包括可以指导查询计划的所谓特性集和谓词统计数据。
从引擎版本 1.2.1.0 开始,您可以使用 GetGraphSummaryAPI 或端点从这些统计数据中检索有关图表的摘要信息。summary
目前,每当图形中超过 10% 的数据发生变化或最新的统计数据超过 10 天时,就会重新生成这些 DFE 统计数据。然而,这些触发因素在未来可能会发生变化。
注意
在 T3 和 T4g 实例上禁用统计数据生成,因为它可能超过这些实例类型的内存容量。
您可以通过以下端点之一管理 DFE 统计数据的生成:
https://(对于 SPARQL)。your-neptune-host:port/rdf/statisticshttps://(对于 Gremlin 和 openCypher),以及它的替代版本:your-neptune-host:port/propertygraph/statisticshttps://。your-neptune-host:port/pg/statistics
注意
从引擎版本 1.1.1.0 开始,Gremlin 统计数据端点 (https://) 已被弃用,转而使用 your-neptune-host:port/gremlin/statisticspropertygraph 或 pg 端点。为了向后兼容,它仍然受支持,但可能会在将来版本中移除。
从引擎版本 1.2.1.0 开始,SPARQL 统计数据端点 (https://) 已被弃用,转而使用 your-neptune-host:port/sparql/statisticsrdf 端点。为了向后兼容,它仍然受支持,但可能会在将来版本中移除。
注意
如果 DFE 统计数据端点位于读取器实例上,则它只能处理状态请求。其它请求将失败,并显示 ReadOnlyViolationException。
生成 DFE 统计数据的大小限制
当前,如果达到以下任一大小限制,DFE 统计数据生成就会停止:
生成的特性集数量不得超过 5 万个。
生成的谓词统计数据数量不得超过一百万个。
这些限制可能会发生变化。
DFE 统计数据的当前状态
您可以按如下方式查看 DFE 统计信息的当前状态:
注意
以下示例使用属性图端点和命令。对于 RDF 数据,请使用get-sparql-statistics和 /rdf/statistics REST 端点。 Amazon CLI
对状态请求的响应包含以下字段:
status– 请求的 HTTP 返回代码。如果请求成功,则代码为200。有关常见错误的列表,请参阅常见错误。-
payload:autoCompute–(布尔值)表示是否启用了自动统计数据生成。active–(布尔值)表示是否启用了 DFE 统计数据生成。statisticsId– 报告当前统计数据生成运行的 ID。值为-1表示未生成任何统计数据。-
date– 最近生成 DFE 统计数据的 UTC 时间,采用 ISO 8601 格式。注意
在引擎版本 1.2.1.0 之前,这是用分钟精度表示的,但从引擎版本 1.2.1.0 开始,它以毫秒精度表示(例如
2023-01-24T00:47:43.319Z)。 note– 有关统计数据无效时出现的问题的注释。-
signatureInfo– 包含有关在统计数据中生成的特性集的信息(在引擎版本 1.2.1.0 之前,此字段命名为summary)。这些通常不可直接操作:signatureCount– 所有特性集中的签名总数。instanceCount– 特性集实例的总数。predicateCount– 唯一谓词的总数。
未生成统计数据时对状态请求的响应如下所示:
{ "status" : "200 OK", "payload" : { "autoCompute" : true, "active" : false, "statisticsId" : -1 } }
如果 DFE 统计数据可用,则响应类似于以下内容:
{ "status" : "200 OK", "payload" : { "autoCompute" : true, "active" : true, "statisticsId" : 1588893232718, "date" : "2020-05-07T23:13Z", "summary" : { "signatureCount" : 5, "instanceCount" : 1000, "predicateCount" : 20 } } }
如果生成 DFE 统计数据失败,例如,因为它超出了统计数据大小限制,则响应如下所示:
{ "status" : "200 OK", "payload" : { "autoCompute" : true, "active" : false, "statisticsId" : 1588713528304, "date" : "2020-05-05T21:18Z", "note" : "Limit reached: Statistics are not available" } }
禁用自动生成 DFE 统计数据
默认情况下,启用 DFE 时会启用自动生成 DFE 统计数据。
您可以按如下方式禁用自动生成:
注意
以下示例使用属性图端点和命令。对于 RDF 数据,请使用manage-sparql-statistics和 /rdf/statistics REST 端点。 Amazon CLI
如果请求成功,则 HTTP 响应代码为 200,响应为:
{ "status" : "200 OK" }
您可以通过发出状态请求并检查响应中的 autoCompute 字段是否设置为 false,确认自动生成已禁用。
禁用自动生成统计数据不会终止正在进行的统计数据计算。
如果您请求对读取器实例而不是数据库集群的写入器实例禁用自动生成,则请求将失败,HTTP 返回代码为 400,输出如下所示:
{ "detailedMessage" : "Writes are not permitted on a read replica instance", "code" : "ReadOnlyViolationException", "requestId":"8eb8d3e5-0996-4a1b-616a-74e0ec32d5f7" }
有关其它常见错误的列表,请参阅常见错误。
Re-enabling 自动生成 DFE 统计数据
默认情况下,启用 DFE 时已启用自动生成 DFE 统计数据。如果禁用自动生成,则可以稍后按如下方式重新启用:
注意
以下示例使用属性图端点和命令。对于 RDF 数据,请使用manage-sparql-statistics和 /rdf/statistics REST 端点。 Amazon CLI
如果请求成功,则 HTTP 响应代码为 200,响应为:
{ "status" : "200 OK" }
您可以通过发出状态请求并检查响应中的 autoCompute 字段是否设置为 true,确认自动生成已启用。
手动触发 DFE 统计数据生成
您可以手动启动 DFE 统计数据生成,如下所示:
注意
以下示例使用属性图端点和命令。对于 RDF 数据,请使用manage-sparql-statistics和 /rdf/statistics REST 端点。 Amazon CLI
如果请求成功,则输出如下所示,HTTP 返回代码为 200:
{ "status" : "200 OK", "payload" : { "statisticsId" : 1588893232718 } }
输出中的 statisticsId 是当前正在发生的统计数据生成运行的 ID。如果在请求时运行已在进行中,则该请求将返回该运行的 ID,而不是启动新的运行。一次只能发生一个统计数据生成运行。
如果在生成 DFE 统计数据时发生失效转移,则新的写入器节点将获取上次处理的检查点,并从此处恢复统计数据运行。
使用该StatsNumStatementsScanned CloudWatch 指标监控统计数据计算
该StatsNumStatementsScanned CloudWatch 指标返回自服务器启动以来为统计计算而扫描的语句总数。它会在每个统计数据计算切片处更新。
每次触发统计数据计算时,这个数字都会增加,当没有进行任何计算时,它会保持不变。因此,查看一段时间内的 StatsNumStatementsScanned 值图,可以非常清楚地了解统计数据计算发生的时间和速度:
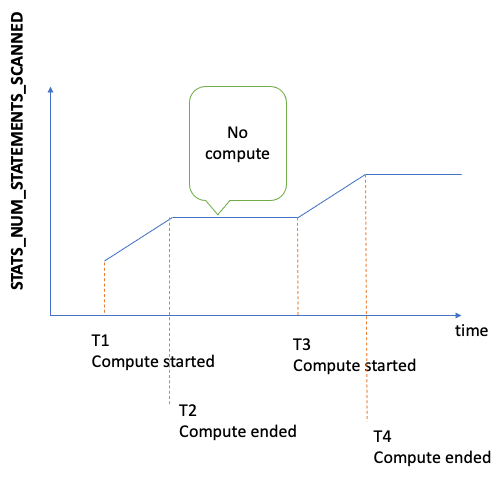
发生计算时,图形的斜率显示出速度有多快(斜率越陡,计算统计数据的速度就越快)。
如果图形只是 0 处的一条平线,则表示统计数据特征已启用,但根本没有计算任何统计数据。如果统计数据特征已被禁用,或者您使用的引擎版本不支持统计数据计算,则 StatsNumStatementsScanned 不存在。
如前所述,您可以使用统计数据 API 禁用统计数据计算,但将其禁用可能会导致统计数据无法保持最新,这反过来又会导致 DFE 引擎的查询计划生成不佳。
有关如何使用的信息,请参阅使用亚马逊监控 Neptune CloudWatch CloudWatch。
使用 Amazon Identity and Access Management 使用 DFE 统计终端节点进行 (IAM) 身份验证
您可以使用 Amazon CLI、awscurl 或任何其他支持 HTTPS 和 IAM 的工具,通过 IA
以下示例说明如何发出经过身份验证的状态请求:
注意
以下示例使用属性图端点和命令。对于 RDF 数据,对于 RDF 端点使用等效的 SPARQL 命令 (get-sparql-statistics、manage-sparql-statistics) Amazon CLI,对于 REST /rdf/statistics 端点。
以下示例通过身份验证手动启动统计数据生成:
删除 DFE 统计数据
您可以按如下方式删除数据库中的所有统计信息:
注意
以下示例使用属性图端点和命令。对于 RDF 数据,请使用delete-sparql-statistics和 /rdf/statistics REST 端点。 Amazon CLI
有效的 HTTP 返回代码为:
-
200– 删除已成功。在这种情况下,典型的响应如下所示:
{ "status" : "200 OK", "payload" : { "active" : false, "statisticsId" : -1 } } -
204– 没有要删除的统计数据。在这种情况下,响应为空(无响应)。
如果您向读取器节点上的统计数据端点发送删除请求,则引发 ReadOnlyViolationException。
DFE 统计请求的常见错误代码
以下是您向统计数据端点发出请求时可能发生的常见错误列表:
AccessDeniedException– 返回代码:400。消息:Missing Authentication Token。BadRequestException(对于 Gremlin 和 openCypher)– 返回代码:400。消息:Bad route: /pg/statistics。BadRequestException(对于 RDF 数据)- 返回代码:400。消息:Bad route: /rdf/statistics。InvalidParameterException– 返回代码:400。消息:Statistics command parameter 'mode' has unsupported value '。the invalid value'MissingParameterException– 返回代码:400。消息:Content-type header not specified.。ReadOnlyViolationException– 返回代码:400。消息:Writes are not permitted on a read replica instance。
例如,如果您在未启用 DFE 和统计数据时发出请求,则会得到如下响应:
{ "code" : "BadRequestException", "requestId" : "b2b8f8ee-18f1-e164-49ea-836381a3e174", "detailedMessage" : "Bad route: /sparql/statistics" }