本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
在 Amazon OpenSearch Ingestion 中设置角色和用户
Amazon OpenSearch Ingestion 使用各种权限模型和 IAM 角色来允许源应用程序写入管道,并允许管道写入接收器。在开始提取数据之前,您需要根据自己的用例创建一个或多个具有具体权限的 IAM 角色。
至少需要以下角色才能成功设置管道。
下图演示了典型的管道设置,其中诸如 Amazon S3 或 Fluent Bit 之类的数据来源使用不同的账户写入管道。在这种情况下,客户端需要担任提取角色才能访问管道。有关更多信息,请参阅 跨账户提取。
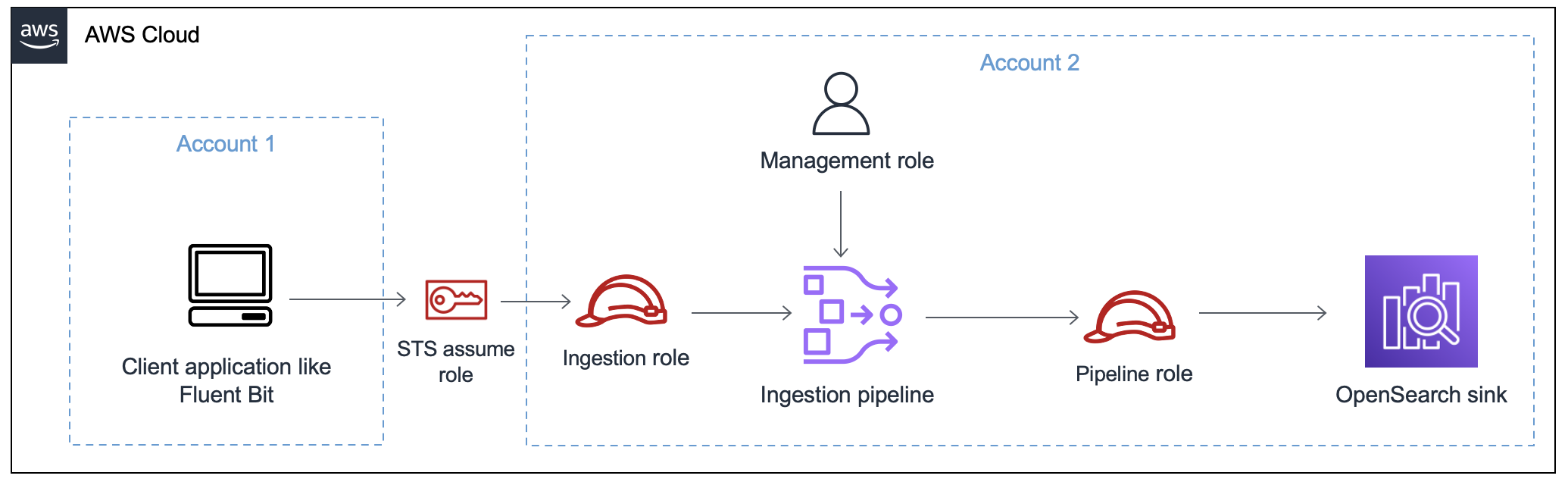
欲了解简易设置指南,请参阅教程:使用 Amazon Ingestion 将数据提取到域中 OpenSearch。
主题
管道角色
管道需要特定权限才能从源读取数据并向目标写入数据。这些权限取决于客户端应用程序或 Amazon Web Services 服务 正在写入管道的应用程序,以及接收器是 OpenSearch 服务域、 OpenSearch 无服务器集合还是 Amazon S3。此外,管道可能需要权限才能从源应用程序(如果源应用程序是基于拉取的插件)物理拉取数据,以及写入 S3 死信队列(如果已启用)。
创建管道时,您可以选择指定手动创建的现有 IAM 角色,也可以让 OpenSearch Ingestion 根据您选择的源和接收器自动创建管道角色。下图显示如何在 Amazon Web Services 管理控制台中指定管道角色。
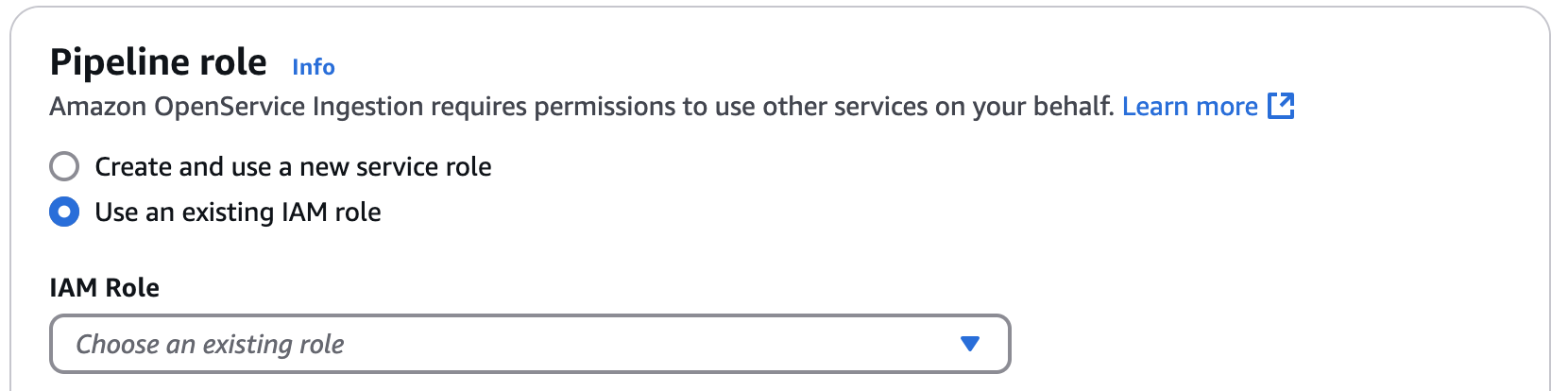
自动创建管道角色
你可以选择让 OpenSearch Ingestion 为你创建管道角色。OpenSearch Ingestion 会根据配置的源和接收器自动识别角色所需的权限。OpenSearch Ingestion 会利用您输入的前缀 OpenSearchIngestion- 和后缀创建 IAM 角色。例如,如果您输入PipelineRole作为后缀, OpenSearch Ingestion 会创建一个名为的角色。OpenSearchIngestion-PipelineRole
自动创建管道角色可简化设置流程,并降低配置错误的发生概率。通过自动化角色创建,可避免手动分配权限,确保正确策略得以应用,同时规避安全配置错误的风险。这还通过实施最佳实践节省时间并增强安全合规性,同时确保多个管道部署的一致性。
您只能让 OpenSearch Ingestion 在中自动创建管道角色。 Amazon Web Services 管理控制台如果您使用的是 Amazon CLI、 OpenSearch Ingestion API 或其中一个 SDKs,则必须指定手动创建的管道角色。
要让 OpenSearch Ingestion 为您创建角色,请选择创建并使用新的服务角色。
重要
您仍需手动修改域或集合访问策略,以授予对管道角色的访问权限。对于使用精细访问控制的域,您还必须将管道角色映射至后端角色。您可以在创建管道之前或之后执行这些步骤。
有关说明,请参阅以下主题:
手动创建管道角色
如果需更精细地控制权限以满足特定的安全性或合规性要求,您可能需要手动创建管道角色。手动创建可让您根据现有基础设施或访问管理策略定制角色。您也可以选择手动设置来将该角色与其他角色集成, Amazon Web Services 服务 或者确保其符合您的独特运营需求。
要选择手动创建的管道角色,请选择使用现有 IAM 角色,然后选择现有角色。该角色必须具有从选定源接收数据并写入所选接收器所需的所有权限。以下各节概述如何手动创建管道角色。
从源读取的权限
OpenSearch 摄取管道需要权限才能读取和接收来自指定来源的数据。例如,Amazon DynamoDB 源需要诸如 dynamodb:DescribeTable 和 dynamodb:DescribeStream 之类的权限。有关常见来源(例如 Amazon S3、Fluent Bit 和 Collecto OpenTelemetry r)的管道角色访问策略示例,请参阅将 Amazon OpenSearch Ingestion 管道与其他服务和应用程序集成。
写入域接收器的权限
In OpenSearch gestion 管道需要权限才能写入配置为其接收器的 OpenSearch 服务域。这些权限包括能够描述域以及向其发送 HTTP 请求。公有域和 VPC 域需要相同的权限。有关创建管道角色并在域访问策略中指定该管道角色的说明,请参阅允许管道访问域。
写入集合接收器的权限
OpenSearch 摄取管道需要权限才能写入配置为其 OpenSearch 接收器的无服务器集合。这些权限包括能够描述集合以及向其发送 HTTP 请求。
首先,确保您的管道角色访问策略授予所需的权限。然后,将此角色包含在数据访问策略中,并为其提供在集合中创建索引、更新索引、描述索引和写入文档的权限。有关完成其中每个步骤的说明,请参阅允许管道访问集合。
写入 Amazon S3 或死信队列的权限
如果将 Amazon S3 指定为管道的接收器目标,或者如果启用死信队列
为提供 DLQ 访问权限的管道角色附加单独的权限策略。至少必须授予该角色对存储桶资源执行 S3:PutObject 操作的权限:
提取角色
摄取角色是一个 IAM 角色,它允许外部服务安全地与 OpenSearch 摄取管道交互并向其发送数据。对于基于推送的源(例如 Amazon Security Lake),此角色必须授予将数据推送至管道的权限,包括 osis:Ingest。对于基于拉取的源,例如 Amazon S3,角色必须允许 OpenSearch Ingestion 代入并使用必要的权限访问数据。
基于推送的源的提取角色
对于基于推送的源,数据会从其他服务(例如 Amazon Security Lake 或 Amazon DynamoDB)发送或推送到摄取管道。在此情况下,提取角色至少需要与 osis:Ingest 管道进行交互的权限。
以下 IAM 访问策略演示如何向提取角色授予此权限:
基于拉取的源的提取角色
对于基于拉取的源, OpenSearch Ingestion 管道会主动从外部来源(例如 Amazon S3)提取或获取数据。在此情况下,管道必须代入授予访问数据来源所需权限的 IAM 管道角色。在这些场景中,提取角色与管道角色具有同等含义。
该角色必须包括允许 OpenSearch Ingestion 担任该角色的信任关系以及特定于数据源的权限。有关更多信息,请参阅 从源读取的权限。
跨账户提取
您可能需要从其他 Amazon Web Services 账户渠道(例如应用程序帐户)将数据提取到管道中。要配置跨账户提取,请在与管道相同的账户中定义一个提取角色,并在提取角色和应用程序账户之间建立信任关系:
然后,将您的应用程序配置为担任提取角色。应用程序账户必须向应用程序角色授予管道账户中摄取角色的AssumeRole权限。
有关详细步骤和 IAM policy 示例,请参阅提供跨账户摄取访问权限。