本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
故障排除
以下 FAQ 可帮助您排除与 Amazon SageMaker 异步推理端点相关的问题。
您可以使用以下方法查找端点后台的实例数:
您可以使用 SageMaker AI DescribeEndpoint API 来列出在任意给定时间点,端点后端的实例数量。
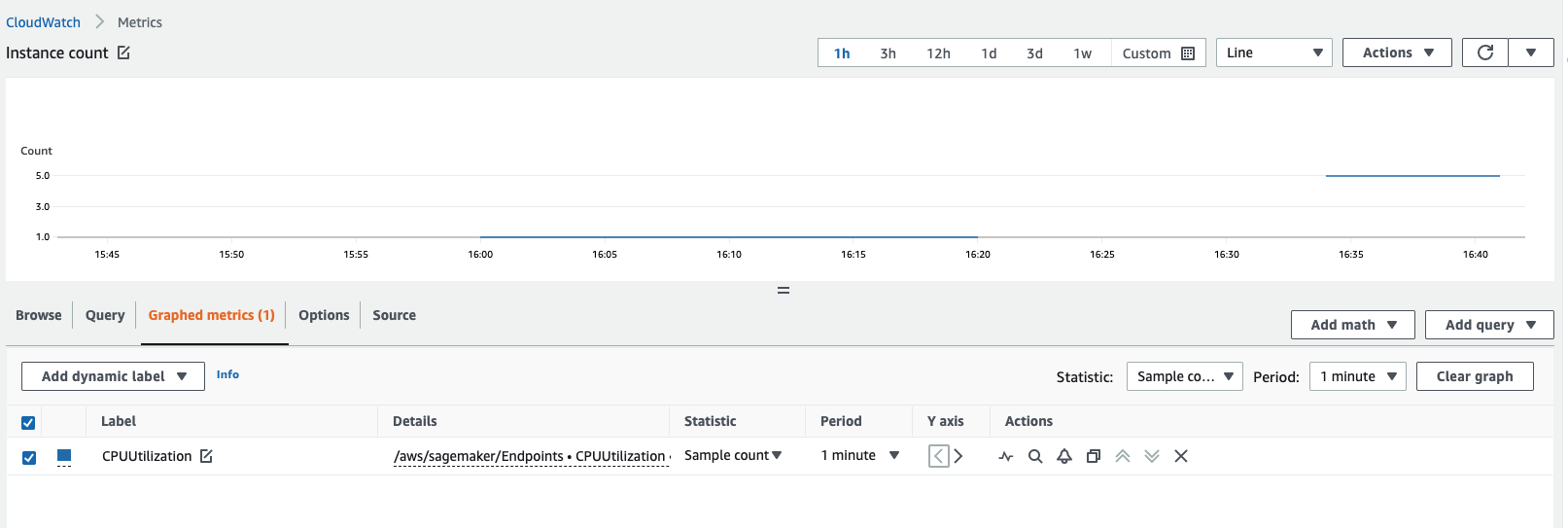
您可以通过查看 Amazon CloudWatch 指标来获取实例数量。查看端点实例的指标,例如
CPUUtilization或MemoryUtilization,并查看 1 分钟时段的样本计数统计数据。该计数应等于活动实例的数量。以下屏幕截图显示了 CloudWatch 控制台中的CPUUtilization指标图,其中统计数据设置为Sample count,期间设置为1 minute,得到的计数为 5。
下表按框架类型概述了 SageMaker AI 容器的常用可调整环境变量。
TensorFlow
| 环境变量 | 描述 |
|---|---|
|
|
对于基于 TensorFlow 的模型, |
|
|
此参数控制可用于初始化 CUDA/cuDNN 和其他 GPU 库的 GPU 内存的比例。 |
|
这可以追溯到 |
|
这可以追溯到 |
|
此项控制为处理请求,Gunicorn 根据请求生成的工作线程的数量。此值与其他参数结合使用,可以得出一个能够最大限度提高推理吞吐量的集合。除此之外, |
|
此项控制为处理请求,Gunicorn 根据请求生成的工作线程的数量。此值与其他参数结合使用,可以得出一个能够最大限度提高推理吞吐量的集合。除此之外, |
|
Python 在内部使用 OpenMP,以在进程中实施多线程。通常,生成的线程数与 CPU 核心数相等。但是,当在 Intel 的 HypeThreading 等同步多线程 (SMT) 之上实施时,由于生成的线程数是实际 CPU 核心数量的两倍,特定进程可能会超额订阅特定核心。在某些情况下,Python 二进制文件最终生成的线程数量可能是可用处理器核心数的四倍。因此,如果您使用工作线程超额订阅了可用核心,则此参数的理想设置是 |
|
|
在某些情况下,如果 |
PyTorch
| 环境变量 | 描述 |
|---|---|
|
|
这是 TorchServe 等待接收批次的最大批次延迟时间。 |
|
|
如果 TorchServe 在计时器走完之前,未收到在 |
|
|
允许 TorchServe 缩减到的最低工作线程数。 |
|
|
允许 TorchServe 纵向扩展到的最高工作线程数。 |
|
|
延迟的时间,超过该时间之后,如果没有响应,推理将超时。 |
|
|
TorchServe 的最大负载大小。 |
|
|
TorchServe 的最大响应大小。 |
多模型服务器 (MMS)
| 环境变量 | 描述 |
|---|---|
|
|
在您的场景中,如果推理请求类型的负载很大,并且由于负载的大小过大,维护该队列的 JVM 的堆内存使用量可能会过高时,此参数对于调整很有用。理想情况下,您希望将 JVM 的堆内存需求保持在较低的水平,并允许 Python 工作线程为实际模型服务分配更多内存。JVM 仅用于接收 HTTP 请求,对请求排队,然后将其分派给基于 Python 的工作线程进行推理。如果您增加 |
|
|
此参数用于后端模型服务,在用于调整时可能很有价值,因为这是整个模型服务的关键组件,Python 进程基于它为每个模型生成线程。如果此组件速度较慢(或调整不正确),则前端调整可能无效。 |
您可以将用于实时推理或批量转换的相同容器用于异步推理。您应确认已设置了容器上的超时和负载大小限制,用于处理更大的负载和更长的超时。
请参阅以下异步推理的限制:
负载大小限制:1 GB
超时限制:一个请求最多可以需要 60 分钟。
队列消息 TimeToLive (TTL):6 小时
可以放入 Amazon SQS 中的消息数量:无限制。但是,对于标准队列,未送达消息数的限额为 12 万,对于 FIFO 队列为 2 万。
通常,使用异步推理,您可以根据调用数或实例数横向扩展。对于调用指标,查看您的 ApproximateBacklogSize 是一种好的做法,该指标定义队列中尚未处理的项目数量。您可以利用这个指标或 InvocationsPerInstance 指标来了解您可能被限制的 TPS 是多少。在实例级别,检查您的实例类型及其 CPU/GPU 利用率,以定义何时横向扩展。如果单个实例的容量超过 60-70%,这通常是一个好的迹象,表明您充分利用了硬件。
我们不建议使用多个扩展策略,因为这些策略可能会在硬件层面发生冲突并导致混乱,从而导致横向扩展时出现延迟。
请检查您的容器是否能够同时处理 ping 和调用请求。SageMaker AI 调用请求大约需要 3 分钟,在这段时间内,通常多个 ping 请求最终会因为超时而失败,导致 SageMaker AI 检测到您的容器状态为 Unhealthy。
可以。MaxConcurrentInvocationsPerInstance 是异步端点的一项功能。这不依赖于自定义容器实施。MaxConcurrentInvocationsPerInstance 控制向客户容器发送调用请求的速率。如果将此值设置为 1,则无论客户容器上有多少个工作线程,一次只会向容器发送一个请求。
该错误意味着客户容器返回了错误。SageMaker AI 不会控制客户容器的行为。SageMaker AI 仅返回 ModelContainer 的响应,不会重试。如果需要,您可以配置调用以在失败时重试。我们建议您打开容器日志记录并检查容器日志,找出模型中出现 500 错误的根本原因。还应检查出现故障时的对应 MemoryUtilization 和 CPUUtilization 指标。您也可以在异步错误通知中,将 S3FailurePath 配置为 Amazon SNS 中的模型响应,以便调查故障。
您可以检查指标 InvocationsProcesssed,该指标应与您根据单次并发度,预计的一分钟内调用次数保持一致。
最佳实践是启用 Amazon SNS,这是一项是面向消息收发应用程序的通知服务,多个订阅用户可以选择通过多种传输协议(包括 HTTP、Amazon SQS 和电子邮件)请求和接收注重时效消息的“推送”通知。当您使用 CreateEndpointConfig 创建端点并指定 Amazon SNS 主题时,异步推理会发布通知。
要使用 Amazon SNS 检查异步端点的预测结果,您首先需要创建一个主题,订阅并确认订阅该主题,然后记下该主题的 Amazon 资源名称 (ARN)。有关如何创建、订阅和查找 Amazon SNS 主题的 Amazon ARN 的详细信息,请参阅《Amazon SNS 开发人员指南》中的配置 Amazon SNS。有关如何将 Amazon SNS 与异步推理结合使用的更多信息,请参阅查看预测结果。
是。异步推理提供了一种机制,可以在没有请求时缩减到零个实例。如果您的端点在这段时间内已缩减为零个实例,则直到队列中的请求数超过扩展策略中指定的目标时,您的端点才会再次纵向扩展。这可能会导致队列中请求的等待时间过长。对于这种情况,如果您想在新请求数低于所指定的队列目标时,从零个实例开始纵向扩展,您可以使用名为 HasBacklogWithoutCapacity 的额外扩展策略。有关如何定义此扩展策略的更多信息,请参阅自动缩放异步端点。
有关各个区域的异步推理所支持实例的详尽列表,请参阅 SageMaker 定价