本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
Autopilot 数据探索报告
Amazon SageMaker Autopilot 会自动清理和预处理您的数据集。 High-quality 数据提高了机器学习效率,并生成了能够做出更准确预测的模型。
客户提供的数据集中会存在的问题,如果没有某些领域知识的帮助,这些问题无法自动修复。例如,对于回归问题,目标列中的大异常值可能会导致对非异常值的预测不佳。根据建模目标,可能需要移除异常值。如果意外地将目标列作为输入特征之一,则最终模型的验证结果会很好,但对未来的预测几乎没有价值。
为了帮助客户发现这类问题,Autopilot 提供了数据探索报告,其中包含对其数据潜在问题的见解。报告还就如何处理这些问题提出了建议。
每个 Autopilot 作业都会生成包含报告的数据探索笔记本。报告存储在 Amazon S3 存储桶中,可以从输出路径访问。数据探索报告的路径通常采用以下模式。
[s3 output path]/[name of the automl job]/sagemaker-automl-candidates/[name of processing job used for data analysis]/notebooks/SageMaker AIAutopilotDataExplorationNotebook.ipynb
可以使用存储在中的DescribeAutoMLJob操作响应从 Autopilot API 中DataExplorationNotebookLocation获取数据探索笔记本的位置。
在 SageMaker Studio Classic 中运行 Autopilot 时,您可以使用以下步骤打开数据探索报告:
-
 从左侧导航窗格中选择 “主页” 图标以查看顶级 Amazon SageMaker Studio Classic 导航菜单。
从左侧导航窗格中选择 “主页” 图标以查看顶级 Amazon SageMaker Studio Classic 导航菜单。 -
从主工作区选择 AutoML 卡片。这将打开新的 Autopilot 选项卡。
-
在名称部分中,选择包含您要检查的数据探索笔记本的 Autopilot 作业。这将打开新的 Autopilot 作业选项卡。
-
在 Autopilot 作业选项卡的右上角选择打开数据探索笔记本。
数据探索报告在训练过程开始之前根据您的数据生成。通过该报告,您可以停止可能导致毫无意义结果的 Autopilot 作业。同样,在重新运行 Autopilot 之前,您可以解决数据集中的任何问题或进行改进。通过这种方法,您可以利用自己的领域专业知识来手动提高数据质量,然后再在精心策划的数据集上训练模型。
数据报告只包含静态 Markdown,可以在任何 Jupyter 环境中打开。包含报告的笔记本可以转换为其他格式,例如 PDF 或 HTML。有关转换的更多信息,请参阅使用 nbconvert 脚本将 Jupyter 笔记本转换为其他格式
数据集摘要
此数据集摘要提供了描述数据集特征的关键统计数据,包括行数、列数、重复行百分比和缺失目标值。它旨在在 Amazon A SageMaker utopilot 检测到您的数据集存在问题并且可能需要您干预时,向您发出快速警报。这些见解以警告的形式提供,并按照严重性“高”还是“低”分类。该分类取决于问题将对模型性能产生不利影响的置信度。
高严重性和低严重性见解以弹出窗口的形式出现在摘要中。在大多数见解中给出了建议,说明如何确认数据集存在的需要您注意的问题。另外还就如何解决这些问题提出了建议。
Autopilot 提供了有关我们数据集中缺失或无效目标值的其他统计数据,以帮助您检测高严重性见解可能没有捕获的其他问题。此外,某个特定类型的列具有意外的数量,可能表明数据集中缺少某些您希望使用的列。这也可能表明数据的准备或存储方式存在问题。修复 Autopilot 提请您注意的这些数据问题,可以改进在您的数据上进行训练的机器学习模型的性能。
高严重性见解显示在摘要部分以及报告中的其他相关部分中。高严重性和低严重性见解的示例通常会根据数据报告的具体部分给出。
目标分析
此部分显示了各种高严重性和低严重性见解,它们与目标列中值的分布相关。检查目标列是否包含正确的值。目标列中不正确的值可能会导致机器学习模型无法达到预期的业务目标。本节介绍了几个高严重性和低严重性的数据见解。下面是几个示例。
-
异常目标值 – 回归的目标分布偏斜或不寻常,例如重尾目标。
-
低或高的目标基数 – 不频繁的类标签数量或大量的唯一类用于分类。
对于回归和分类问题类型,将会显示无效值(如数字无穷大)、NaN 或者目标列中的空白空间。根据问题类型,会显示不同的数据集统计信息。对于回归问题,您可以通过目标列值的分布来验证分布是否符合预期值。
以下屏幕截图显示了 Autopilot 数据报告,其中包括数据集中的平均值、中位数、最小值、最大值、异常值百分比等统计数据。屏幕截图还包括一个直方图,显示了目标列中标签的分布。直方图在水平轴上显示目标列值,在垂直轴上显示计数。屏幕截图中的方框突出显示了异常值百分比部分,以指示此统计数据的显示位置。
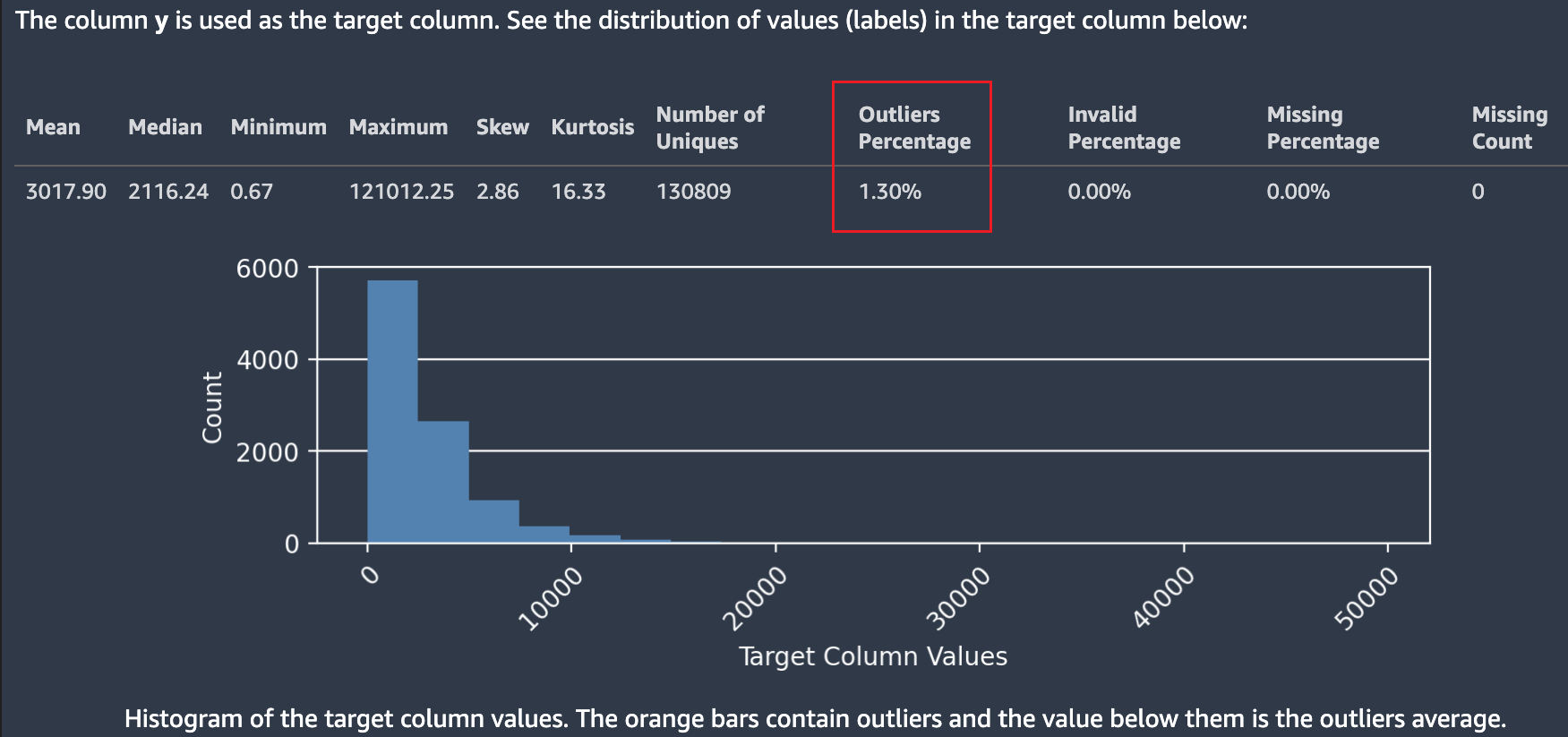
图中显示有关目标值及其分布的多个统计数据。如果任何异常值、无效值或缺失百分比大于零,则会显示这些值,以便您调查数据包含不可用的目标值的原因。一些不可用的目标值会突出显示为低严重性见解警告。
在下面的示例中,` 符号被意外添加到目标列中,这使得目标中的数字值无法解析。此时显示低严重性:“目标值无效”警告。此示例中的警告指出“目标列中 0.14% 的标签无法转换为数值。最常见的非数字值包括:[“-3.8e-05”、“-9-05”、“-4.7e-05”、“-1.4999999999999999e-05”、“-4.3e-05”]。这通常表明数据收集或处理存在问题。Amazon SageMaker Autopilot 会忽略所有带有无效目标标签的观察结果。”

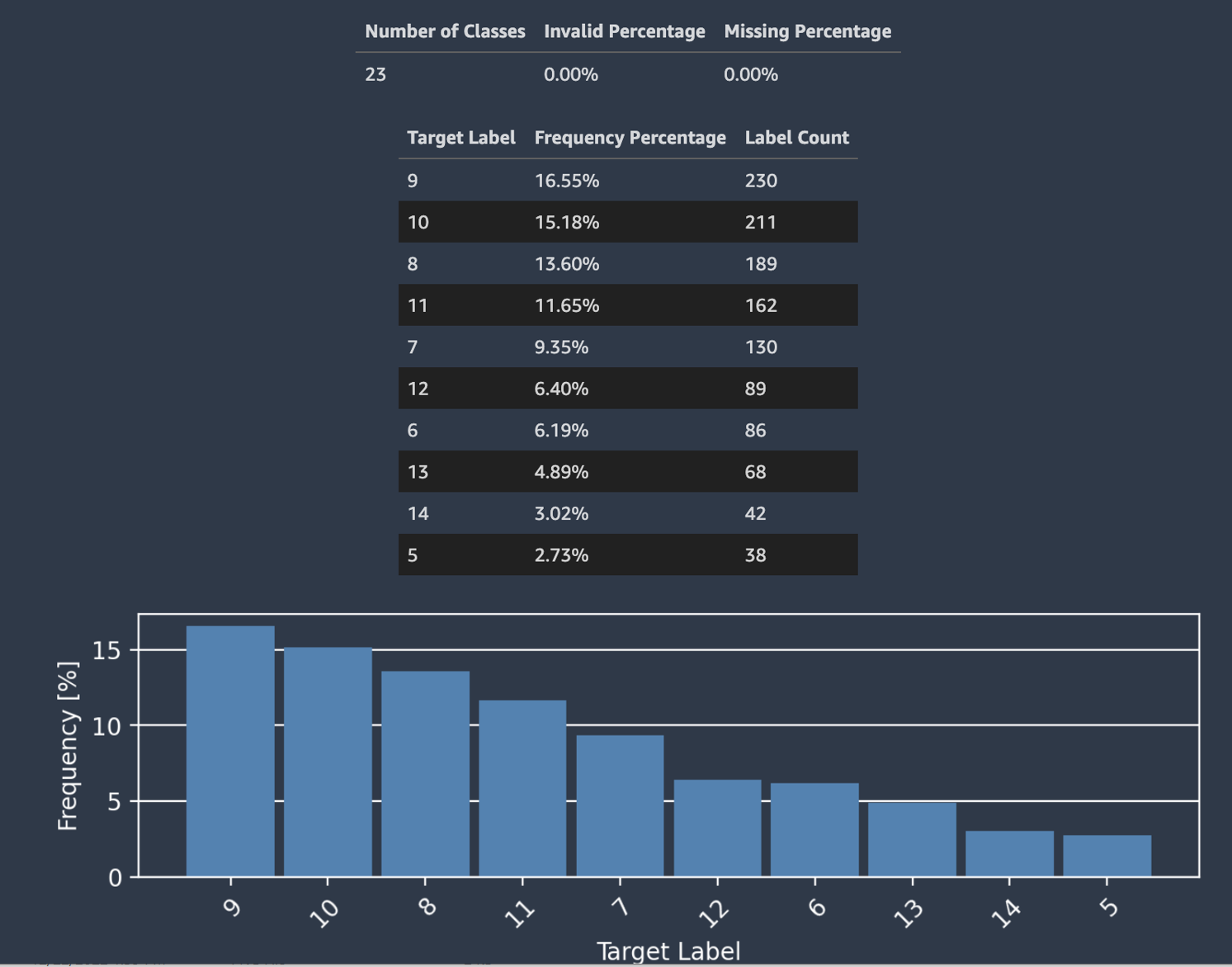
Autopilot 还提供直方图,显示用于分类的标签的分布。
以下屏幕截图显示了为目标列提供的统计信息示例,包括类数、缺失值或无效值。显示每个标签类别的分布的直方图,水平轴为目标标签,垂直轴为频率。
注意
在报告笔记本底部的定义中,您可以找到此节以及其他章节中出现的所有数据的定义。
数据示例
Autopilot 会提供您的数据的实际样本,以帮助您发现数据集存在的问题。样本表水平滚动。检查样本数据,以验证数据集中是否存在所有必需的列。
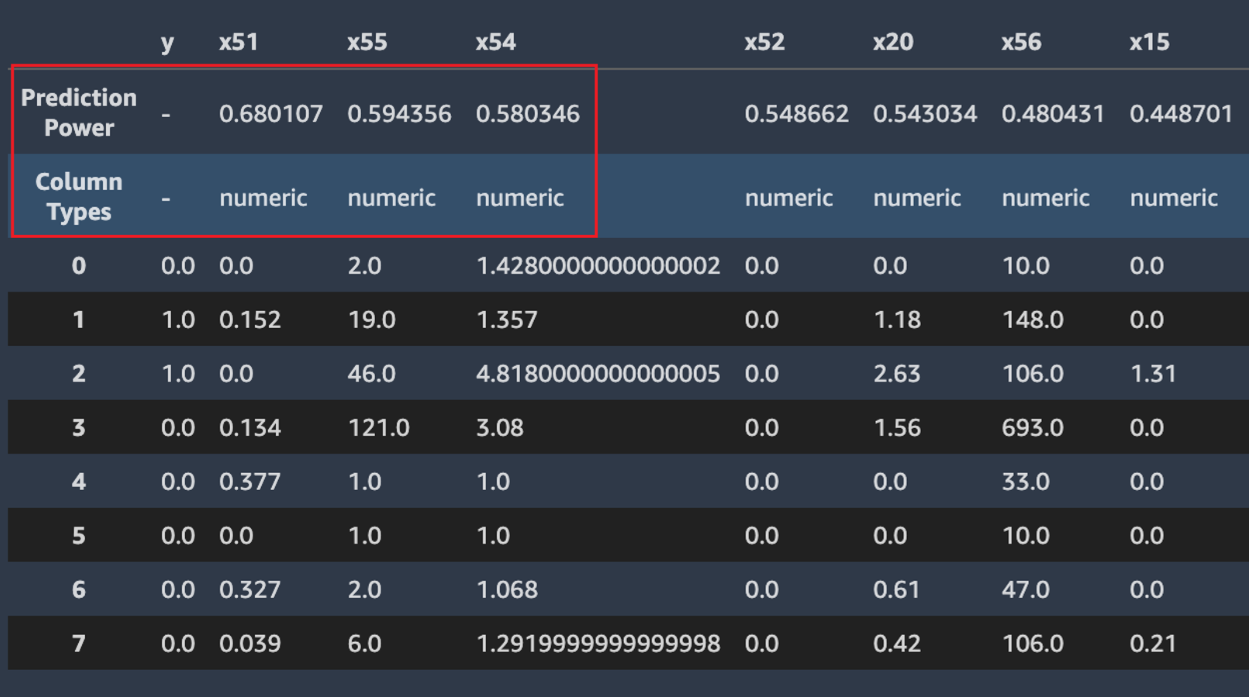
Autopilot 还计算预测能力的度量,可用于识别特征与目标变量之间的线性或非线性关系。值为 0 表示该特征在预测目标变量时没有预测值。值为 1 表示对目标变量具有最高预测能力。有关预测能力的更多信息,请参阅定义部分。
注意
不建议使用预测能力来代替特征重要性。只有当您确定预测能力是适合您的使用场景的度量时,才使用预测能力。
以下屏幕截图显示数据样本示例。最顶部的一行包含数据集中每列的预测能力。第二行包含列数据类型。随后的行包含标签。其中的列包含目标列,后面是各个特征列。每个特征列都有一个关联的预测能力,在此屏幕截图中以方框突出显示。在此示例中,包含特征 x51 的列对目标变量 y 的预测能力为 0.68。对特征 x55 的预测能力稍差,预测能力为 0.59。
重复行
如果数据集中存在重复行,Amazon A SageMaker utopilot 会显示其中的一个样本。
注意
不建议在将数据集提供给 Autopilot 之前,通过向上取样来平衡数据集。这可能会导致 Autopilot 训练的模型的验证分数不准确,并且生成的模型可能无法使用。
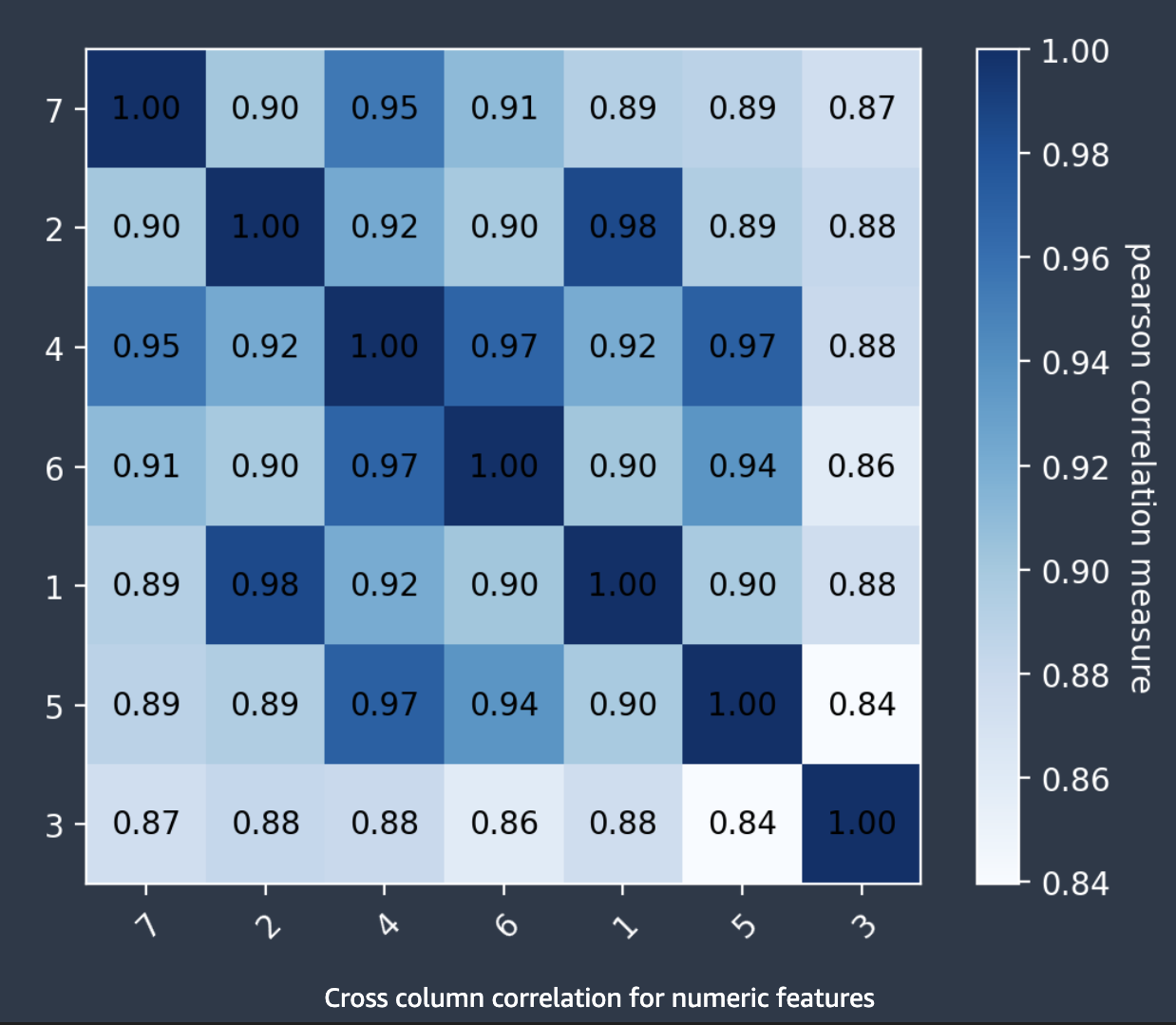
跨列相关性
Autopilot 使用 Pearson 相关系数(衡量两个特征之间线性相关性的指标)来填充相关矩阵。在相关矩阵中,在水平轴和垂直轴上绘制数字特征,Pearson 相关系数绘制在它们的交点处。两个特征之间的相关性越高,系数也越高,最大值为 |1|。
-
值为
-1表示特征完全呈负相关。 -
当特征与其自身相关时,值为
1,表示完全正相关。
您可以使用相关矩阵中的信息来移除高度相关的特征。较少数量的特征减少了模型过度拟合的可能性,并可以通过两种方式降低生产成本。它减少了所需的 Autopilot 运行时间,并且对于某些应用程序来说,可以降低数据收集过程的成本。
以下屏幕截图展示了有 7 个特征的相关矩阵示例。每个特征都以矩阵形式显示在水平轴和垂直轴上。Pearson 的相关系数显示在两个特征之间的交点处。每个特征交点都有与之相关的色调。相关性越高,色调越暗。最暗的色调占据了矩阵的对角线,此处每个特征都与其自身相关,代表着完全相关。
异常行
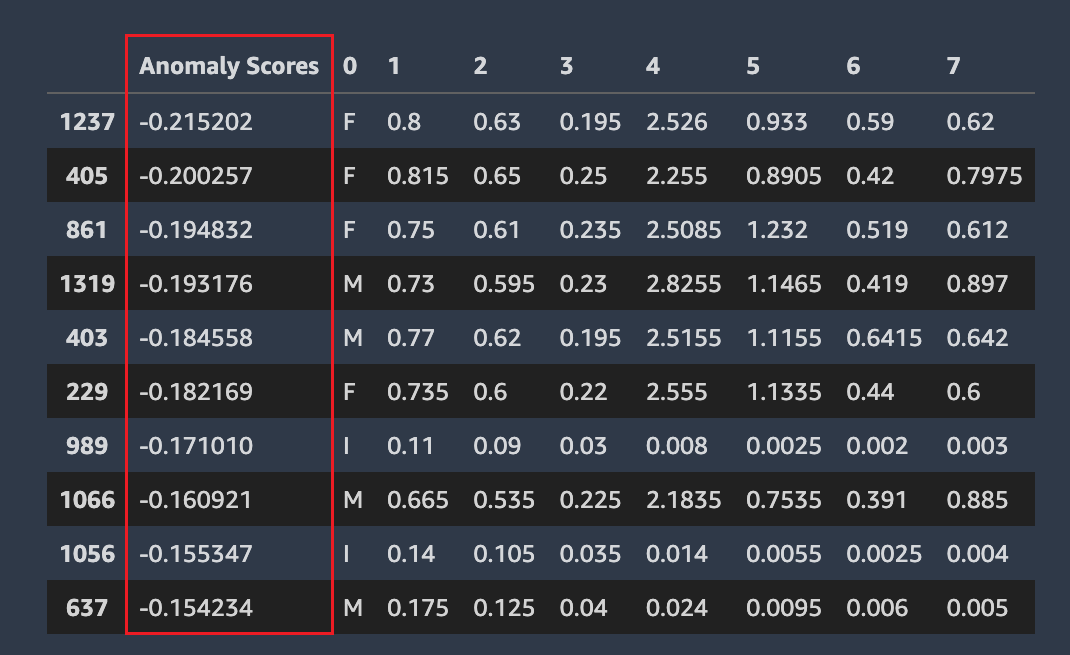
Amazon SageMaker Autopilot 会检测您的数据集中哪些行可能存在异常。然后,它为每行分配一个异常分数。具有负异常分数的行被视为异常。
以下屏幕截图显示了 Autopilot 分析对包含异常分数的行的输出。包含异常分数的列出现在每行的数据集列旁边。
缺失值、基数和描述性统计数据
Amazon SageMaker Autopilot 会检查并报告数据集中各个列的属性。在数据报告呈现此分析的每个部分中,内容按顺序排列。这样您就可以先检查最“可疑”的值。使用这些统计数据,您可以改进单个列的内容,从而进一步提高 Autopilot 生成的模型的质量。
Autopilot 在包含分类值的列中计算分类值的几个统计数据。这包括唯一条目的数量,对于文本是唯一单词的数量。
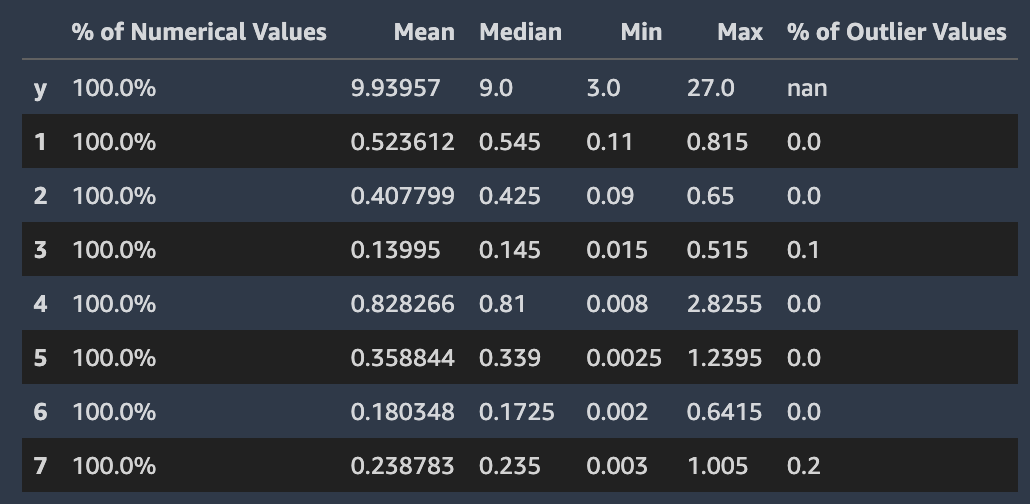
Autopilot 在包含数字值的列中计算数字值的几个标准统计数据。下图描绘了这些统计数据,包括平均值、中值、最小值和最大值,以及数值类型百分比和异常值的百分比。