本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
在分析中使用高级指标
以下部分介绍如何在 Amazon C SageMaker anvas 中查找和解释您的模型的高级指标。
注意
高级指标目前仅适用于数字和分类预测模型。
要找到高级指标选项卡,执行以下操作:
-
打开 SageMaker 画布应用程序。
-
在左侧导航窗格中,选择我的模型。
-
选择您构建的模型。
-
在顶部导航窗格中,选择分析选项卡。
-
在分析选项卡中,选择高级指标选项卡。
在高级指标选项卡中,您可以找到性能选项卡。页面类似以下界面截图。
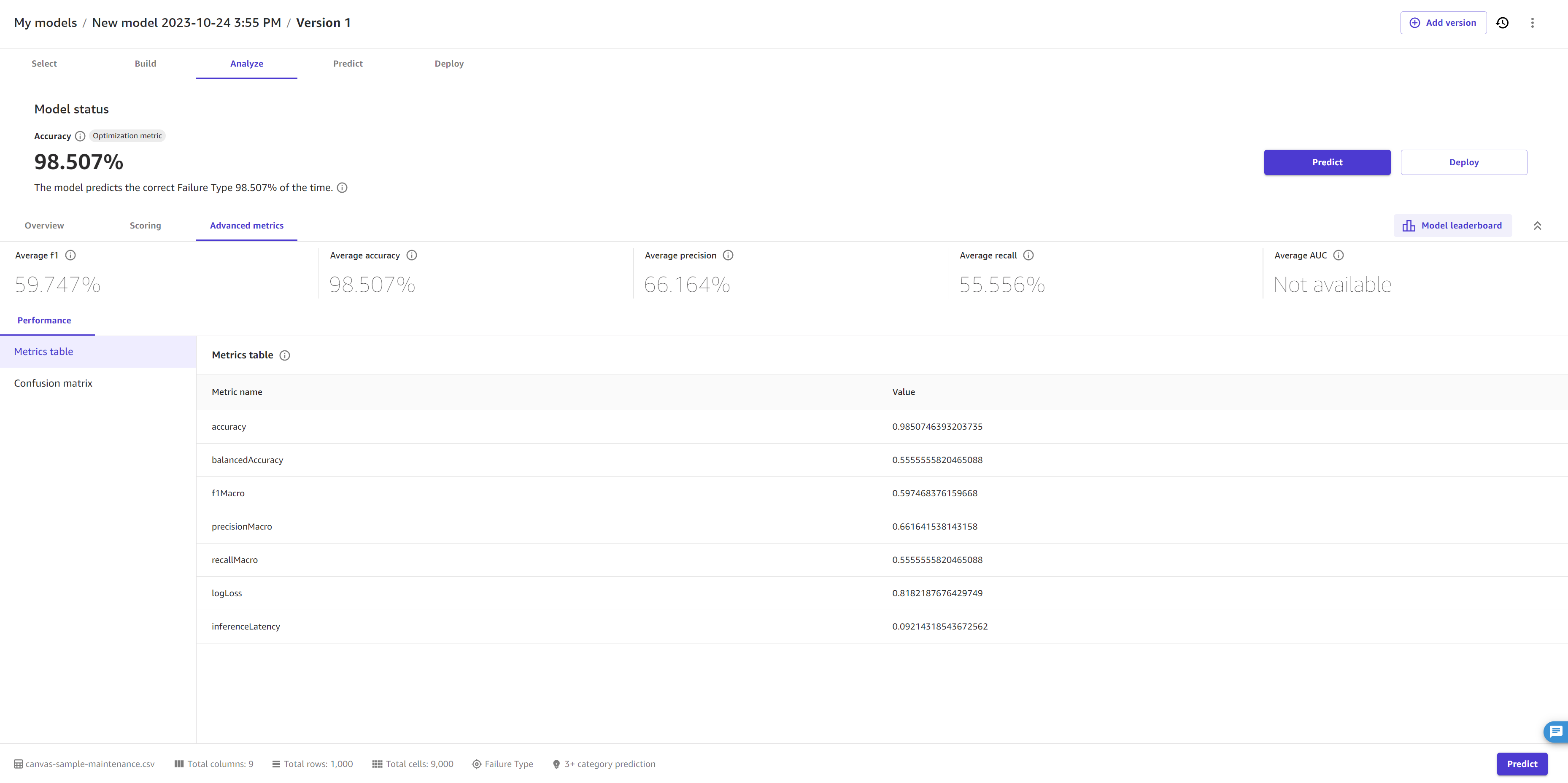
在顶部,您可以看到指标分数的概述,包括优化指标,这是您在构建模型时选择(或默认选择 Canvas)进行优化的指标。
下面的部分将介绍高级指标中性能选项卡的更多详细信息。
性能
在性能选项卡中,您将看到一个指标表格,以及 Canvas 根据模型类型创建的可视化效果。对于分类预测模型,Canvas 提供了混淆矩阵,而对于数值预测模型,Canvas 则提供了残差和误差密度图表。
在指标表中,您会看到每个高级指标的模型分数的完整列表,此列表比页面顶部的分数概述更加全面。此处显示的指标取决于您的模型类型。有关帮助您理解和解释每个指标的参考资料,请参阅 指标参考。
要了解根据模型类型可能出现的可视化效果,请参阅以下选项:
-
混淆矩阵:Canvas 使用混淆矩阵来帮助您直观地了解模型何时做出正确预测。在混淆矩阵中,您的结果将用于比较预测值和实际值。下面的示例解释了混淆矩阵如何用于预测正标签和负标签的 2 类别预测模型:
-
真正 - 当真标签为正时,模型正确地预测了正。
-
真负 - 当真标签为负时,模型正确地预测了负。
-
假正 - 当真标签为负时,模型错误地预测了正。
-
假负 - 当真标签为正时,模型错误地预测了负。
-
-
精度查全率曲线:精度查全率曲线是根据模型的查全率分数绘制的模型精度分数的可视化。通常,能够做出完美预测的模型,其精度和查全率分数都是 1。准确性相当高的模型的精度查准率曲线在精度和查全率方面都相当高。
-
残差:残差是实际值与模型预测值之间的差值。残差图将残差与相应的值进行对比,以直观显示其分布情况以及任何规律或异常值。残差在零附近的正态分布表明此模型与数据拟合良好。但是,如果残差明显偏斜或存在异常值,则可能表明模型过度拟合数据或有其他问题需要解决。
-
误差密度:误差密度图表示模型所产生的误差的分布。它显示了每个点的误差概率密度,帮助您识别模型可能过度拟合或出现系统误差的任何区域。