本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
对文本数据进行预测
以下过程介绍如何对文本数据集进行单一预测和批量预测。每个 Ready-to-use模型都支持您的数据集的单一预测和批量预测。单一预测是指您只需进行一次预测。例如,您有一张图像要从中提取文本,或者有一段文本要检测其主要语言。批量预测是指您想对整个数据集进行预测。例如,您可能有一个包含客户评论的 CSV 文件,您想分析其中的客户情绪,或者您可能有想要在其中检测对象的图像文件。
您可以将这些过程用于以下 Ready-to-use模型类型:情感分析、实体提取、语言检测和个人信息检测。
注意
对于情绪分析,您只能使用英语文本。
单一预测
要对接受文本数据的 Ready-to-use模型进行单一预测,请执行以下操作:
-
在 Canvas 应用程序的左侧导航窗格中,选择 R eady-to-use 模型。
-
在Ready-to-use 模型页面上,为您的用例选择 Ready-to-use模型。对于文本数据,应该是以下模型之一:情绪分析、实体提取、语言检测或个人信息检测。
-
在所选 Ready-to-use模型的运行预测页面上,选择单一预测。
-
在文本字段中,输入您要预测的文本。
-
选择生成预测结果以获取您的预测结果。
在右侧窗格的预测结果中,除了每个结果或标签的置信度分数外,您还会收到对文本的分析。例如,如果您选择语言检测并输入一段法语文本,则法语的置信度分数可能为 95%,而其他语言(例如英语)的置信度分数为 5%。
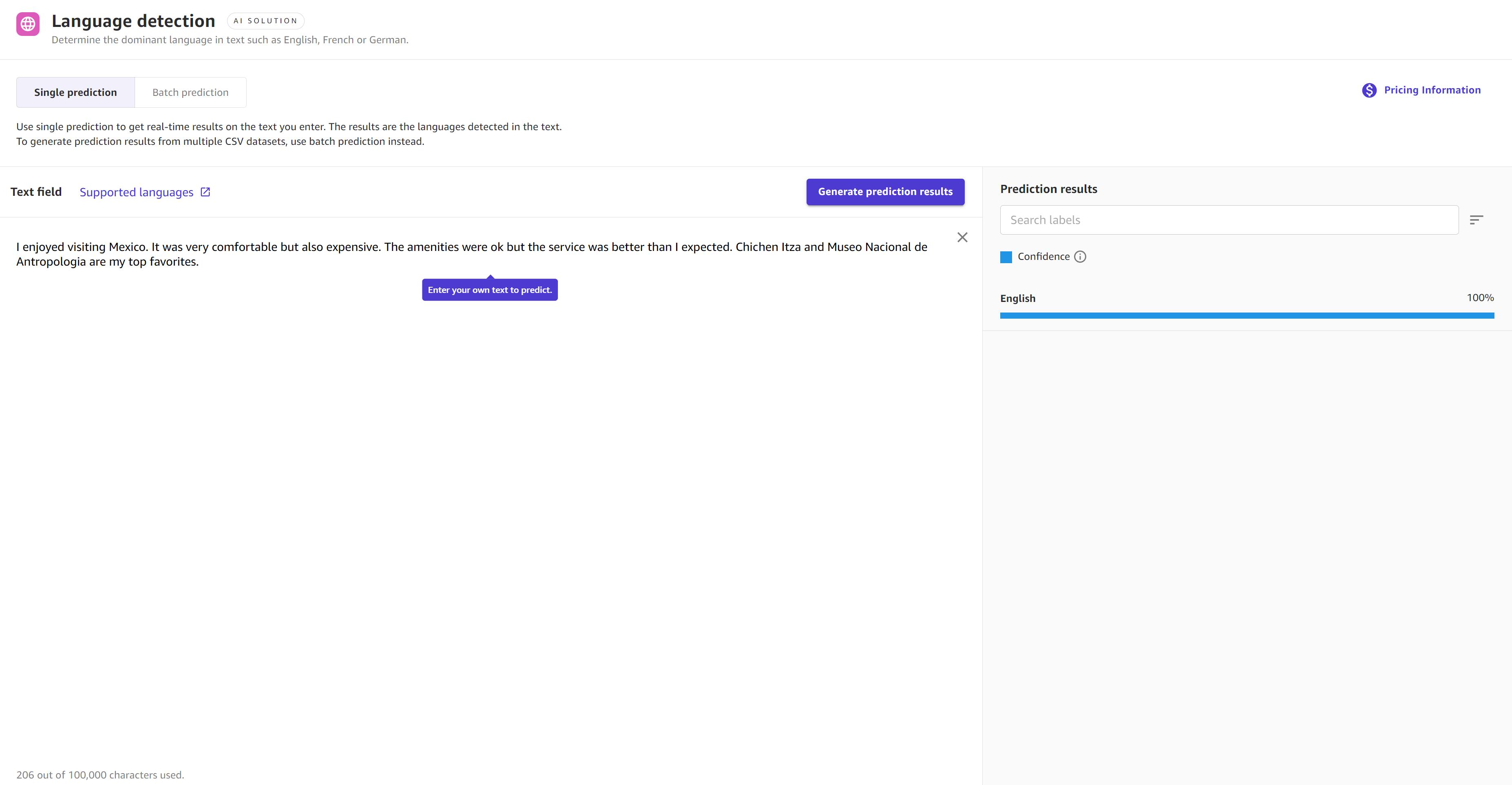
以下屏幕截图显示了使用语言检测进行单一预测的结果,其中模型 100% 确信段落是英语。
批量预测
要对接受文本数据的 Ready-to-use模型进行批量预测,请执行以下操作:
-
在 Canvas 应用程序的左侧导航窗格中,选择 R eady-to-use 模型。
-
在Ready-to-use 模型页面上,为您的用例选择 Ready-to-use模型。对于文本数据,应该是以下模型之一:情绪分析、实体提取、语言检测或个人信息检测。
-
在所选 Ready-to-use模型的 “运行预测” 页面上,选择 Batch 预测。
-
如果您已经导入了数据集,请选定选择数据集。如果未导入,请选择导入新数据集,然后将引导您完成导入数据工作流。
-
从可用数据集列表中,选择您的数据集并选择生成预测以获取预测。
预测作业运行完毕后,在运行预测页面上,您会看到预测下列出了输出数据集。此数据集包含您的结果,如果您选择更多选项图标 (
![]() ),则可以预览输出数据。然后,您可以选择下载来下载结果。
),则可以预览输出数据。然后,您可以选择下载来下载结果。